
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
人类与大语言模型中的分歧创造力
 http://arxiv.org/abs/2405.13012v1
http://arxiv.org/abs/2405.13012v1扩散用于世界建模:Atari 中视觉细节的重要性
 http://arxiv.org/abs/2405.12399v1
http://arxiv.org/abs/2405.12399v1利用任务特定的考试生成自动评估检索增强语言模型
 http://arxiv.org/abs/2405.13622v1
http://arxiv.org/abs/2405.13622v1思维的温度:温度树在大语言模型中引发推理
 http://arxiv.org/abs/2405.14075v1
http://arxiv.org/abs/2405.14075v1九章3.0:通过训练小数据合成模型高效提升数学推理
 http://arxiv.org/abs/2405.14365v1
http://arxiv.org/abs/2405.14365v1优化人工智能工作负载的声明性系统
 http://arxiv.org/abs/2405.14696v1
http://arxiv.org/abs/2405.14696v1RoPE基于各种上下文长度的基础
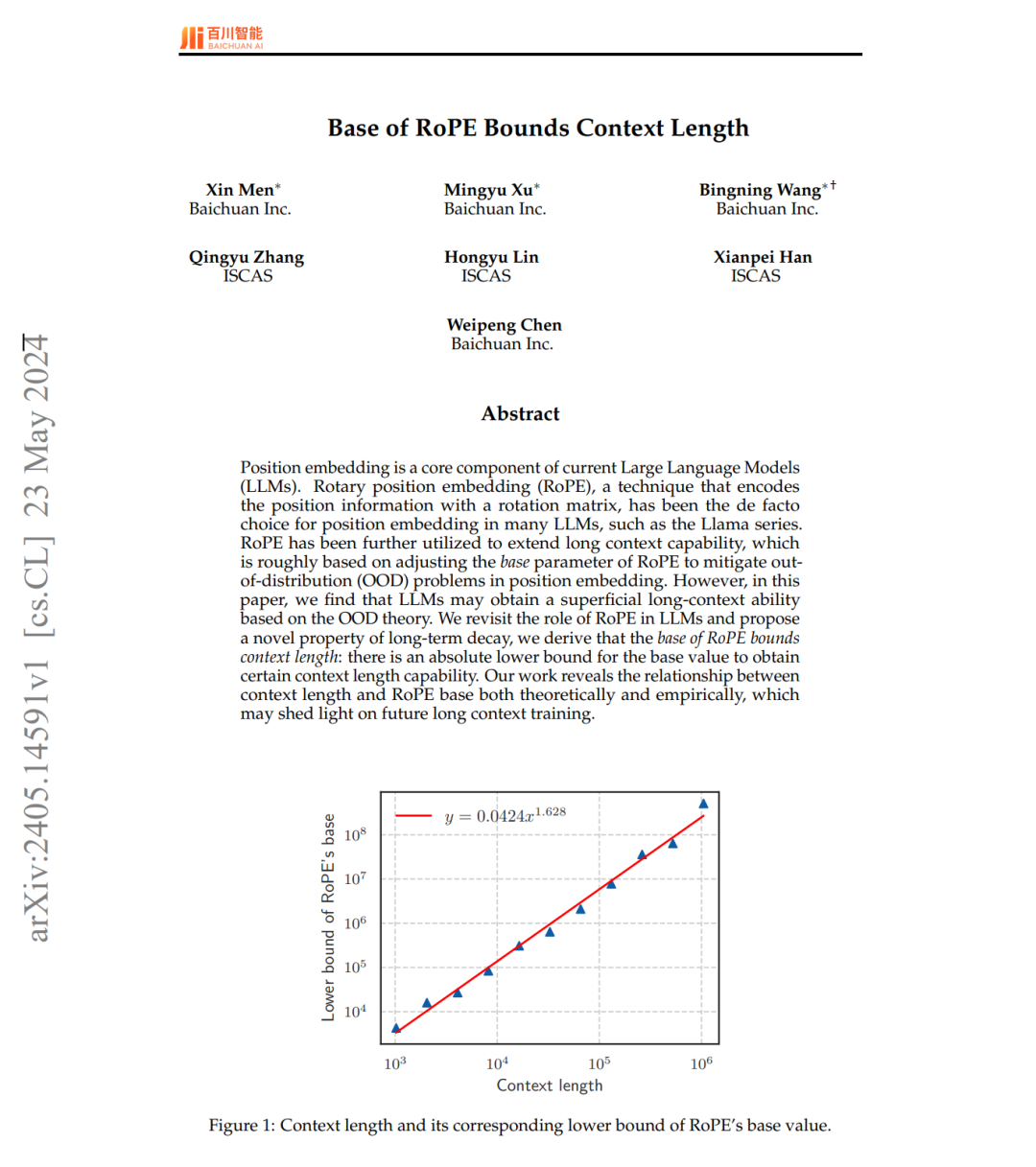 http://arxiv.org/abs/2405.14591v1
http://arxiv.org/abs/2405.14591v1DeepSeek-Prover: 通过大规模合成数据推进LLMs中的定理证明
 http://arxiv.org/abs/2405.14333v1
http://arxiv.org/abs/2405.14333v1Phi-3
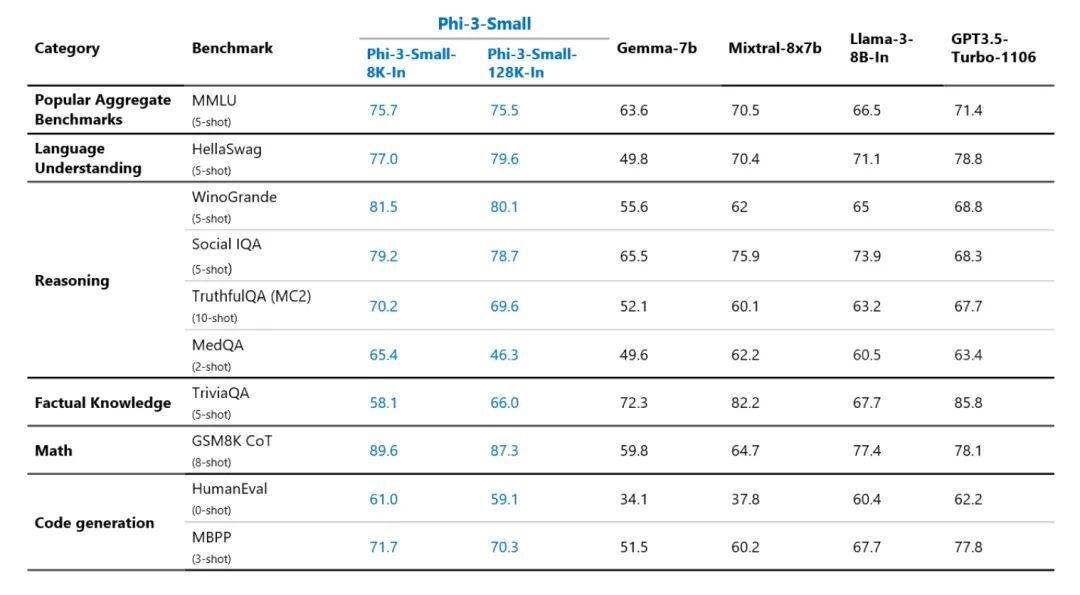 https://github.com/microsoft/Phi-3CookBook
https://github.com/microsoft/Phi-3CookBookPerplexica
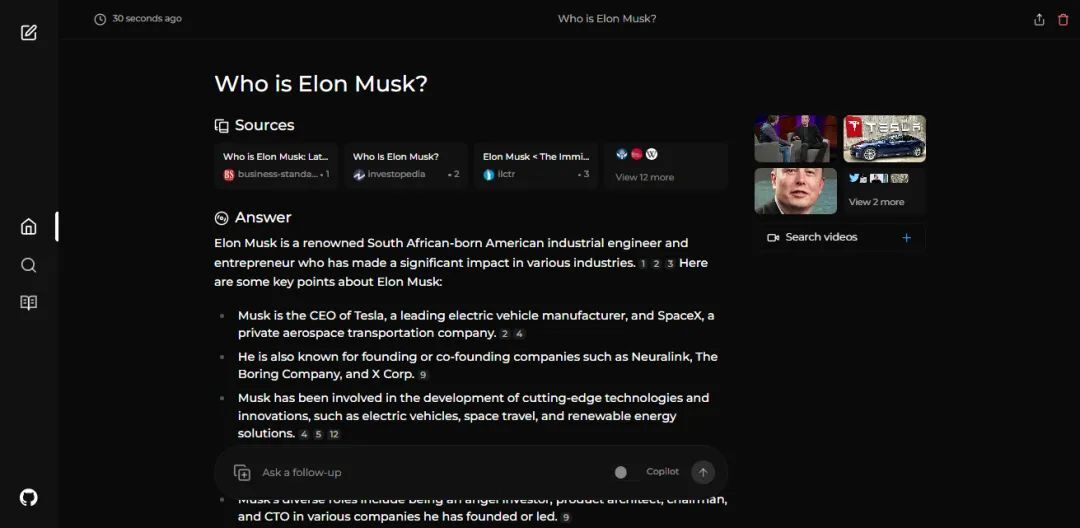 https://github.com/ItzCrazyKns/Perplexica
https://github.com/ItzCrazyKns/Perplexica原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15153.html