
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


论文
逐个列出:一种面向多模式大语言模型的新数据源和学习范式
 http://arxiv.org/abs/2404.16375v1
http://arxiv.org/abs/2404.16375v1Tele-FLM:大语言模型技术报告
 http://arxiv.org/abs/2404.16645v1
http://arxiv.org/abs/2404.16645v1让你的LLM充分利用上下文
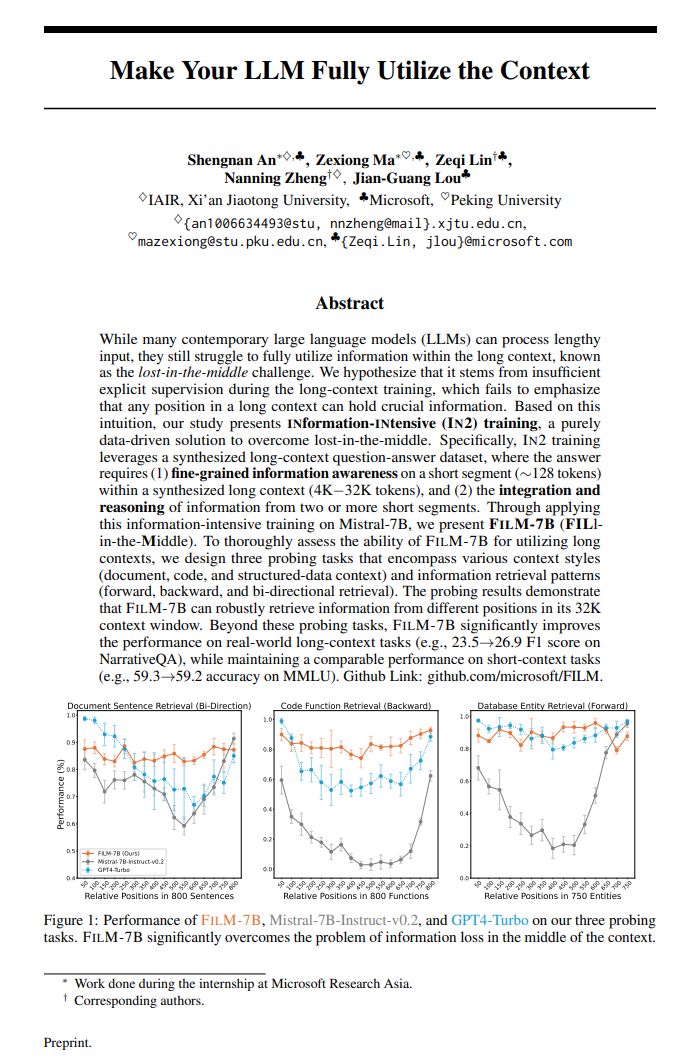 http://arxiv.org/abs/2404.16811v1
http://arxiv.org/abs/2404.16811v1对大语言模型在事实知识回忆上的整体评估
 http://arxiv.org/abs/2404.16164v1
http://arxiv.org/abs/2404.16164v1层间跳跃:启用提前退出推理和自我推测解码
 http://arxiv.org/abs/2404.16710v1
http://arxiv.org/abs/2404.16710v1指导至关重要,面向特定任务微调的一种简单而有效的任务选择方法
 http://arxiv.org/abs/2404.16418v1
http://arxiv.org/abs/2404.16418v1语言模型合成CRISPR蛋白质用于基因编辑
Llama 3 长上下文很容易

Yi Tay推特小号“嘲讽”Phi-3:看都不看


Meta Paper: Enabling Early Exit of LLM
 https://arxiv.org/pdf/2404.16710
https://arxiv.org/pdf/2404.16710WrenAI
 https://github.com/Canner/WrenAI
https://github.com/Canner/WrenAILLM Scraper
 https://github.com/mishushakov/llm-scraper
https://github.com/mishushakov/llm-scraperOpenCRISPR

大模型日报16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/15768.html