
特别活动


我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。

学习
大 Batch 训练 LLM 探索
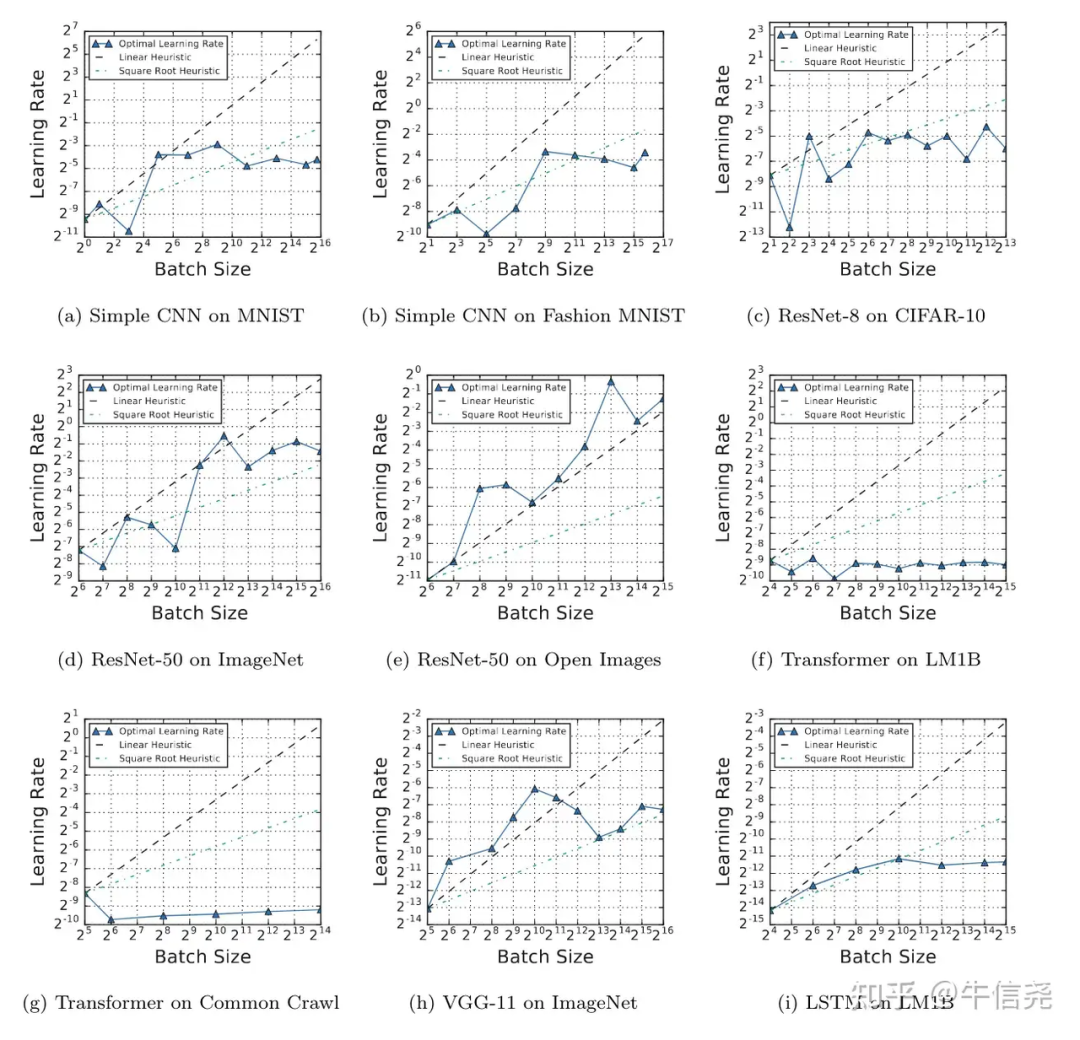 https://zhuanlan.zhihu.com/p/666997679?utm_psn=1776623516152389632
https://zhuanlan.zhihu.com/p/666997679?utm_psn=1776623516152389632LLaVA(六)训练你自己的多模态模型
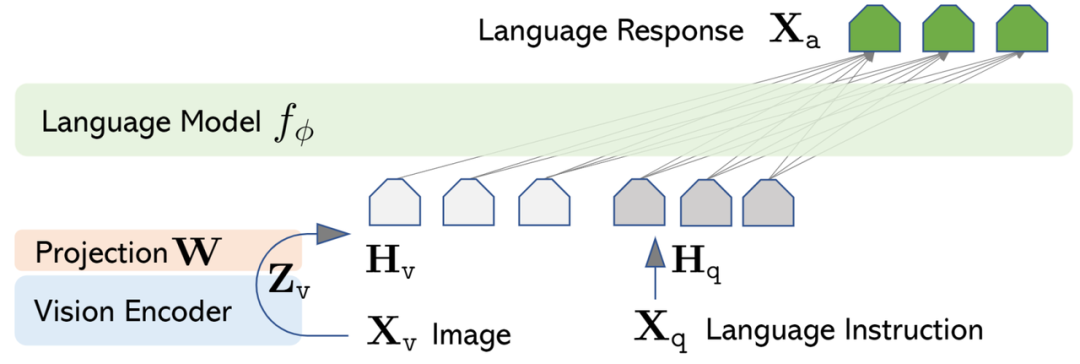 https://zhuanlan.zhihu.com/p/698218006?utm_psn=1776623143408787456
https://zhuanlan.zhihu.com/p/698218006?utm_psn=1776623143408787456GPU深度学习性能的三驾马车:Tensor Core、内存带宽与内存层次结构
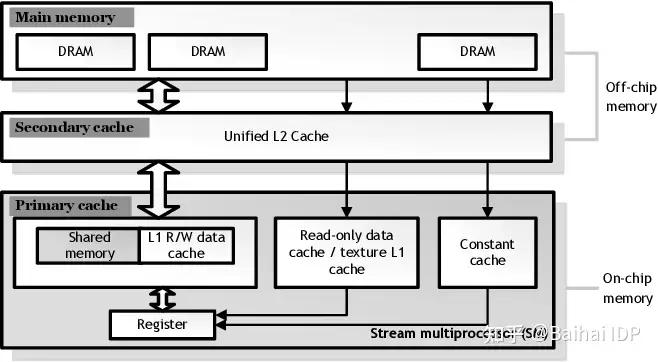 https://zhuanlan.zhihu.com/p/669987669?utm_psn=1776651110843301888
https://zhuanlan.zhihu.com/p/669987669?utm_psn=1776651110843301888多核之后,CPU 的发展方向是什么?
 https://www.zhihu.com/question/20809971/answer/1678502542?utm_psn=1776935387489312768
https://www.zhihu.com/question/20809971/answer/1678502542?utm_psn=1776935387489312768Pytorch 显存管理机制与显存占用分析方法
torch.cuda.empty_cache() 调用,该调用会释放未分配的 Segment。PyTorch 提供了多种显存占用分析方法,包括内置 API、Snapshot 功能、nvidia-smi 工具和 torch.cuda.mem_get_info 函数,以帮助开发者监控和优化显存使用。Snapshot 功能能够记录 CUDA allocator 的显存消耗、调用堆栈和时间线,生成 .pickle 文件供分析。文章还提供了一个全连接网络训练的示例代码,展示了如何在训练过程中使用这些工具进行显存分析。通过这些方法,开发者可以更好地理解和管理 PyTorch 应用中的显存使用,从而提高 GPU 资源的利用率。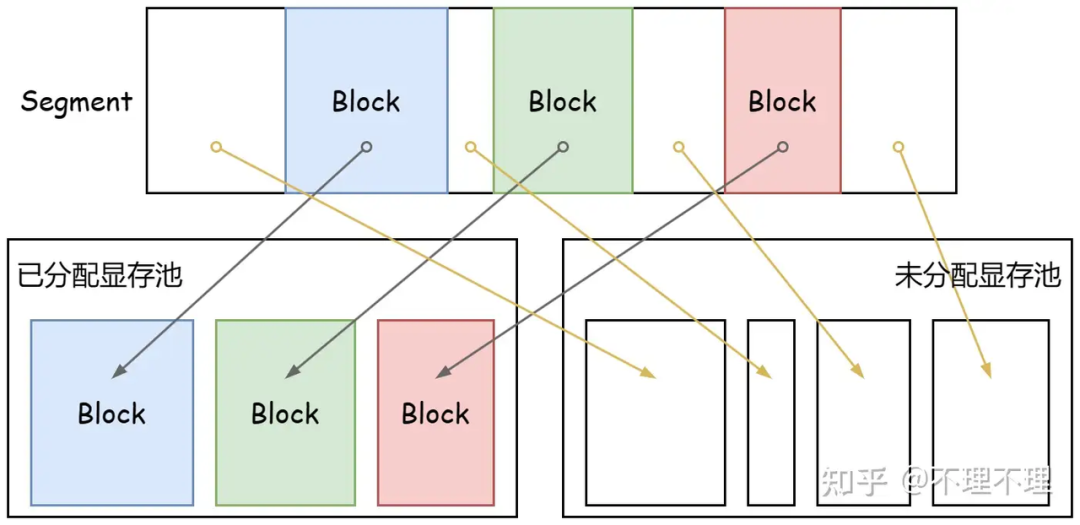 https://zhuanlan.zhihu.com/p/699254132?utm_psn=1776938336575778818
https://zhuanlan.zhihu.com/p/699254132?utm_psn=1776938336575778818用 Coze(扣子) 打造浏览器书签助手(上)
 https://mp.weixin.qq.com/s/4RH6C-M7zzd_6-34lhMwfQ
https://mp.weixin.qq.com/s/4RH6C-M7zzd_6-34lhMwfQCogVLM2

Khoj
 https://github.com/khoj-ai/khoj
https://github.com/khoj-ai/khoj原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15187.html