
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


学习
AI让全球GDP翻10倍!但风险比核问题还严峻,三大图灵奖大佬对话,WAIC干货看尽
 https://mp.weixin.qq.com/s/zg-tfuymuFYprAF4wRzcjQ
https://mp.weixin.qq.com/s/zg-tfuymuFYprAF4wRzcjQ聊聊大模型推理中的分离式推理
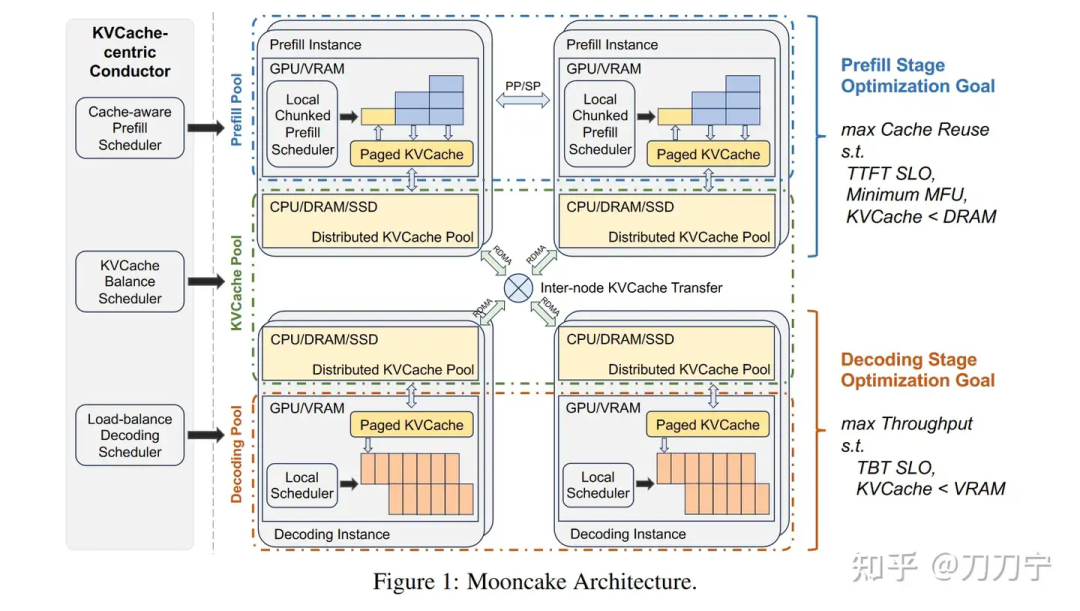 https://zhuanlan.zhihu.com/p/706469785?utm_psn=1791942179708616705
https://zhuanlan.zhihu.com/p/706469785?utm_psn=1791942179708616705大模型推理分离架构五虎上将
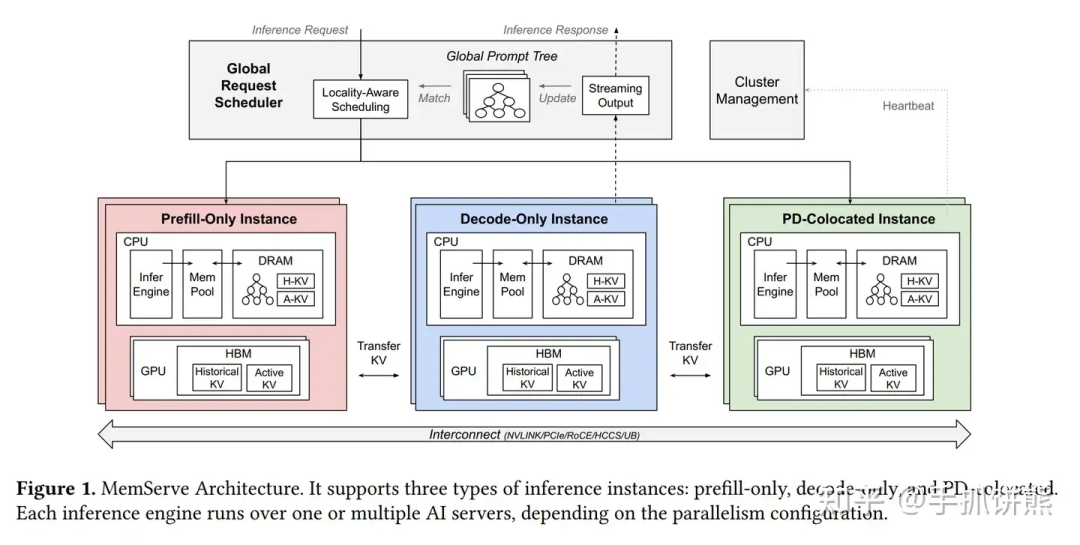 https://zhuanlan.zhihu.com/p/706218732
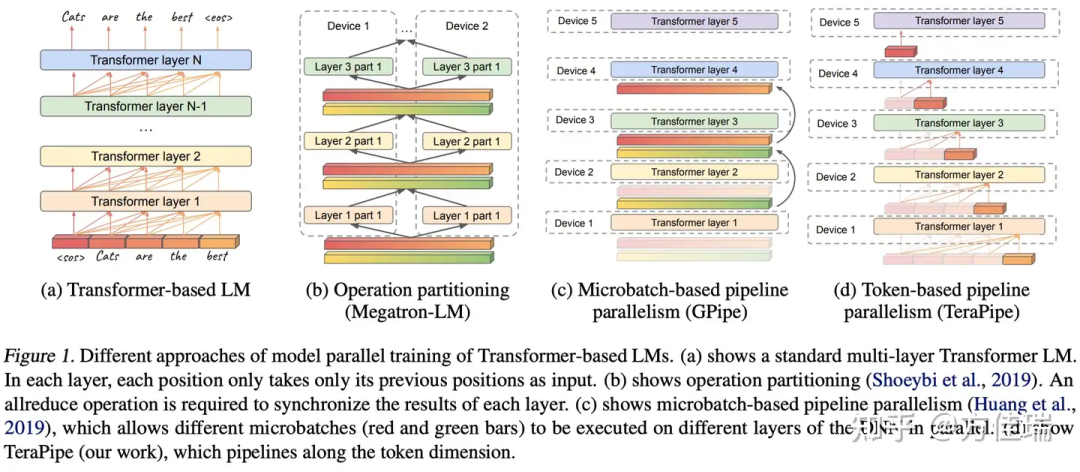
https://zhuanlan.zhihu.com/p/706218732为Token-level流水并行找PMF:从TeraPipe,Seq1F1B,HPipe到PipeFusion
-
TeraPipe:由 UC Berkeley 的 Ion Stoica 团队提出,它将模型沿层切分成多个阶段,并通过动态规划优化序列切分,以实现负载均衡。 -
Seq1F1B:结合了 TeraPipe 和 1F1B 的方法,同时切分 Batch 和序列,减少了执行时间和内存消耗。它通过 FLOPs 估计来实现负载均衡,而非实际运行采集。 -
HPipe:在 NACCL 2024 上发表的工作,将 TeraPipe 的方法扩展到异构设备上的推理任务,并考虑了通信开销。 -
PipeFusion:由方佳瑞团队提出,这是一种针对 DiT 扩散模型的并行推理方法,利用了 Diffusion Model 的特性,避免了 Causal Mask 带来的负载均衡问题。
 https://zhuanlan.zhihu.com/p/706475158?utm_psn=1791489494618349568
https://zhuanlan.zhihu.com/p/706475158?utm_psn=1791489494618349568将 MOE 塞到 LoRA: 一篇文章的诞生
 https://zhuanlan.zhihu.com/p/704761512
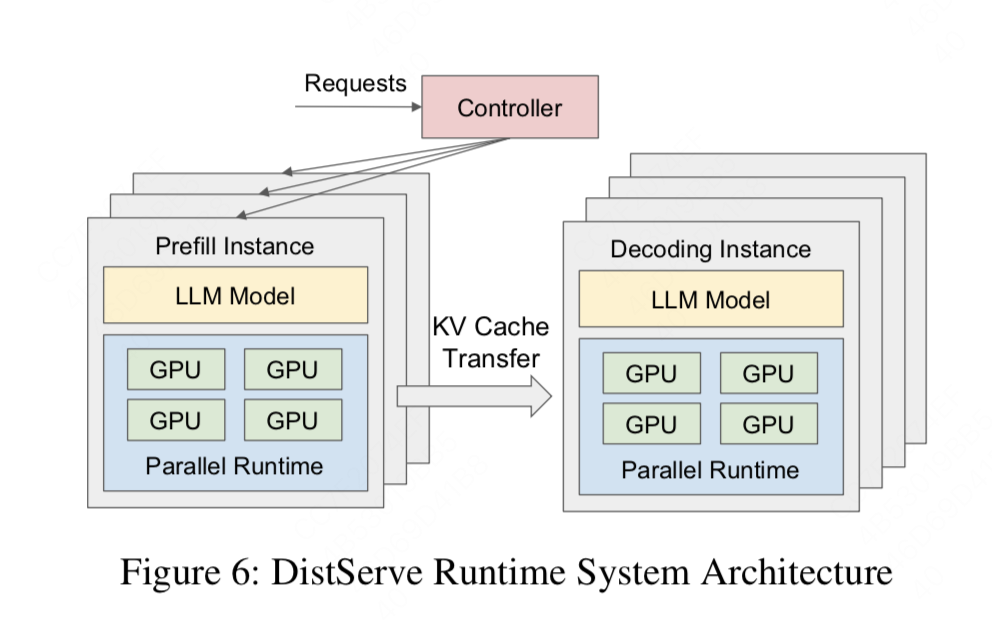
https://zhuanlan.zhihu.com/p/704761512分离式推理架构1,从DistServe谈起
 https://zhuanlan.zhihu.com/p/706761664
https://zhuanlan.zhihu.com/p/706761664由Ring-Attention性能问题引发的计算通信overlap分析
 https://zhuanlan.zhihu.com/p/706805407?utm_psn=1791944339200544770
https://zhuanlan.zhihu.com/p/706805407?utm_psn=1791944339200544770为AI供电-超万卡GPU算力集群的算电协同与零碳发展
 https://mp.weixin.qq.com/s/TjPLLGBV1GqLCj8FZ8mASg
https://mp.weixin.qq.com/s/TjPLLGBV1GqLCj8FZ8mASgOpenvid
 https://nju-pcalab.github.io/projects/openvid/
https://nju-pcalab.github.io/projects/openvid/fish-speech
 https://github.com/fishaudio/fish-speech
https://github.com/fishaudio/fish-speech原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/07/14302.html