
欢迎观看大模型日报,进入大模型日报群和空间站(活动录屏复盘聚集地)请直接扫码。社群内除日报外还会第一时间分享大模型活动。


论文
Reka Core Flash, Edge:一系列强大的多模式语言模型
 http://arxiv.org/abs/2404.12387v1
http://arxiv.org/abs/2404.12387v1通过想象、搜索和批评实现LLM自我改进
 http://arxiv.org/abs/2404.12253v1
http://arxiv.org/abs/2404.12253v1MLCommons AI安全基准测试v0.5
 http://arxiv.org/abs/2404.12241v1
http://arxiv.org/abs/2404.12241v1OpenBezoar: 在混合指令数据上训练的便宜小巧的开放模型
 http://arxiv.org/abs/2404.12195v1
http://arxiv.org/abs/2404.12195v1多模型中的顺序组合泛化
 http://arxiv.org/abs/2404.12013v1
http://arxiv.org/abs/2404.12013v1TriForce:使用分层投机解码无损加速长序列生成
 http://arxiv.org/abs/2404.11912v1
http://arxiv.org/abs/2404.11912v1Welcome Llama 3
UniChat
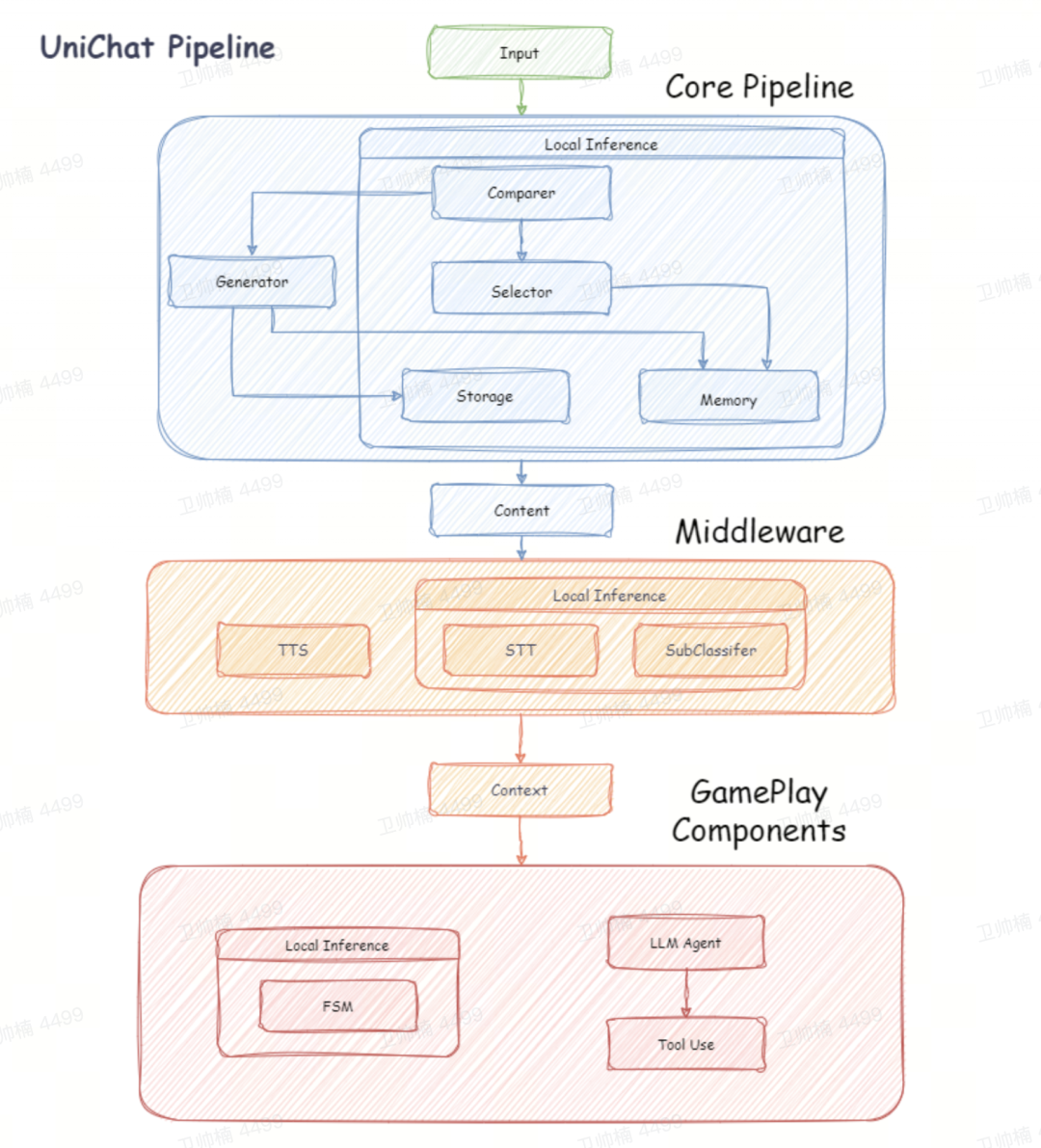 https://github.com/AkiKurisu/UniChat
https://github.com/AkiKurisu/UniChat
TriForce
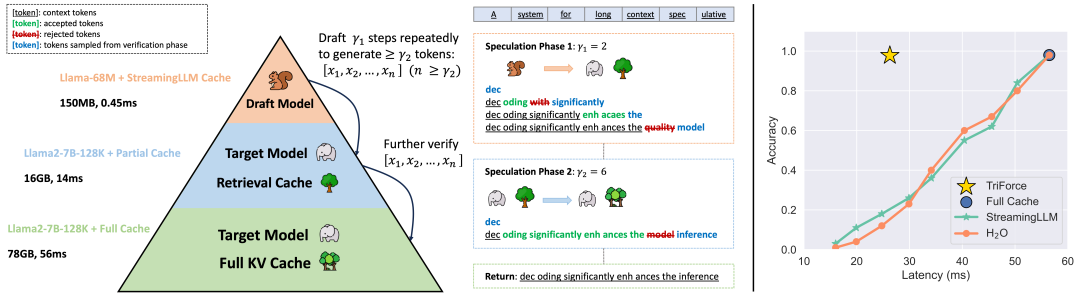 https://github.com/Infini-AI-Lab/TriForce
https://github.com/Infini-AI-Lab/TriForce
大模型日报16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/15961.html