
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


论文
长上下文模型的上下文学习:深入探讨
 http://arxiv.org/abs/2405.00200v1
http://arxiv.org/abs/2405.00200v1野生对话:1M ChatGPT 在野外的交互日志
 http://arxiv.org/abs/2405.01470v1
http://arxiv.org/abs/2405.01470v1
将 Llama-3 的上下文在一夜之间扩展十倍
 http://arxiv.org/abs/2404.19553v1
http://arxiv.org/abs/2404.19553v1更好更快的大语言模型:通过多token预测
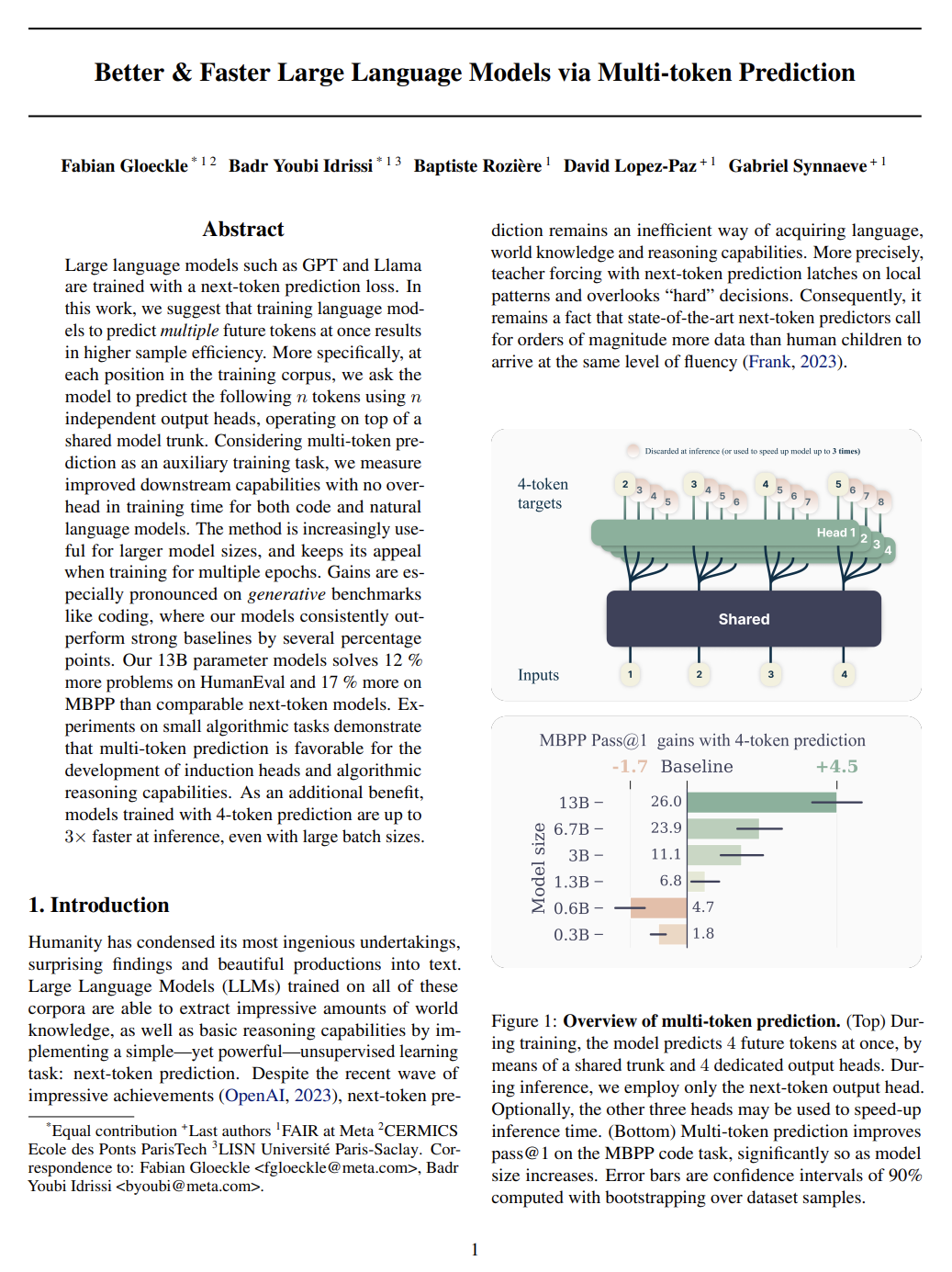 http://arxiv.org/abs/2404.19737v1
http://arxiv.org/abs/2404.19737v1迭代推理偏好优化
 http://arxiv.org/abs/2404.19733v1
http://arxiv.org/abs/2404.19733v1工作台:一个逼真工作场景中智能体的基准数据集
 http://arxiv.org/abs/2405.00823v1
http://arxiv.org/abs/2405.00823v1MANTIS:交织的多图像指令调优
 http://arxiv.org/abs/2405.01483v1
http://arxiv.org/abs/2405.01483v1基于 Transformer 的语言模型内部工作原理初探
 http://arxiv.org/abs/2405.00208v2
http://arxiv.org/abs/2405.00208v2
LLM Datasets
Chinese-LLaMA-Alpaca-3
InternVL Family
 https://github.com/OpenGVLab/InternVL
https://github.com/OpenGVLab/InternVLKAN
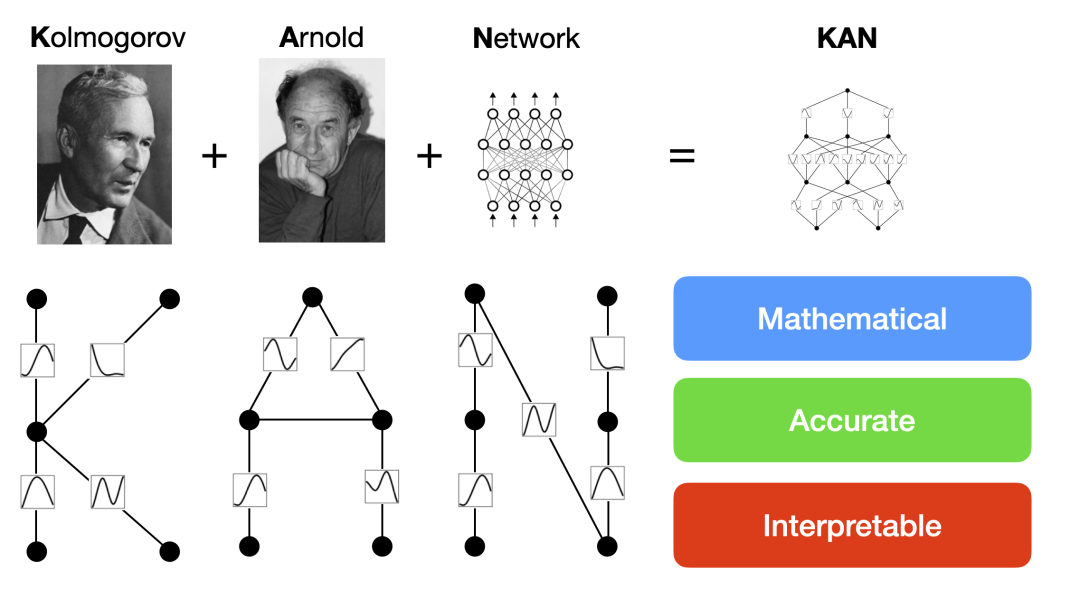 https://kindxiaoming.github.io/pykan/
https://kindxiaoming.github.io/pykan/Gigax
 https://github.com/GigaxGames/gigax
https://github.com/GigaxGames/gigaxReor

大模型日报16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15635.html