我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢 迎 大 家 一 起 交 流 !
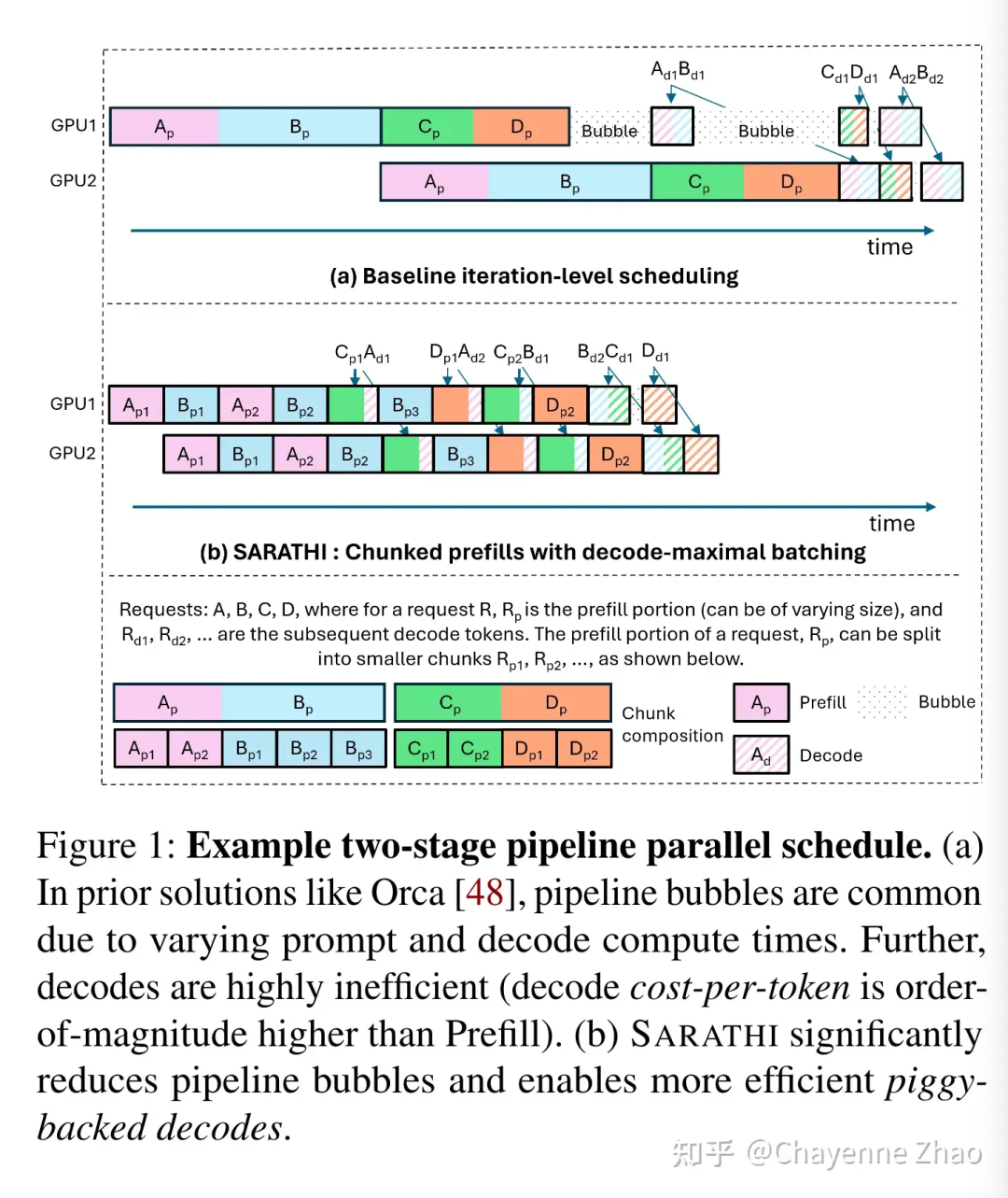
学习 LLM推理引擎基准测试常见错误 在推理优化的发展与比较过程中,基准测试至关重要。vLLM v0.6的发布展示了令人瞩目的性能进展,但在复现其结果时,发现了一些基准设置问题,记录这些错误以避免未来出现相同问题。 vLLM v0.6中的关键优化是多步调度器,通过将多个解码步骤分组以减少CPU开销,提升了吞吐量。但这显著增加了首字节时间(TTFT)和字节间延迟(ITL),对在线服务流体验造成不利影响。vLLM在ShareGPT数据集上的测试结果显示,TTFT增加了3倍,ITL增加了10倍,导致不流畅的流式体验。虽然vLLM整体E2E延迟略低,但未启用SGLang的平滑流式特性。 报告优化时应全面覆盖所有指标,vLLM博文仅提供TPOT指标,未准确反映流式体验,并忽视了ITL等关键指标。 vLLM博文中的图表y轴设定过大(8000ms),掩盖了低QPS情况下TTFT的显著差异,而这些差异对实际生产环境至关重要。在实际在线场景中,SGLang的TTFT降低了3倍,但图表未能反映这一结果。 vLLM在基准测试中未使用默认参数,而是对自身参数进行了调优(如多步调度器、GPU内存使用),但未对其他基线进行同等调优。重新运行测试后,稍微调整SGLang的超参数,结果表明其离线峰值吞吐量优于vLLM。 相关链接:https://x.com/zhyncs42/status/1832158129846677632 https://docs.google.com/document/u/0/d/1fEaaIQoRQLbevRu3pj1_ReOklHkoeE7ELqZJ3pnW-K4/mobilebasic?_immersive_translate_auto_translate=1#heading=h.ntrtei46qfj8 安利LinFusion,能单卡生成16K超高清图像 现代扩散模型,特别是那些使用基于Transformer 的UNet进行去噪的模型,严重依赖自注意力操作来处理复杂的空间关系,从而实现了出色的生成性能。然而,这种现有范式在生成高分辨率视觉内容时面临着显著挑战,原因是其时间和内存复杂度随着空间令牌数量的增加呈二次增长。为了解决这一限制,我们在本文中提出了一种新的线性注意力机制作为替代方案。具体来说,我们从最近引入的线性复杂度模型 开始探索,例如Mamba、Mamba2和Gated Linear Attention,并识别出两个关键特性——注意力归一化 和非因果推理,这些特性提高了高分辨率视觉生成的性能。基于这些见解,我们引入了一种广义的线性注意力范式 ,它作为多种流行线性令牌混合器的低秩近似。为了节省训练成本并更好地利用预训练模型,我们初始化了我们的模型并从预训练的StableDiffusion (SD)中提炼知识。我们发现,经过少量训练后,提炼出的模型LinFusion的性能与原始SD相当甚至更优,同时大大降低了时间和内存复杂度。在SD-v1.5、SD-v2.1 和SD-XL上的大量实验表明,LinFusion能够实现令人满意的零样本跨分辨率生成性能,能够生成如16K分辨率 的高分辨率图像。此外,它与预训练的SD组件高度兼容,如ControlNet和IP-Adapter ,无需进行适配。 https://zhuanlan.zhihu.com/p/718203486?utm_psn=1815733814737108992 基于 chunked prefill 理解 prefill 和 decode 的计算特性 在对 SGLang 服务器参数和功能的探索中,作者发现“分块预填充”(Chunked Prefilling)是 LLM 推理优化中的关键技术,尤其是在《SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills》这篇论文中。分块预填充方法将不同长度的提示分割为相同长度的块,以提高 GPU 利用率。虽然像 GPT 这样的 AI 模型错误地理解了分块和非分块预填充在数学上的等价性,但你发现分块预填充能够在预填充过程中产生的空闲时间(气泡)中插入解码请求,从而优化资源使用。 从技术上讲,预填充阶段并行处理所有 token,GPU 利用率很高,但在解码阶段,每次只生成一个 token,导致 GPU 利用率较低,主要受到内存访问的限制。通过将提示分块,减少了因重复读取 KV 缓存而导致的内存开销,同时复用了模型参数,使得解码过程从内存受限操作转变为计算受限操作,大幅提升了性能,解码时间最多可以减少 90%。然而,这需要在块大小上进行权衡:较小的块可以提高解码效率,但可能由于频繁的 I/O 操作而降低预填充效率。 Transformer 架构在预填充和解码阶段保持一致,但分块预填充通过减少流水线气泡,改善了整体模型并行性,通过平衡预填充和解码的优化目标,提高了模型的运行效率。 https://zhuanlan.zhihu.com/p/718715866?utm_psn=1815729196112175104 更适合 flash attenion 体质的长上下文训练方案
技术上,zigzag ring attention 具备三个核心优势:
精度问题:flash attention 输出的 bf16 精度较低,累计误差可达 1e-3,且修改为 fp32 需大规模源码改动。
varlen 版本低效:需将数据拆分为多份并进行 padding,导致 kernel 并行度下降,运行速度慢。
通信效率低:依赖点对点通信(p2p),而非更高效的集合通信(cc)。
为解决这些问题,作者参考了 llama3 团队的优化方案,采用 all-gather 模式先收集 key 和 value,再进行局部计算。这样减少了通信延迟并提高了 mask 适应性,虽然显存占用增多,但可以通过每次只 all-gather 一个 head 来缓解显存压力。 在 varlen 数据处理上,作者提出了基于 cu_seqlens 的改进方案,避免了 padding 和数据拆分,提高了效率。最后,反向计算采用 reduce scatter 操作,确保梯度计算的精度。 该方案已实现为 llama3_flash_attn_varlen_func ,实现细节在 GitHub 上公开,具备较好的精度和可用性。 https://zhuanlan.zhihu.com/p/718486708?utm_psn=1815729769813266432 “闭门造车”之多模态思路浅谈(三):位置编码 当前多模态LLM在位置编码方面尚未达成共识,不同模态(如文本、图像、视频)的位置表示维度不一致,导致难以统一处理。例如,文本是1D序列,图像是2D,视频是3D。尽管现有工作通常通过将所有模态压平并使用RoPE-1D解决问题,但这种方法缺乏优雅性,并且可能限制模型性能。 为了解决这一难题,作者提出了一种改进的RoPE-2D方案,称为RoPE-Tie-v2,能够在混合模态下统一使用二维位置编码,并在单模态下退化为RoPE-1D或RoPE-2D。同时,该方案确保了不同模态间的对称性和等价性,使得文本和图像的位置信息可以兼容处理。 RoPE-Tie-v2的核心思想是将文本的位置从1D提升到2D,与图像统一处理,同时保持向后兼容性,确保在单模态下能恢复原有的RoPE编码。对于视频等3D模态,该方案通过类似的扩展处理时间维度,但作者认为时间维度与空间维度不同,应该允许无约束的自回归生成视频,而不需提前确定帧数。 相比于先前的RoPE-Tie方案,RoPE-Tie-v2优化了图像内部位置的均匀性,并通过较大的位置跳跃实现模态隔离,使得多模态交互更加自然。该方案兼顾了对称性和等价性,但在实际效果上仍需进一步实验验证。 https://zhuanlan.zhihu.com/p/718711086?utm_psn=1815731087495802880 CUDA-MODE课程笔记 第11课: Sparsity 这节课主要介绍了PyTorch团队在稀疏性(Sparsity)方向的工作,特别是在GPU推理上的进展。稀疏性技术虽然冷门,但其核心思想是通过移除部分模型参数或者使用低比特数据类型,提升推理效率。PyTorch团队以前专注于CPU和边缘设备,现在随着生成式AI模型(如LLMs和Vision Transformers)规模的扩大,推理需要在GPU上进行。 Sparsity的关键流程包括模型训练、剪枝、精度恢复以及优化的Sparsity kernel的使用。技术核心是通过识别零值参数跳过不必要的计算。团队重点研究了几种稀疏性模式,包括非结构化稀疏性、半结构化稀疏性(如2:4模式)和块稀疏性。每种模式在性能与精度之间的平衡不同。GPU推理中,半结构化稀疏性能在保持相对精度的情况下提高计算速度。 课程还深入探讨了如何通过PyTorch结合稀疏性和量化来加速推理,特别是使用NVIDIA的cuSPARSELt库处理稀疏矩阵乘法。尽管理想情况下2倍加速,实际效果通常约为1.6倍,且当前在精度和性能之间仍面临挑战。 对话Andrej Karpathy,涉及自动驾驶、人形机器人、合成数据、AI认知、小模型、AI教育等话题
自动驾驶技术的进步,从早期PPT到实际应用的过渡。
技术与监管之间的差距及挑战,以及如何克服这些挑战。
特斯拉和Waymo在自动驾驶技术发展上所采用的不同策略。
在将人形机器人推向消费者市场之前,先在制造和仓库环境中进行sim2real的重要性。
transformer在AI研究中的变革性作用,特别是在处理大量数据和可扩展性方面。
合成数据生成在训练稳健模型中的作用,以及如何防止模型崩溃。
关于人类与AI合作的未来以及这种合作可能带来的社会和技术影响。
使用AI创造个性化学习体验的可能性,以及如何使教育更具吸引力和可接受性。
重新评估传统教育结构的必要性,以便更好地为个人应对未来的挑战。
讨论了基础学科(如数学、物理和计算机科学)在培养批判性思维技能方面的重要性。
最后强调了技术的持续演变,以及它对交通运输、机器人技术、认知增强和教育等生活各个方面的潜在重大影响。
screenpipe screenpipe 是一个开源的屏幕和音频捕捉库,帮助开发者构建基于个人数据的定制化 AI 应用。它提供了一个可靠的数据流,用户只需点击一个按钮就可以在后台持续捕捉屏幕和音频输入/输出数据。 https://github.com/mediar-ai/screenpipe code2prompt Code2Prompt 是一个强大的命令行工具,它可以将用户的整个代码库转换为一个全面 Markdown 格式,使得大型语言模型(LLM)更容易理解项目的上下文。它希望可以简化开发人员与 LLM 之间的交互,以进行代码分析、文档编写和改进任务。 https://github.com/raphaelmansuy/code2prompt
— END —
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/09/13079.html