
Meta(Facebook)终于按耐不住,也推出了自己的基于计算机视觉的多模态开源AI模型ImageBind!


这是目前第一个能够同时绑定来自六种模式数据的 AI 模型,且无需明确监督(Explicit Supervised)。
通过识别这些模式(图像和视频、音频、文本、深度、热和惯性测量单元 (IMU))之间的关系,比如说你可以通过文本描述,可以同时支持生成另外5种类型的信息!而热图和 IMU 意味着该模型还可以通过计算速度和位置来工作。

这一突破通过使机器能够更好地分析许多不同形式的信息来帮助推进人工智能。
对于人类来说,一张图片可以将整个感官体验“绑定”在一起。 ImageBind 通过学习将多个感官输入绑定在一起的单个嵌入空间来实现这一点,而无需明确的监督。
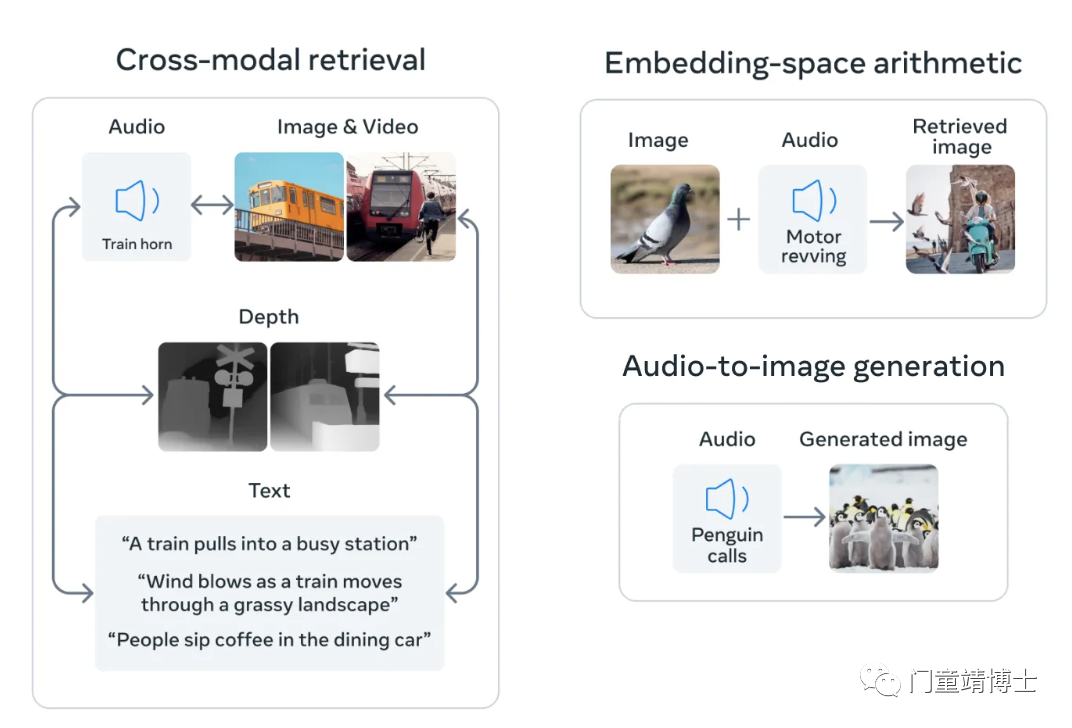
它甚至可以升级现有的 AI 模型以支持来自六种模态中任何一种的输入,从而实现基于音频的搜索、跨模态搜索、多模态算法和跨模态生成。
启用零样本(Zero-Shot)和少样本(Few-Shot)识别
开源 ImageBind 模型在跨模态的紧急零镜头识别任务上实现了新的 SOTA 性能——甚至比之前专门为这些模态训练的专家模型更好。
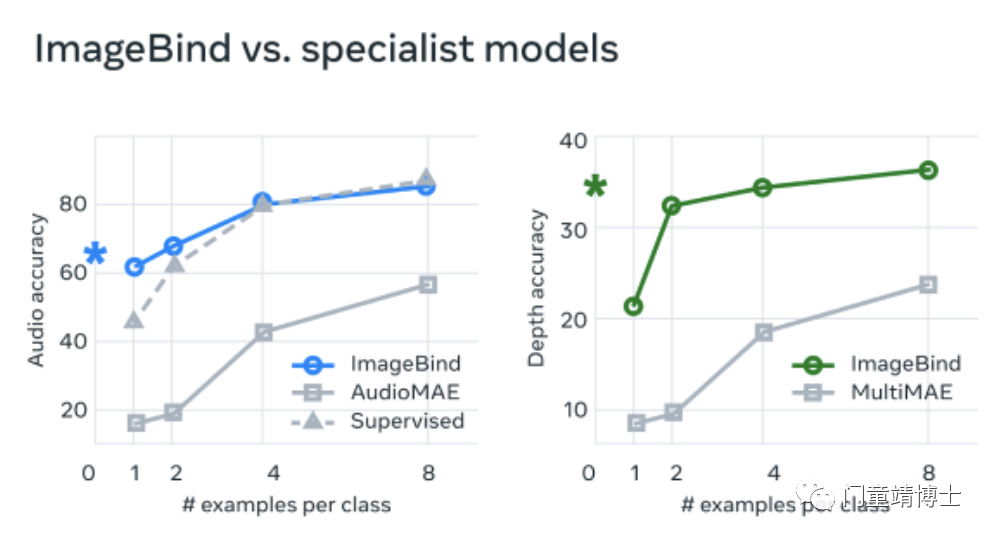
下面看下它的功能演示~
同时支持6种模态信息生成
1. 使用图像检索音频
ImageBind 可以通过使用图像或视频作为输入来立即生成音频。这可用于增强具有相关音频剪辑的图像或视频,例如将海浪的声音添加到海滩图像中。
比如选择下面的图像,ImageBind 将检索生成相应的音频选项。
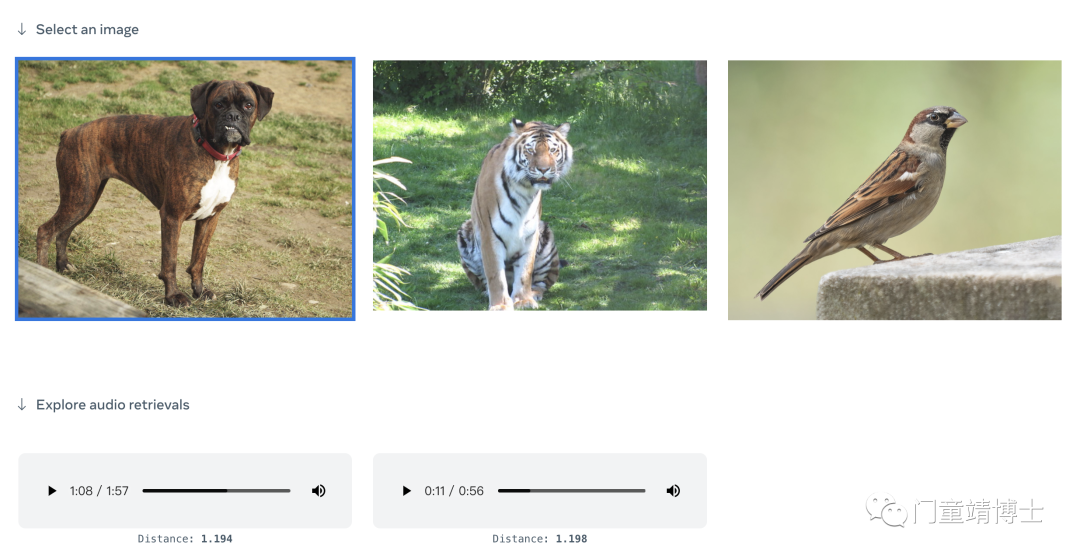
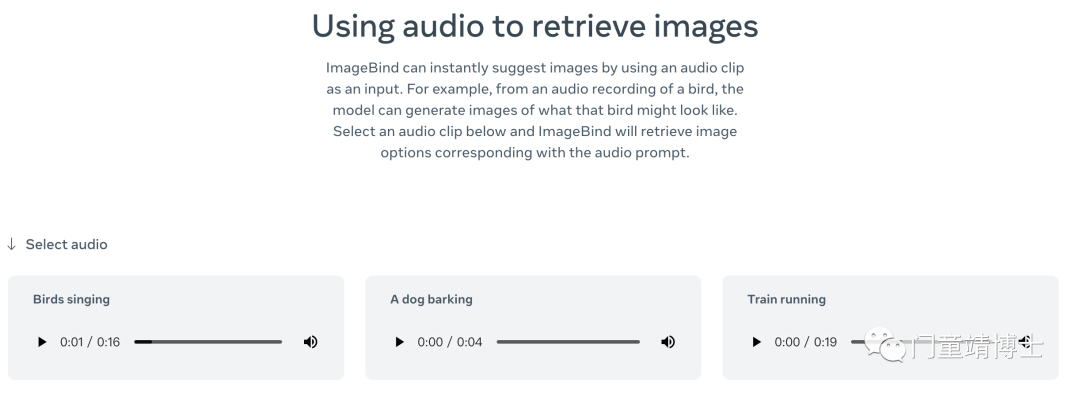
2. 使用音频检索图像
ImageBind 可以通过使用音频剪辑作为输入来立即建议图像。
例如,根据一只鸟的录音,该模型可以生成该鸟可能长什么样子的图像。选择相应的音频剪辑,ImageBind 将检索与音频提示对应的图像选项。
3. 使用文本检索图像和音频
ImageBind 可以通过使用文本作为输入来推荐图像和音频。选择相应的文本提示,ImageBind 将检索与该特定文本关联的一系列图像和音频剪辑。
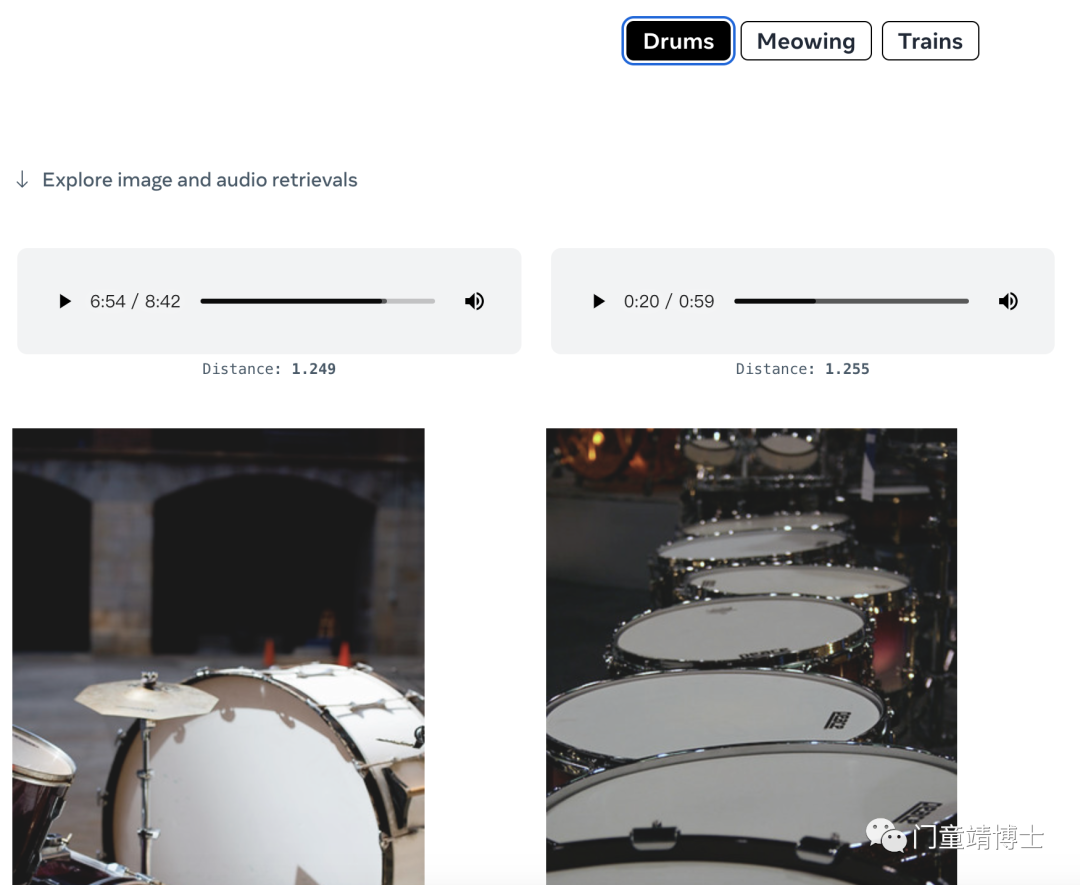
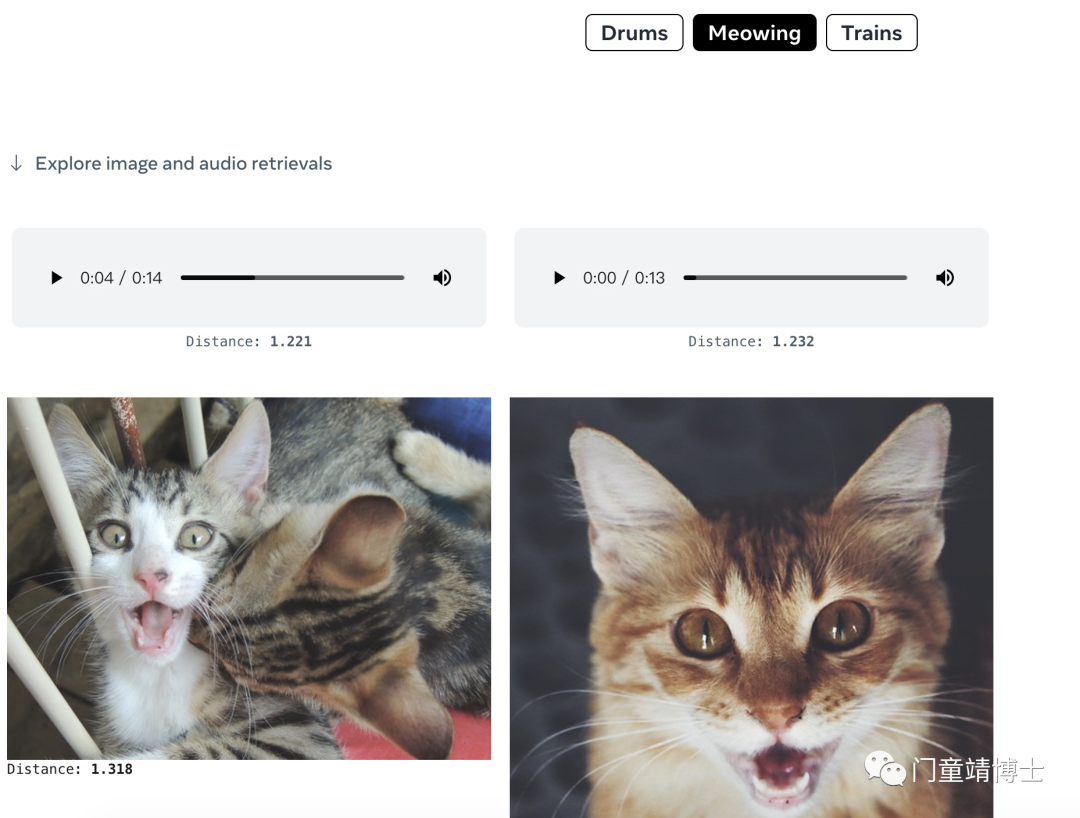
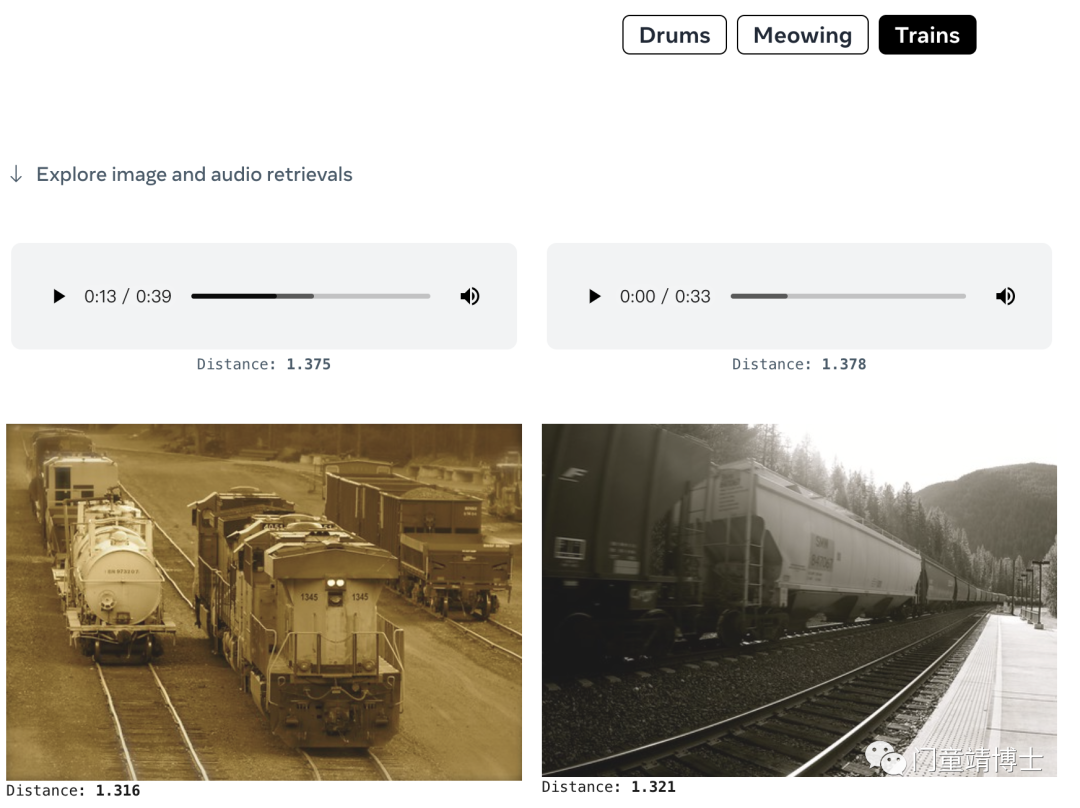
4. 使用音频和图像检索相关图像
使用将音频和图像绑定在一起的提示,人们可以在几秒钟内检索到相关图像。 这对于查找与视频剪辑的视觉和听觉元素相关的图像可能很有用。 从下面的音频和图像提示中选择以检索图像输出。
比如通过狗的声音和海面的图片,可以生成狗面朝大海~
比如通过冲水的声音和水果,可以生成洗好的水果篮子~
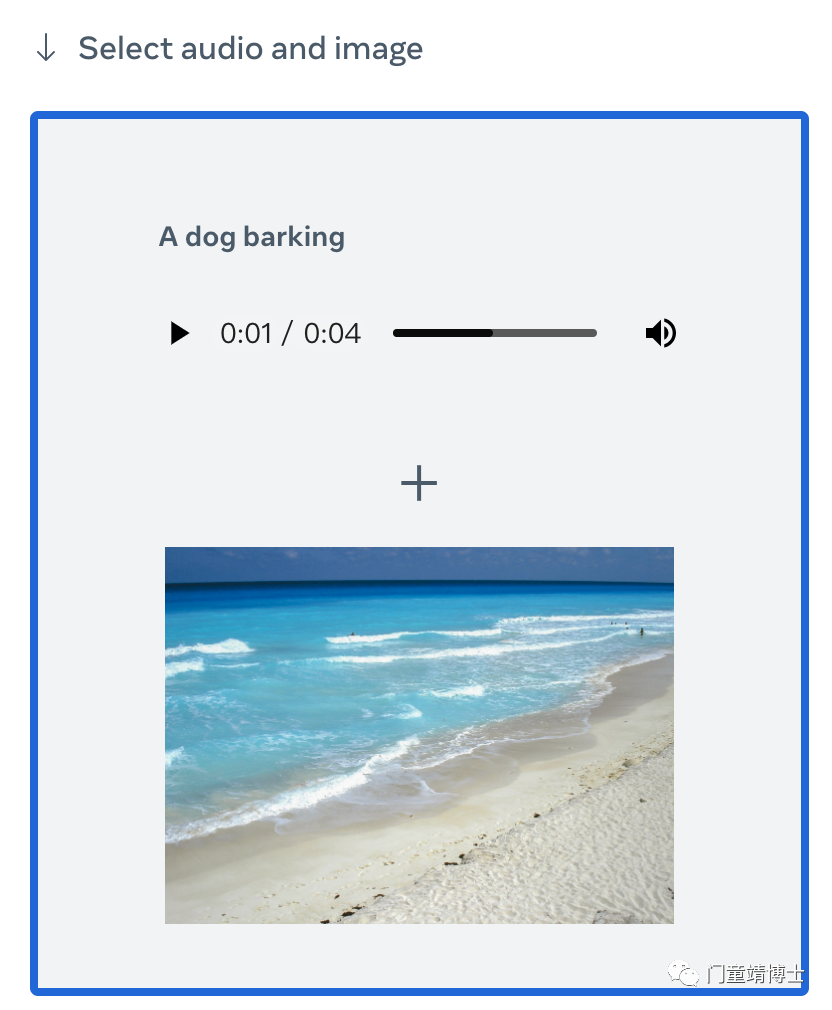
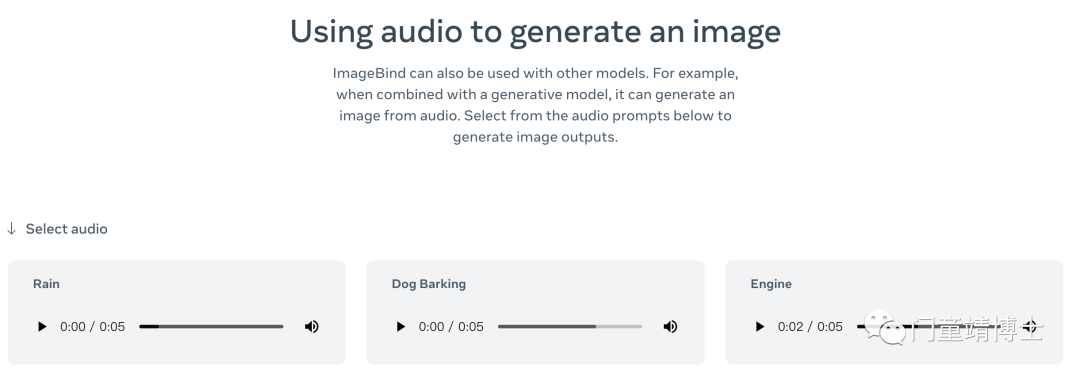
5. 使用音频生成图像
ImageBind 也可以与其他模型一起使用。例如,当与生成模型结合时,它可以从音频生成图像。从下面的音频提示中选择以生成图像输出。
ImageBind CVPR 2023 论文
该模型是基于这篇CVPR 2023 年的这篇论文,主要介绍了 ImageBind,这是一种学习跨六种不同模态(图像、文本、音频、深度、热和 IMU 数据)联合嵌入的方法。
该文章的结论证明,配对数据的所有组合都不是训练这种联合嵌入所必需的,只有图像配对数据足以将模态绑定在一起。
ImageBind 可以利用最近的大规模视觉语言模型,并通过使用它们与图像的自然配对将它们的零样本(Zero-shot)功能扩展到新的模式。它支持“开箱即用”(out-of-box)的新型应急应用程序,包括跨模态检索、使用算术组合模态、跨模态检测和生成。
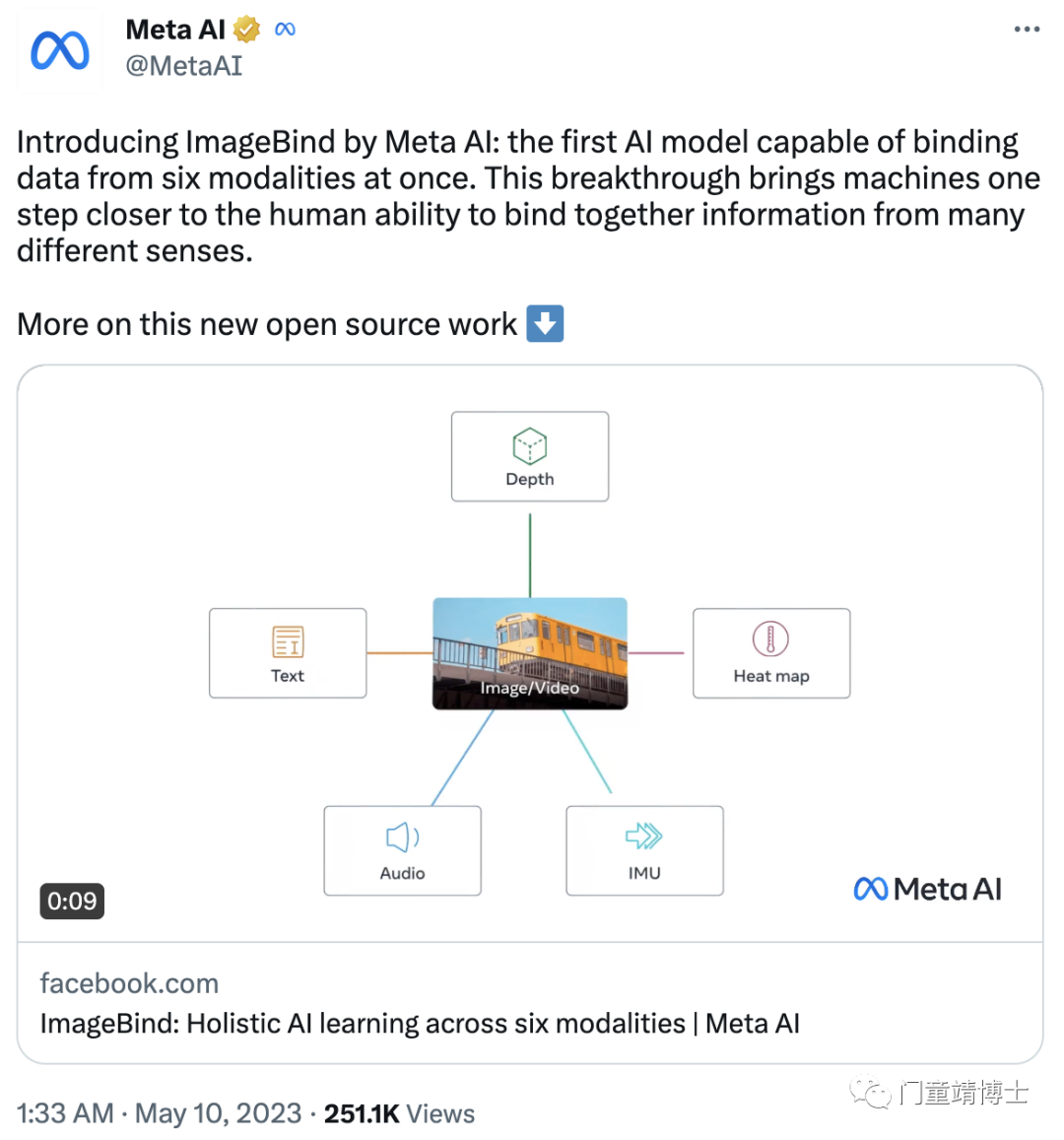
应急能力随着图像编码器的能力而提高,作者在跨模态的紧急零镜头识别任务上设置了一个新的最先进的技术,优于专家监督模型。最后,作者展示了优于先前工作的强大的少样本(Few-shot)识别结果,并且 ImageBind 作为视觉模型的新方法,可以支持视觉和非视觉的评估任务。
Github开源模型
截止目前,已经有3K🌟🌟!
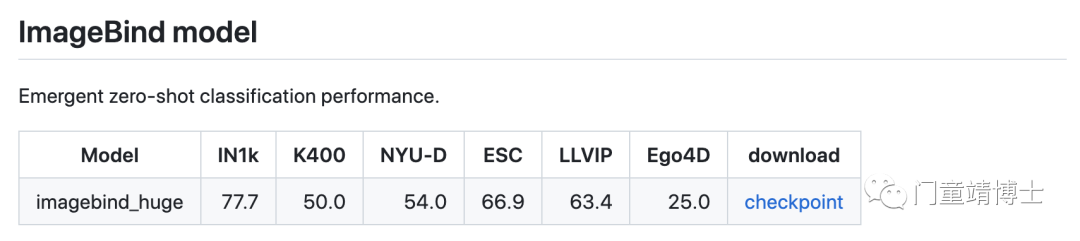
模型相对有点大,有4.5个G,不过有条件不妨一试~
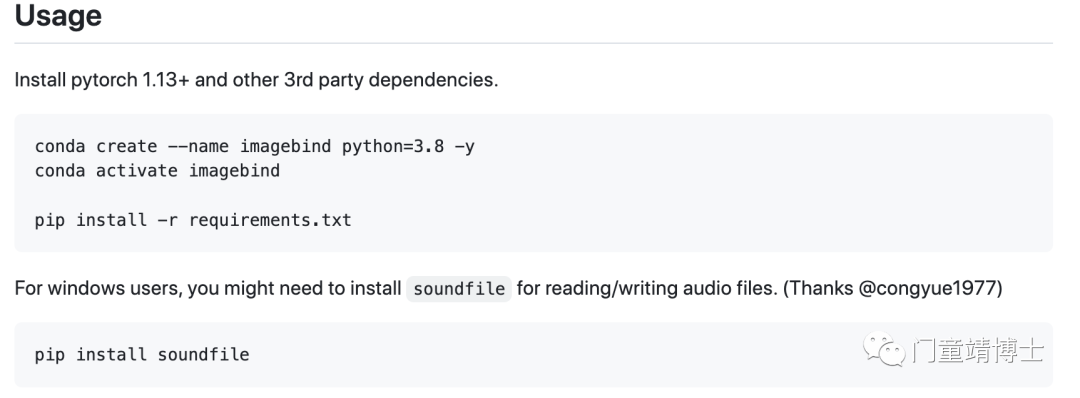
安装过程也比较简单,具体参考Github README.md
有新发现,欢迎交流~

参考文献:
[1] https://imagebind.metademolab.com/demo?modality=I2A
[2] https://arxiv.org/abs/2305.05665
[3] https://github.com/facebookresearch/ImageBind
HAVE FUN!

原创文章,作者:门童靖博士,如若转载,请注明出处:https://www.agent-universe.cn/2023/05/11667.html