我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


学习
如何用 Triton实现一个更高效的topk_gating kernel?——算子合并技术
在当前的代码架构下,MoE(混合专家模型)的gating网络面临频繁启动多个小kernel带来的计算开销问题,这显著影响模型训练的效率。为提升topk_gating kernel的效率,本文提出将多个小kernel整合为一个大kernel,以减少启动开销。我们观察了topk_gating算子的内部工作机制,并设计了三种优化策略:利用Cuda Graph进行流程优化、使用torch.compile进行自动优化、以及实施Kernel fusion进行手动或自动的kernel整合。经过比较验证,基于Triton实现的Kernel fusion被确认为最优选择,显著提升了整体性能。
MoE模型通过GateNet和Experts实现稀疏计算。GateNet负责判断输入样本由哪个专家处理,而Experts是一组相对独立的模型。GateNet通过softmax门控函数选择前K个专家,从而控制稀疏性,优化计算资源的使用。MoE的稀疏性与LSTM中的“门”概念不同,主要用于连接数据与专家模型,允许选择特定专家进行处理。
TopK操作在CUDA中应用于选择张量中最大或最小的K个元素,topk_gating算子在神经网络中的重要性体现在注意力机制、稀疏性和效率、模型压缩等方面。
为实现更高效的topk_gating Triton kernel,考虑了三种方法:
1. Cuda Graph:通过捕获运行模式,减少kernel启动开销,但在实际应用中遇到shape不变的限制,导致效果有限。
2. torch.compile:将模型转化为优化表示,尽管在重复计算上提升了效率,但gating网络仍未融合为一个大kernel。
3. Kernel fusion:将多个kernel合并为一个,减少内存访问和kernel启动时间。通过将topk_gating分为多个部分进行Triton重写,第一部分的性能提升达到57倍,第二部分提升39.24倍,展示了kernel fusion的有效性。

https://zhuanlan.zhihu.com/p/730534981?utm_psn=1822986551241609216
Playground v3:Deep-Fusion,一个策略实现 T2I 模型更好的图文对齐
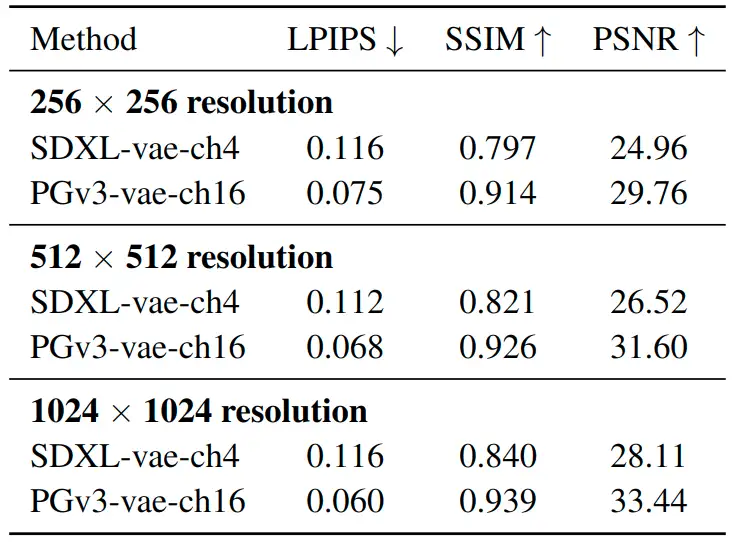
本文提出的 Playground v3 (PGv3) 是 Playground Research 团队于 2024.09 推出的最新 text-to-image (T2I) 模型,在多个测试基准上达到了 SoTA 性能。Playground v3 不像传统依赖 LLM (比如依赖于 T5 或者 CLIP 文本编码器) 的 T2I 模型,它完全整合了 LLM。Playground v3 通过一种新颖的 Deep-Fusion 结构,独立地从 decoder-only LLM 中获取文本条件。此外,为了提升图像字幕的质量,作者开发了一个内部的字幕生成器,能够生成具有不同细节层次的字幕,丰富了文本结构的多样性。作者还引入了一个新的基准 CapsBench,用于评估详细的图像字幕生成性能。实验结果表明,PGv3 在文本提示的准确性、复杂推理和精确的文本渲染方面表现优异。用户偏好研究表明,PGv3 在常见的设计应用 (如贴纸、海报和徽标设计) 中具备超越人类的图形设计能力。此外,PGv3 还引入了新的功能,包括精确的 RGB 颜色控制和强大的多语言理解能力。
https://zhuanlan.zhihu.com/p/720798652?utm_psn=1822935089656508417
本文讨论了几种后训练的数据合成方法,并根据实际应用场景进行简单分类,突出了技术细节:
1. 基于GPT4生成pair:此类方法如self-instruct和evol-instruct,适用于prompt和response匮乏但GPT4效果好的情况,相当于数据蒸馏。适合生成完整的问答对。
2. 基于GPT4生成问题或答案:例如,已知答案生成问题的方式适用于QA、MATH等特定任务。这类方法可以通过构建answer -> question任务扩展数据生成能力,并在指令微调(SFT)中加入,生成大量问题。
3. 模型自生成数据的迭代训练:类似于self-training,通过模型生成数据来不断提升自身表现,但依赖于模型的知识丰富度。此方法在GPT4无法生成高质量response时作为备选,但可能更节省成本。
META-REWARDING LANGUAGE MODELS提出了meta-judge的概念,模型分为actor、judge和meta-judge三个角色,meta-judge通过比较不同的评分结果帮助模型提升。
I-SHEEP方法简单,依赖模型自我生成与评估,无需额外信息输入,通过朴素的generate_response -> self assessment -> filtering -> SFT流程,取得显著效果。
关键问题在于如何评估生成的response质量,需依赖强大的reward模型或模型自身来完成。

https://zhuanlan.zhihu.com/p/715155768
多模态大模型–预训练策略探究[VILA、MM1、NVLM]
本文探讨了多模态大模型在视觉语言预训练中的关键技术细节,尤其是对模型进行图像和语言的联合建模。
在VILA中,模型的多模态预训练设计对下游任务的影响显著,主要结论包括:冻结LLMs可以提升zero-shot性能,但会削弱in-context learning能力。加入图文交替数据提升性能,而简化的projector设计比复杂的更有效。此外,在指令微调阶段加入文本数据能提高模型在纯文本任务中的表现。
VILA还发现,更新LLM是提升视觉-语言理解能力的关键,而仅训练projector效果不佳。为了维持图像到文本生成和纯文本生成能力,数据融合是重要策略,尤其是在使用图像-文本配对和交替数据时,模型学习生成能力更强,但text-only generation的性能也会有所退化。
在MM1中,视觉编码器的重要性依次为图像分辨率、任务、容量和预训练数据。实验表明高分辨率输入有助于性能提升,但projector设计影响较小。预训练数据需要多种类型混合,尤其是交替格式数据对few-shot任务有较大提升,但对zero-shot能力影响较大。
NVLM的研究表明,数据质量和任务多样性优于数据量。Decoder-only架构在数学推理和OCR任务上表现最佳,尤其是在math和text benchmark上的提升显著,表明这种架构更适合保留和增强text-only generation能力。

https://zhuanlan.zhihu.com/p/722324120?utm_psn=1822778637981708288
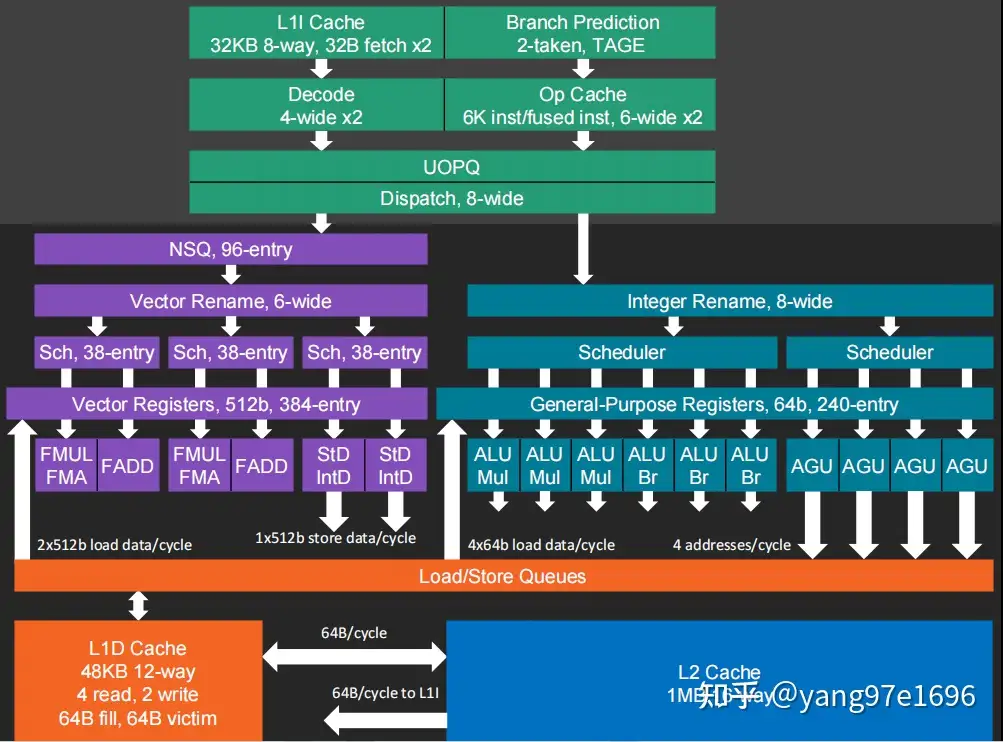
IPC(每时钟周期指令数)提升:Zen5 相较于 Zen4 的IPC提升了16%,核心设计上有Zen5和Zen5c两种,分别为性能核和能效核。Zen5性能核频率高、功耗大,Zen5c则面积小、能效好。
-
分支预测:一级BTB项从1.5K增加至16K,提升分支预测命中率。
-
指令处理:指令派发宽度从6增加至8,整数计算单元从7增至10,浮点运算单元从3增至4,访存单元增至4个。
-
寄存器和缓存:整数物理寄存器略有增加,浮点/向量寄存器翻倍,ROB(重排序缓冲区)增加40%,L2缓存带宽翻倍。
推理引擎:XDNA2 NPU推理引擎支持50TOPS INT8和50TOPS Block FP16,适合本地小规模AI模型推理。
-
L1 Cache:32KB,8路,分支预测性能提升,解码缓存增加到6K条。
-
L2 Cache:1MB,16路,读写带宽提升,访存单元可以支持每周期2个Store和4个Load操作组合。
-
L3 Cache:延时降低,每个核支持4MB或8MB L3缓存。
浮点与向量运算:Zen5 支持AVX-512指令集,拥有4个浮点乘法单元,物理寄存器扩展至384个,向量宽度512位,适合高性能计算任务。
https://www.zhihu.com/question/663892629/answer/3637802951?utm_psn=1822700512396574720
在大模型爆发前,推理框架如TensorRT是理想的交付界面,处理硬件细节同时满足快速推理需求。但在LLM时代,推理框架的实现已经深度耦合了业务需求,如SLO取舍、batch管理等,使得替换现有框架变得复杂,尤其是国产芯片公司想凭借自研框架切入市场更为困难。
-
Prefill与decode的SLO:涉及性能和延迟的平衡。
-
SLO与成本:资源调度的激进程度与系统复杂度成正比。
-
-
量化与prefix caching:各自带来不同的性能与资源管理权衡。
-
标准化推理框架的难度:由于LLM推理深度耦合业务逻辑,芯片公司在不掌握用户业务细节的情况下,很难优化超过现有框架的水平。
-
市场渗透难题:即使开源部分框架或提升服务层接口,也难以改变用户已成熟使用NV框架的现状。
-
开源策略:参考TensorRT-LLM,开源与业务耦合强的部分,但需在开源中具备影响力,否则难获用户支持。
-
云服务与token售卖:芯片公司自己做云服务,通过直接获得用户的真实应用场景来优化推理框架,然而技术门槛极高。
-
算子层优化:LLM推理的算子较为明确,算子层可能成为最佳交付界面,但挑战在于算子融合、私有格式与设备-主机通信协同的复杂性。算子库如FlashInfer虽已有所探索,但理想的框架与算子分界仍未成熟。
https://arxiv.org/abs/2409.07725
GPGPU中一些问题的理解与思考(3)- 指令执行吞吐与指令集设计
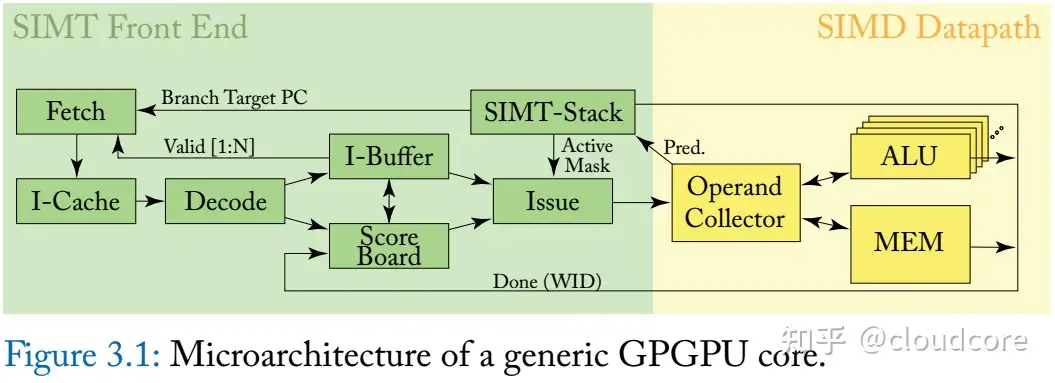
1. GPGPU指令执行流水线:与传统CPU不同,GPGPU执行流程更接近RISC架构,包含取指、解码、执行等基本步骤,但在执行前需要处理调度、scoreboard仲裁等复杂操作。由于流水线复杂且并行度高,GPU采用较低主频(1-2GHz)来平衡复杂性和功耗。
2. 吞吐影响因素:GPGPU指令吞吐受多个因素影响,如功能单元数目、调度单元吞吐、寄存器访问冲突等。吞吐优化策略包括减少流水线气泡、增加指令并行度等。
-
定长指令:GPGPU指令通常为定长(如128位),便于解码和优化,并支持更多的操作数和控制信息。
-
提高并行性:为提高指令级并行性(ILP),GPU通过减少指令依赖和资源冲突来优化吞吐,示例包括IADD3和LOP3等指令。
-
复合操作:GPU支持多操作数指令,如FFMA(乘加)、IMAD(整数乘加),提高每个指令的有效操作数。
4. 立即数与常量内存:立即数操作数受限于指令长度(通常32位),而Constant Memory为较大常量提供支持,有助于优化性能。
-
MUFU:处理复杂的超越函数(如sin、cos、log),这些函数通过近似计算提高效率。
-
FSETP:专为浮点数比较而设计,支持处理NAN和正负零等特殊情况。
-
BAR:用于同步线程块,支持多种同步模式,提升并行执行效率。
指令集设计不仅决定了硬件的性能潜力,还通过复杂的调度和资源管理优化指令并行性,适应大规模并行计算的需求。
https://zhuanlan.zhihu.com/p/391238629?utm_psn=1822699418551468032
ProX(Programming Every Example)是一种新框架,将数据精炼视为编程任务,通过小型语言模型生成和执行细粒度操作,显著提升预训练语料库的质量。它分为文档级和块级两个精炼阶段,适用于多种语料库和模型,能够在不定制的情况下提升特定领域(如数学)的性能,并节省训练计算量。
https://gair-nlp.github.io/ProX/
Llama-3.2-11B-Vision 是由 Meta 开发的多模态大型语言模型,具备处理图像和文本的能力,适用于视觉问答、图像标注等任务。该模型拥有 110 亿个参数,经过优化以提高性能和安全性,主要支持英语,但可以通过微调支持其他语言。
https://huggingface.co/meta-llama/Llama-3.2-11B-Vision
-
-
-
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/09/21280.html

