我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


学习
H100 GPU 市场指南
H100 GPU 的市场价格在短期内会维持,但随着时间推移会下降。租赁条件变得更灵活,租赁时长缩短。对小型集群(16-512 GPUs)来说,6 个月租期价格约为 $2.60/h,12 个月为 $2.40/h,长期租赁低于 $2.20/h。大型集群的价格波动较大,租赁和购买成本逐渐趋于平稳,市场预计 H100 GPU 的供需会逐步改善。
对于 H100 GPU 的选择,租赁更具灵活性和成本效益,特别是随着 GPU 市场价格的持续下降。此外,租赁避免了前期巨大的资本投入,并允许用户根据需求灵活调整计算资源规模。购买虽然提供了数据安全和长期稳定性,但建设和维护集群的成本较高,且运营复杂。
-
GPU 服务器:Nvidia H100 HGX 系统支持 Dell、Supermicro 等厂商的产品,配置通常为 2TB 内存、40TB NVMe 存储和高性能网络(如 InfiniBand 或 RoCE)。
-
网络:InfiniBand 和 RoCE 提供低延迟的高带宽互连,适合分布式训练任务。InfiniBand 更加成熟,而 RoCE 则具备更好的扩展性。
-
存储:本地 NVMe 存储至少需要 20TB,以支持高效的 AI 训练与推理任务。
-
电源及维护:每张 H100 GPU 消耗约 800 瓦,计算硬件和网络硬件的整体运营成本约为 $1.7/h。
GPU 的故障率高于传统 CPU 系统。Lepton 提供了 GPUd 工具,用于对 GPU 进行主动监控和故障诊断,确保集群运行的可靠性并减少停机时间。
 https://blog.lepton.ai/the-missing-guide-to-the-h100-gpu-market-91ebfed34516?gi=f6b69c41c288
https://blog.lepton.ai/the-missing-guide-to-the-h100-gpu-market-91ebfed34516?gi=f6b69c41c288
Andy Barto 关于强化学习的历史演讲总结
在#RLC2024会议上,Andy Barto 的演讲强调了强化学习(RL)和机器学习(ML)历史中的深刻跨学科影响。他将强化学习定义为“广义情境搜索”,结合了搜索(试错)与记忆(缓存解决方案)。他回顾了RL的智力渊源,包括与Richard Sutton的关键合作,以及来自密歇根大学计算机逻辑小组和阿默斯特系统神经科学中心的影响。
Barto 将RL 与 Klopf 的突触可塑性法则联系起来,解释了突触如何根据奖励或惩罚调整权重。他区分了两种突触资格:依赖于突触前后活动的“条件资格”(形成三因子学习规则)和仅依赖突触前活动的“非条件资格”(形成两因子规则)。
在历史上,ML的里程碑包括Sutton和Barto在1981年关于期望和预测的自适应网络的工作,该工作受到心理学和神经生物学理论的启发。Barto 还讨论了早期的机器学习尝试,如托马斯·罗斯1933年的思考机器,格雷·沃尔特的 Machina Speculatrix,以及诸如法利和克拉克1954年ANN模拟、明斯基的神经网络以及罗森布拉特1958年感知器等AI的奠基性发展。
Barto 强调了RL的跨学科性质,像时间差分学习这样的技术来自心理学的灵感。他重温了演员-评论家架构,其中演员学习策略,而评论家将奖励转化为时间差分错误用于学习。此外,他探讨了多巴胺在RL中的作用,特别是舒尔茨、Dayan 和Montague 1997年提出的奖励预测误差理论。
Barto 在演讲结尾提醒设计奖励系统时需谨慎,引用了诺伯特·维纳的“猴爪”类比,强调了奖励设计不当可能带来的意外后果。他对RL发展史的反思赢得了全场起立鼓掌,凸显了跨学科合作在推动AI进步中的重要性。
 https://threadreaderapp.com/thread/1831016053503135831.html
https://threadreaderapp.com/thread/1831016053503135831.html
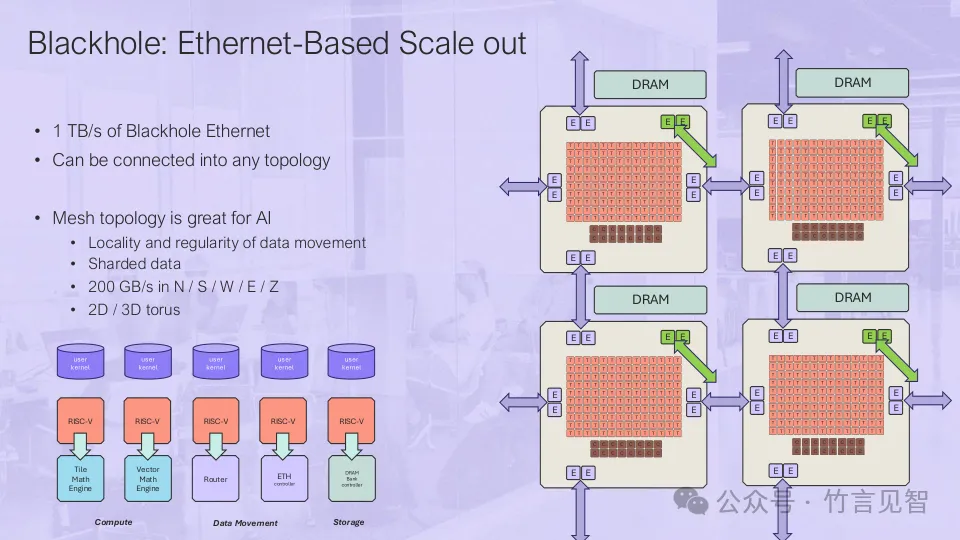
HotChips2024,处理器单元-Blackhole
Enstorrent(TT)在HotChips2024上展示了其新一代Blackhole(BH)芯片,强调其在纯计算和扩展性方面超越了Nvidia的A100。BH芯片采用台积电6nm工艺、600mm²大芯片尺寸,使用RISC-V架构,针对AI任务提供高性能和低功耗优化。其核心特点包括:745TOPS的FP8性能、10个400G以太网互联、Tensix Core架构、752个”Baby RISC-V”核,以及16个支持Linux的RISC-V CPU核。BH芯片基于以太网的独立AI计算,采用2D Torus互联模式,支持各种AI数据模式。它的scale-out设计在Galaxy节点中可以提供23.8 petaFLOPS的FP8性能,显著超过Nvidia的HGX/DGX A100系统。此外,TT还展示了配套的软件栈,如TT-Metal、TT-budda等,支持主流AI框架的无缝集成,允许开发者灵活使用自定义操作符和硬件布局。BH芯片在AI计算领域具有显著的扩展性和性能优势。
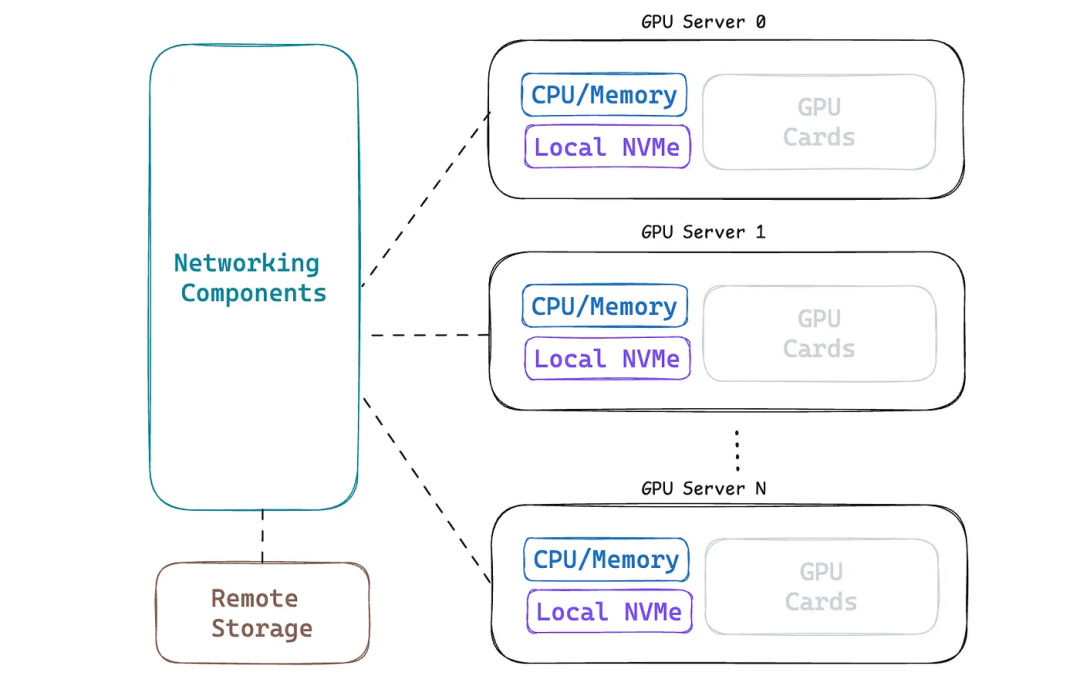
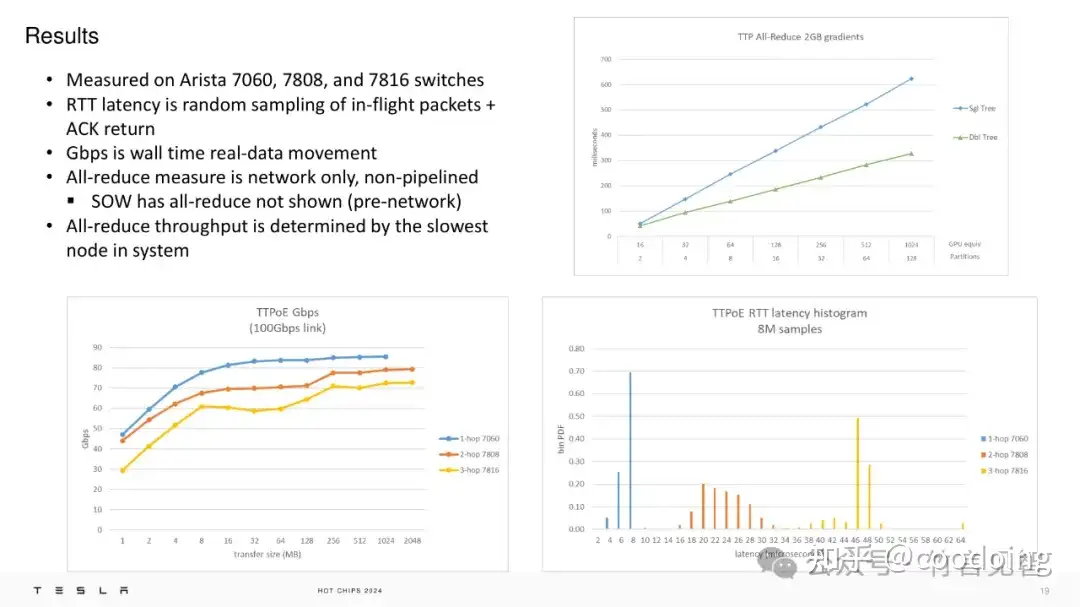
HotChips2024,Tesla TTPoE
在HC2024大会上,Tesla分享了其自研的以太网传输协议TTPoE。Tesla并未采用传统的InfiniBand网络解决方案,而是通过修改传输层协议以利用以太网特性,满足AI训练需求。相比TCP/IP和基于以太网的RDMA方案,TTPoE旨在解决传统网络的延迟高、吞吐量限制以及复杂性的不足。
传统TCP/IP协议在AI训练中由于ACK重传机制导致时延较高,且拥塞控制限制了吞吐量。RDMA通过无损网络和PFC实现,但可能导致头部阻塞和PFC风暴,同时增加了硬件成本和配置复杂度。业界也尝试了ECN拥塞通知和DCQCN动态拥塞控制等改进方案,但Tesla认为理想的网络应具备低延迟、高带宽和实现简单的特点。因此,Tesla选择开发TTPoE这一基于以太网的点对点传输协议,支持lossy网络,通过硬件实现低延迟和高带宽。
TTPoE协议仅使用以太网Layer2,通过硬件处理所有传输操作,减少了TCP复杂的握手和挥手流程,支持微秒级延迟。同时,它采用简单的拥塞控制和有损传输机制,与传统的TCP拥塞窗口不同,TTPoE通过硬件中的SRAM缓冲区跟踪数据,使用滑动窗口机制来处理丢包和拥塞问题。
Tesla还在其Mojo网卡上实现了TTP协议,该网卡支持100G传输,结合PCIe3和DDR4技术,平衡了性能和成本。TTPoE允许与TCP/IP协议共存,并最终将向外界开放。
 https://zhuanlan.zhihu.com/p/718323107?utm_psn=1814980987202973697
https://zhuanlan.zhihu.com/p/718323107?utm_psn=1814980987202973697
HotChips 2024 CPU session总结
-
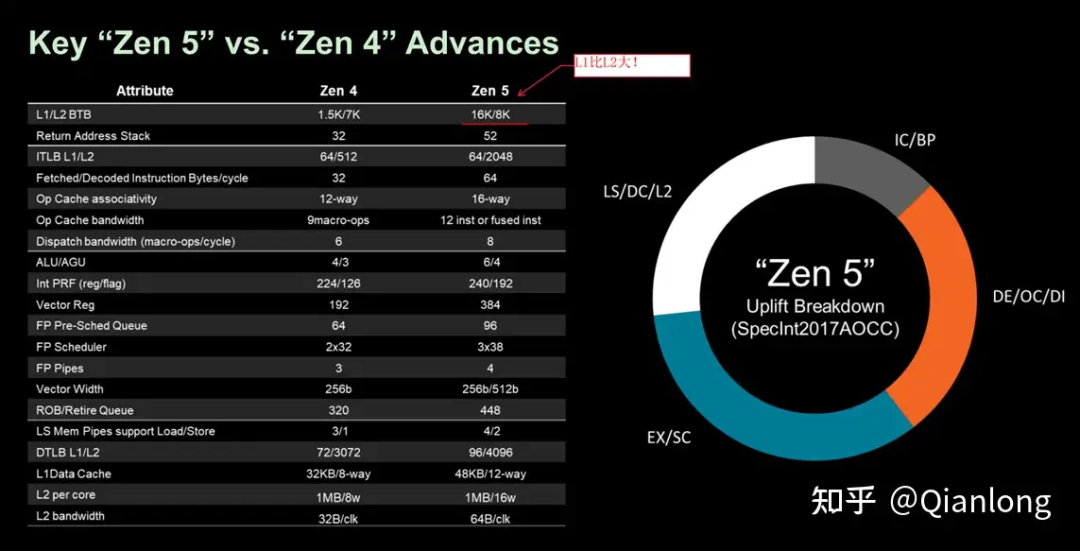
AMD Zen5
-
基本信息:Zen5采用TSMC 4/3nm工艺,频率为5.85GHz。
-
前端设计亮点:支持2个taken分支预测,8宽解码(4×2),支持SMT模式下每线程独享一条前端流水线,Op Cache中存储的是fused inst,提供更高指令吞吐率。
-
执行部件:ALU部分增加了调度队列,改进了吞吐能力,FPU的处理宽度由256b升级为512b,内存子系统支持最多4个load和2个store,L1D支持12路联想,L2缓存带宽加倍。
-
内存改进:L3缓存改进了延迟,增加了mshr容量;L2和L1的接口带宽达到了64B/cycle。
-
高通 Oryon
-
Oryon是全新开发的核心,主要面向PC、自动驾驶和智能终端,主频为4.3GHz。
-
前端设计:ICache与一致性协议域集成,译码宽度为8,分支预测惩罚周期为13。
-
执行部件:ROB支持压缩,支持多种并行执行单元,包含多条流水线。
-
内存子系统:L1 DCache为96KB,支持多达4个load或store的并行执行,预取器支持array和stride模式。
-
Intel Lunar Lake
 https://zhuanlan.zhihu.com/p/718144245?utm_psn=1814722667430961152
https://zhuanlan.zhihu.com/p/718144245?utm_psn=1814722667430961152
谈谈AI的泡沫
近期,关于AI泡沫的讨论越来越热烈,NVIDIA股价波动剧烈。支持者和反对者从长期预期和营收现状出发,展开了激烈争论。然而,双方都默认了一个核心假设:支撑大模型的计算机系统成本理应如此高昂,只是在讨论这些成本能否支持大规模商业化。
作者认为,AI大型机(高价GPU服务器)是问题的核心。正如IBM的大型机无法支撑PC产业和互联网的繁荣,AI大型机也难以支撑未来的大模型产业。真正能推动产业繁荣的是像x86体系那样的白盒化计算机系统,它降低了计算成本,促进了广泛的创新和商业化。
此外,作者强调成本的量变和质变。虽然今天的边际成本下降,但真正影响商业化的是当前AI应用无法摆脱ROI的算计,商业模式也不同于互联网的流量经济。AI大型机的高成本限制了应用创新,无法像互联网那样通过低成本吸引用户注意力。
最后,作者呼吁通过白盒化的计算机体系革命,降低AI硬件成本,使AI体验进入消费级市场。这种质变如果实现,AI将进入类似软件行业的超高速爆发期,推动大模型时代的到来。
https://zhuanlan.zhihu.com/p/718191220?utm_psn=1814930875663642624
Physics of Language Model 阅读笔记
当前的大型语言模型(LLM)虽然具备生成高分模型的能力,但这并不代表其掌握了数学或达到了通用人工智能(AGI)的水平。模型的成功更多依赖于复杂的语言结构学习与推理过程。
在语言结构方面,相对位置编码的效果优于绝对位置编码,旋转嵌入(rotary embedding)成为一种折衷选择。模型如GPT可以学习上下文无关文法的隐藏树结构,而BERT等模型却无法做到这一点。
在推理过程中,模型展示了复杂推理能力,例如通过逻辑依赖图训练,模型可以从15跳推理泛化到23跳推理。GPT模型的推理能力(level 1和level 2)通过拓扑排序和最短路径生成,表现出模型与人类推理的不同:模型会预先计算所有可能的依赖关系。错误推理则可通过多轮提示探测,并借助重试和回溯策略提升推理准确性。
在知识存储与操作方面,模型的知识主要存储在MLP层,提升模型的泛化性需要在预训练阶段进行知识增强,如多样性、翻译等。对于复杂的知识操作任务,需要引入COT(Chain of Thought)来完成分类、排序等任务。
LLM的扩展规律表明,充分训练后,模型可有效存储2bit/参数的信息,而训练不足会显著降低存储效率。Gated MLP增加了训练不稳定性,而适度的专家混合模型(MoE)则可以显著提升存储效率。
https://zhuanlan.zhihu.com/p/718097151?utm_psn=1814936032094846976
ESP-AI
ESP-AI 是一个基于 ESP 开发板的智能对话解决方案,具备语音唤醒、识别、理解和合成等功能,提供简单、低成本的智能对话接入。主要功能包括可自定义的离线唤醒词、完整的对话链路、快速响应算法、对话中断支持、命令识别、可配置性以及插件架构。
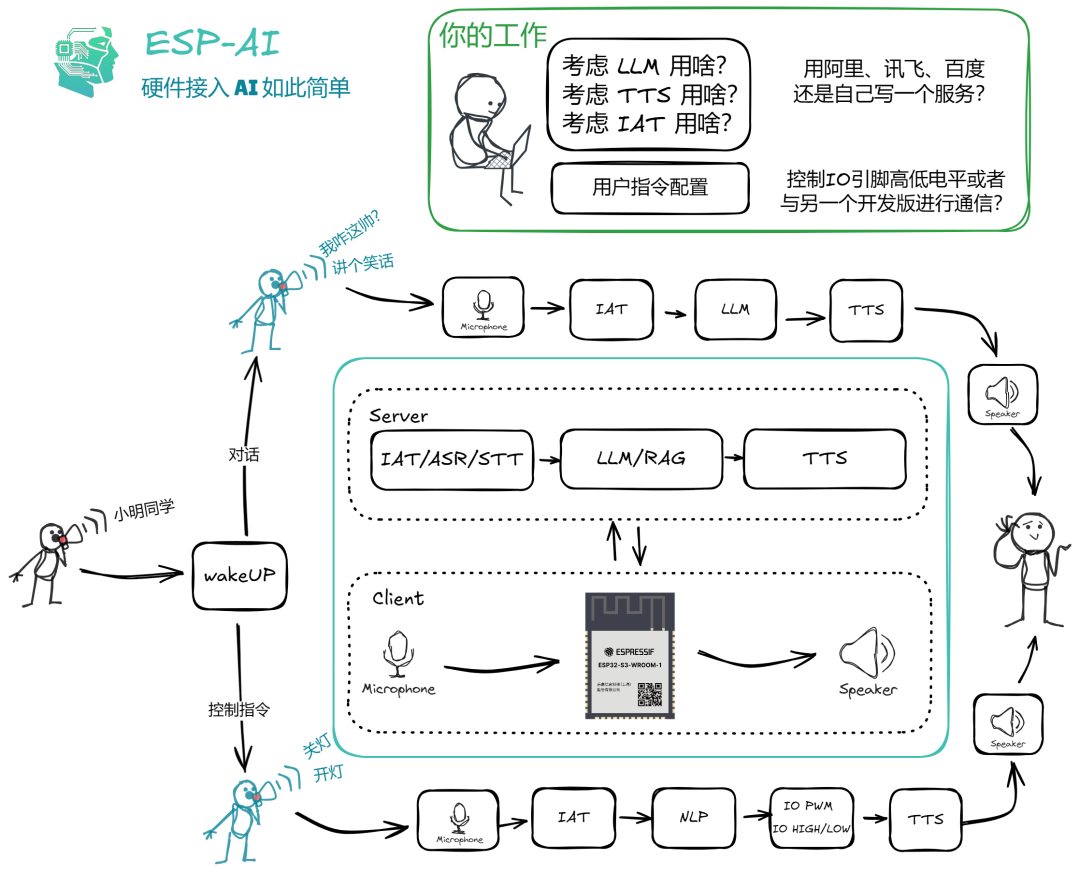 https://github.com/wangzongming/esp-ai
https://github.com/wangzongming/esp-ai
mirascope
Mirascope 是一个简单的 Python LLM 库,希望为软件工程师提供更好的开发体验。它通过一组核心语,使构建复杂应用程序变得轻松,并支持多种 LLM 提供商,如 OpenAI 和 Anthropic。主要功能包括将函数转换为 LLM 调用的 call 装饰器、异步调用、流式响应、工具调用、结构化输出,以及提供与提供商无关的 BasePrompt 基类。
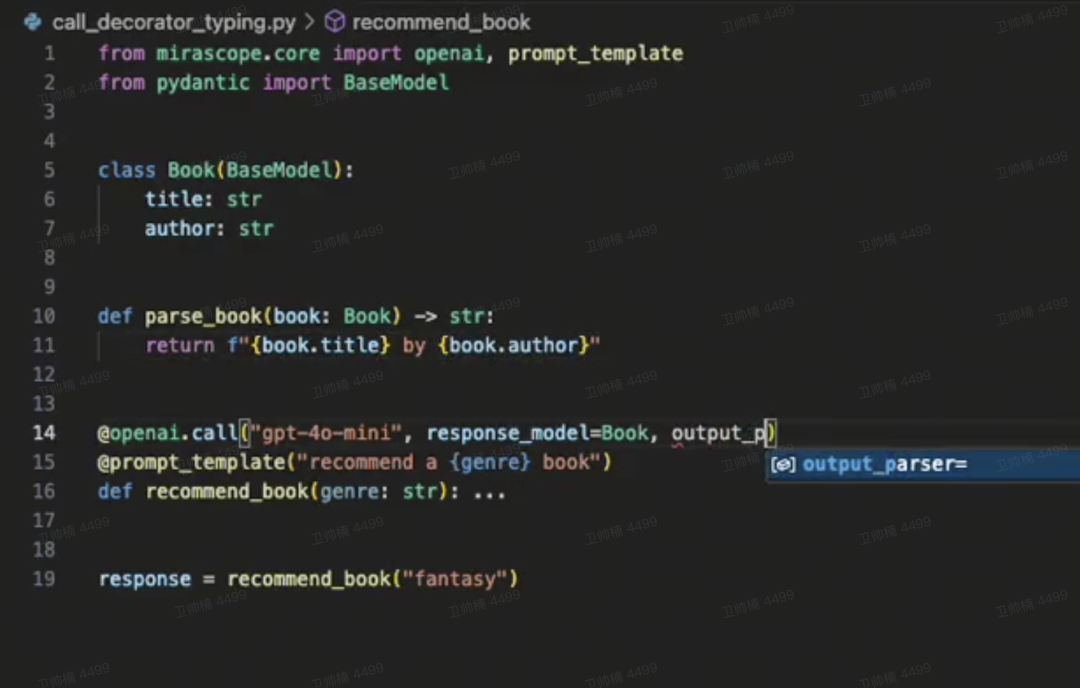 https://github.com/Mirascope/mirascope
https://github.com/Mirascope/mirascope
-
-
-
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/09/13121.html