
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
NDP:下一次分配预测作为更广泛的目标
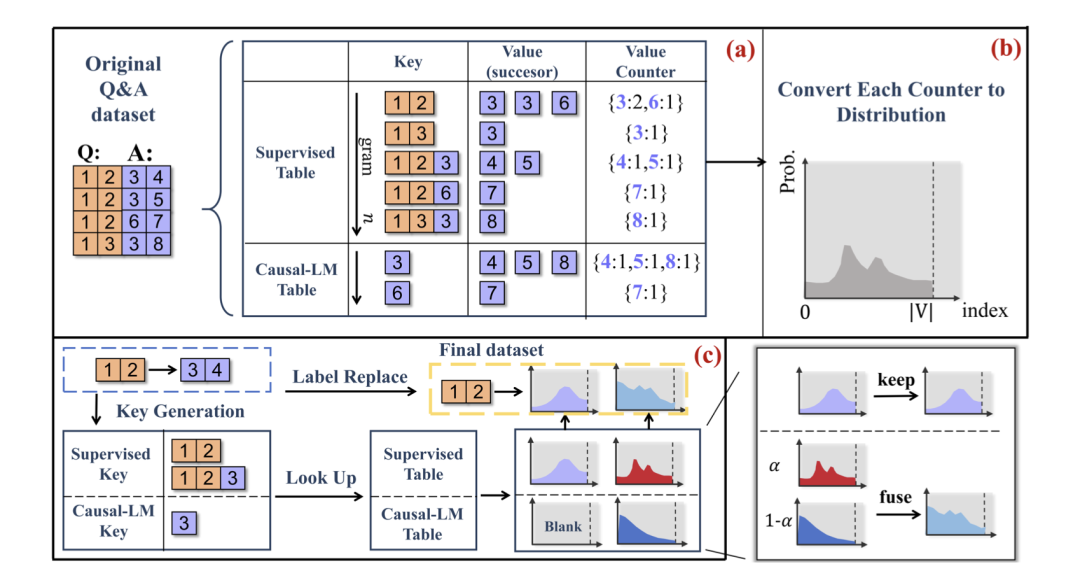
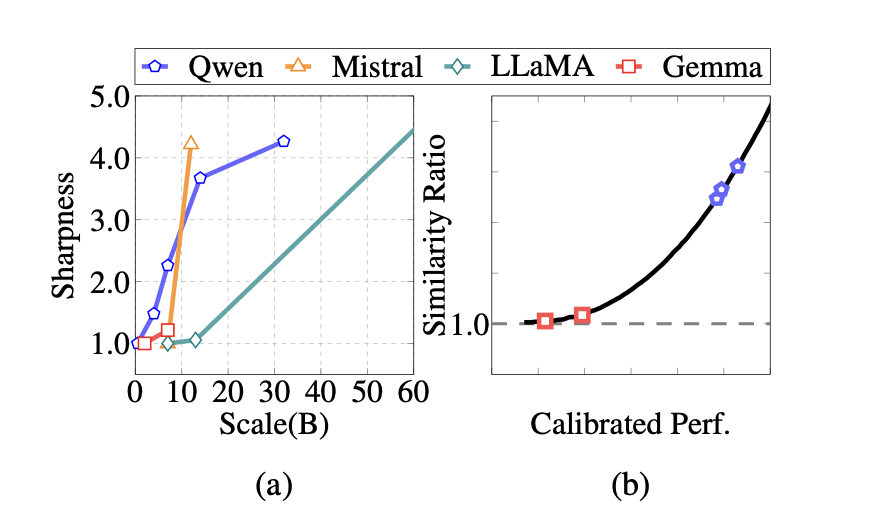 http://arxiv.org/abs/2408.17377v1
http://arxiv.org/abs/2408.17377v1MemLong: 用于长文本建模的记忆增强检索
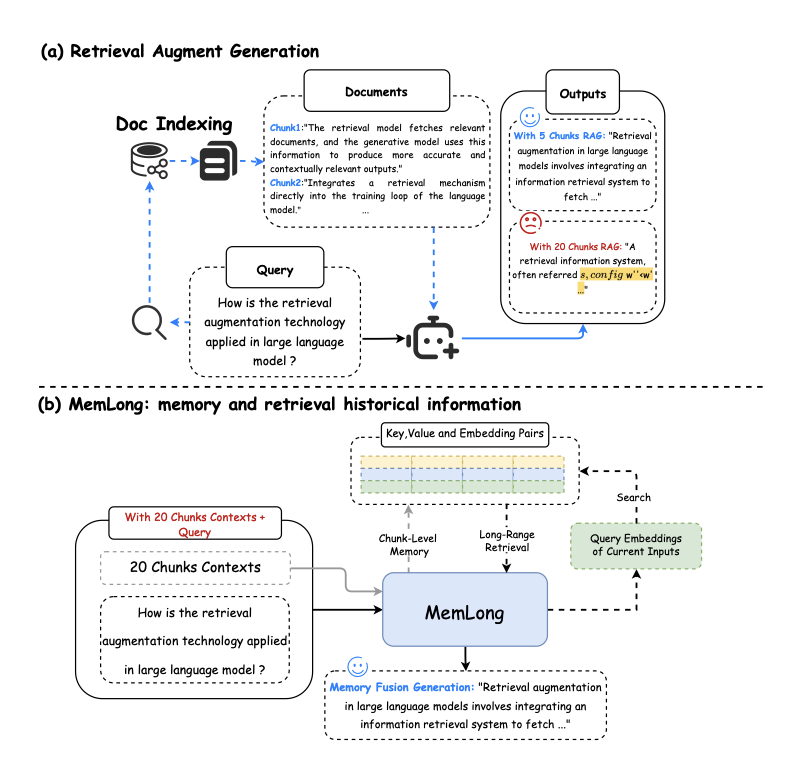 http://arxiv.org/abs/2408.16967v1
http://arxiv.org/abs/2408.16967v1灵活高效地将大语言模型与领域专家混合
UserSumBench:用于评估用户总结方法的基准框架
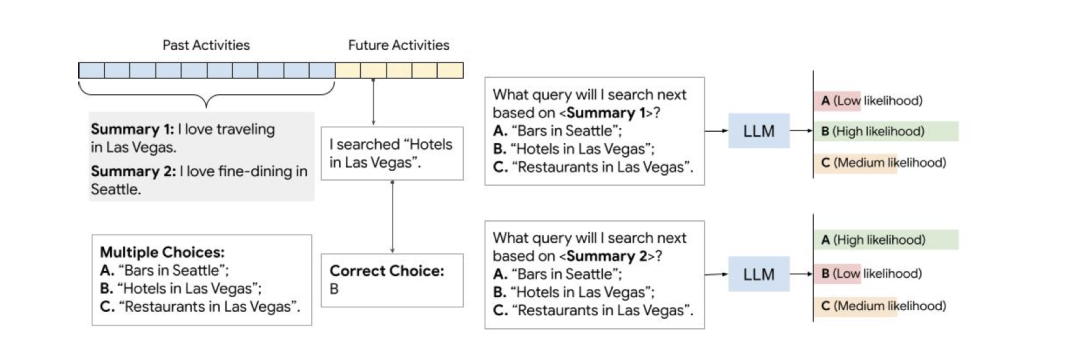
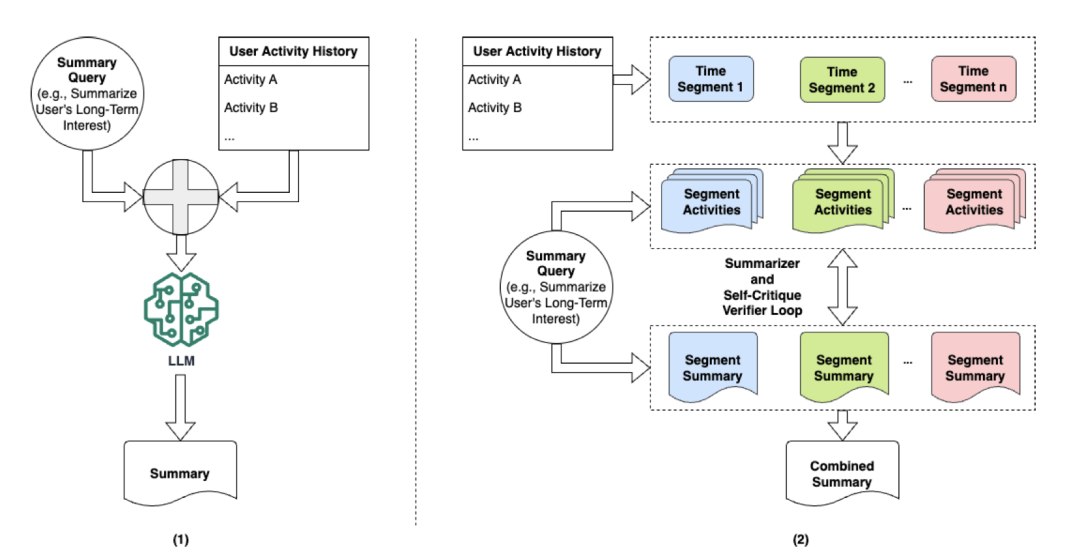 http://arxiv.org/abs/2408.16966v1
http://arxiv.org/abs/2408.16966v1Modularity in Transformers:研究神经元的分离性与专业化
摘要:Transformer模型在各种应用中日益普及,但我们对其内部运作机制的理解仍然有限。本文研究了Transformer架构内神经元的模块化和任务专业化,重点关注视觉(ViT)和语言(Mistral 7B)模型。通过选择性修剪和MoEfication聚类技术的结合,我们分析了不同任务和数据子集中神经元的重叠和专业化。我们的发现显示出任务特定的神经元簇,不同相关任务之间存在不同程度的重叠。我们观察到神经元的重要性模式在随机初始化的模型中某种程度上仍然存在,这表明训练优化了固有的结构。此外,我们发现通过MoEfication识别的神经元簇更强烈地对应于模型早期和后期层中的任务特定神经元。这项工作有助于更细致地了解Transformer的内部,并提供了改进模型可解释性和效率的潜在途径的见解。
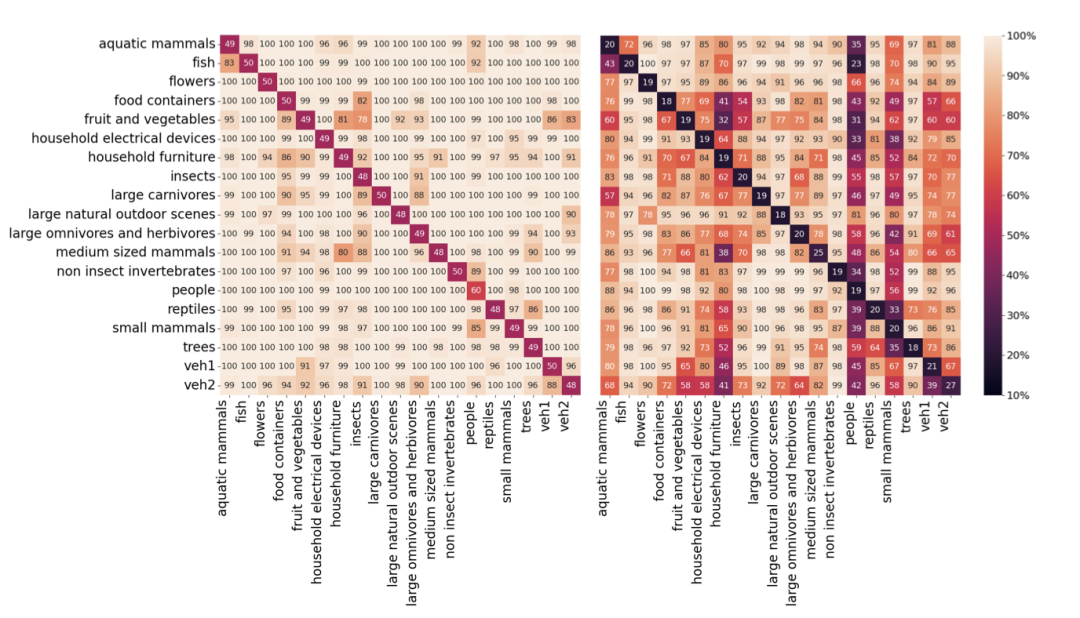
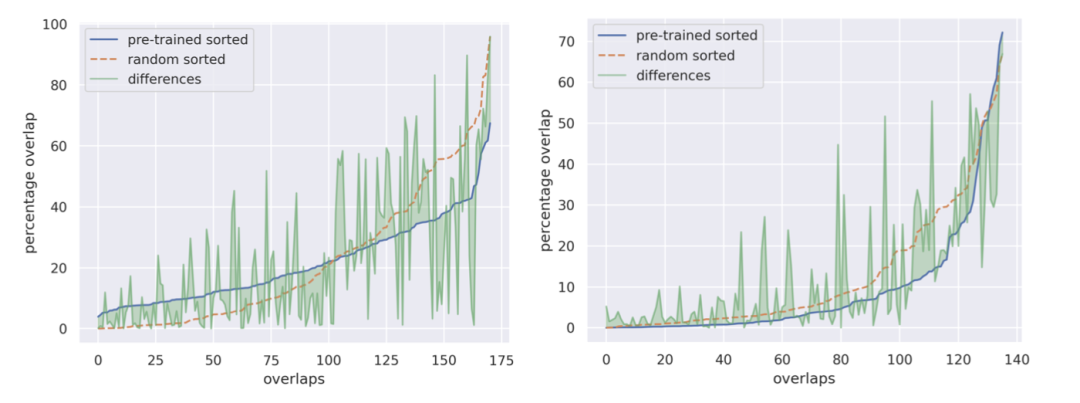 http://arxiv.org/abs/2408.17324v1
http://arxiv.org/abs/2408.17324v1关于迁移学习的扩展定律的实证研究
我们展示了一个有关Transformer模型中迁移学习规模定律的有限经验研究。具体来说,我们研究了一个包含“迁移差距”项的规模定律,该项指示在优化另一个分布的下游性能时,对一个分布进行预训练的有效性。当迁移差距较低时,预训练是一种提高下游性能的成本有效策略。相反,当差距较大时,收集高质量的微调数据变得相对更经济有效。拟合该规模定律到来自不同数据集的实验中揭示了在不同分布之间的迁移差距存在显著变化。从理论上讲,规模定律可以指导最佳数据分配策略,并凸显了下游数据的稀缺性如何成为性能瓶颈。我们的研究结果有助于以一种原则性的方式衡量迁移学习效率,并了解数据可用性如何影响性能。
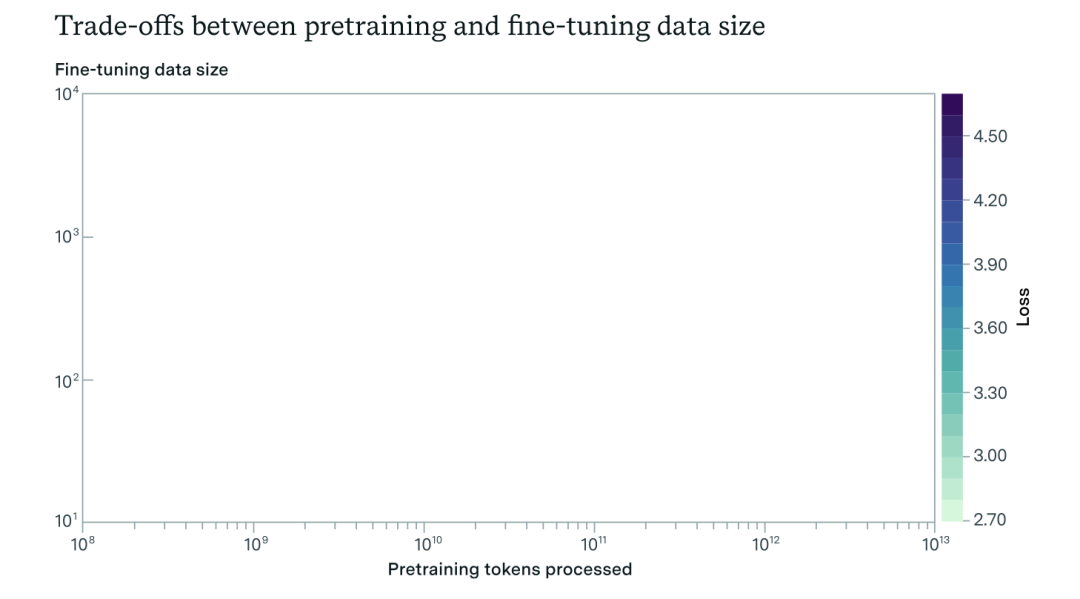
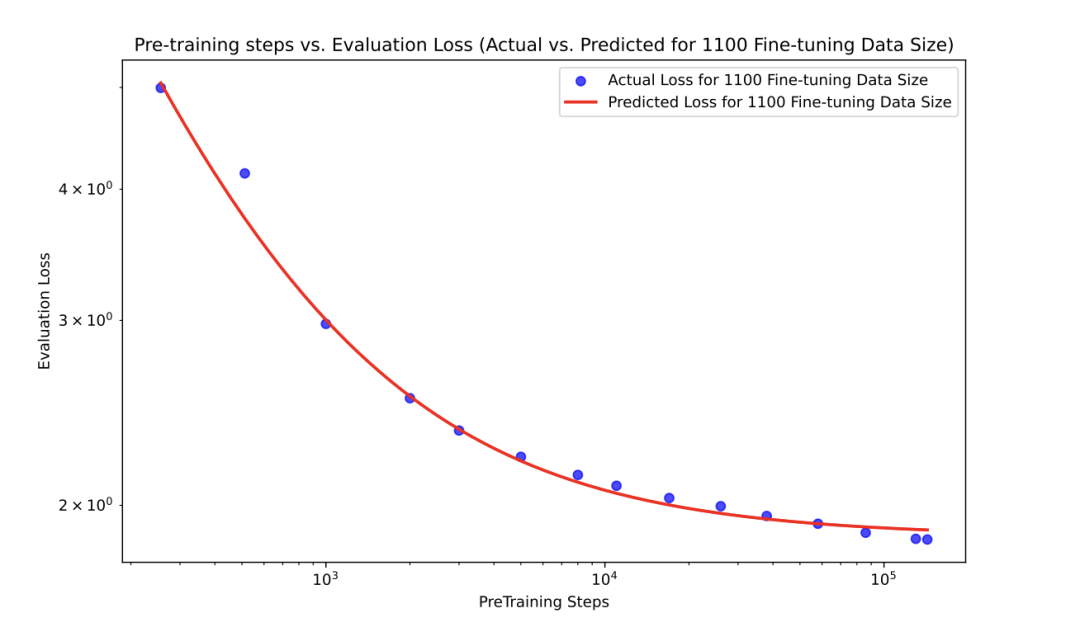 http://arxiv.org/abs/2408.16947v1
http://arxiv.org/abs/2408.16947v1ControlFlow
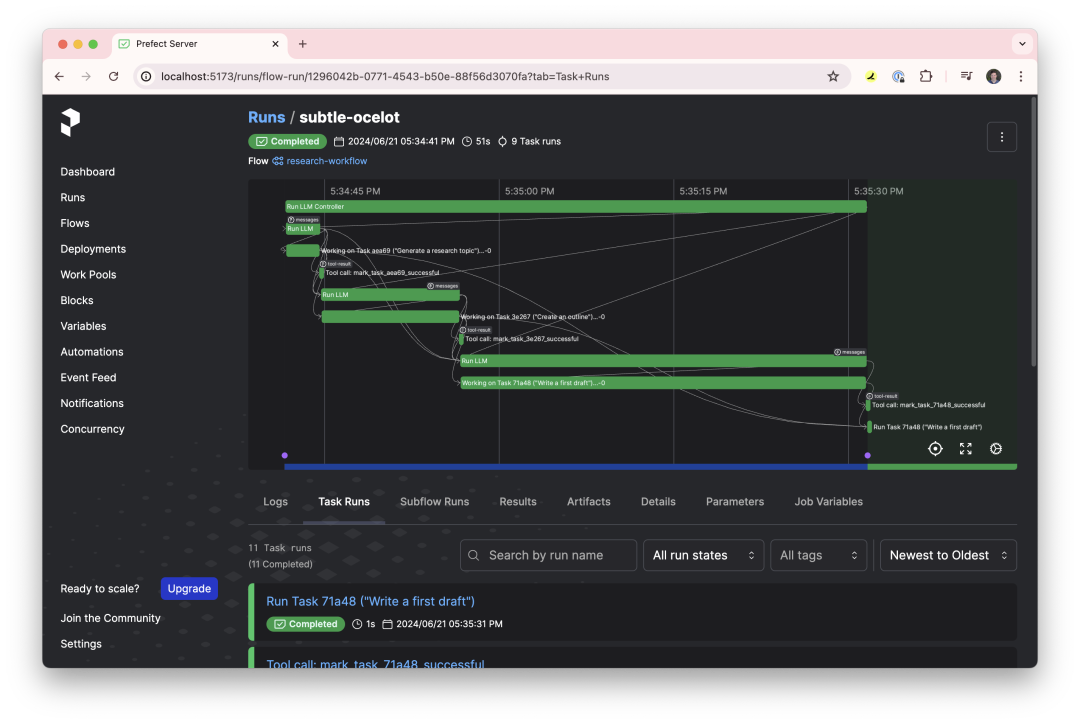 https://github.com/PrefectHQ/ControlFlow
https://github.com/PrefectHQ/ControlFlowcontinuous-eval
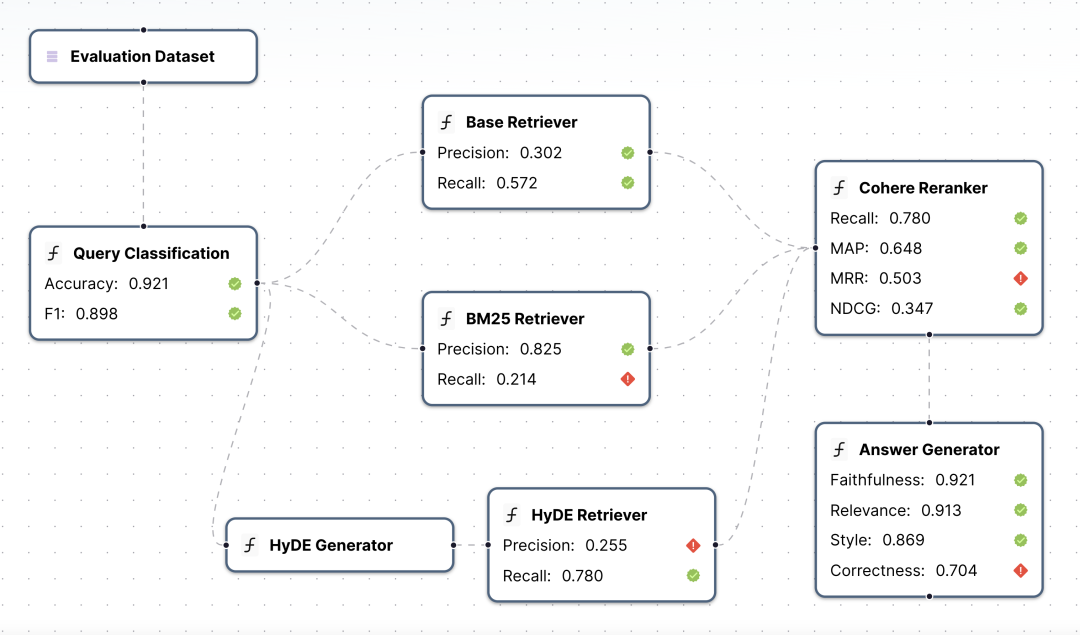 https://github.com/relari-ai/continuous-eval
https://github.com/relari-ai/continuous-eval原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/09/13207.html