
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


学习
奥创纪元:当推荐系统遇到大模型LLM
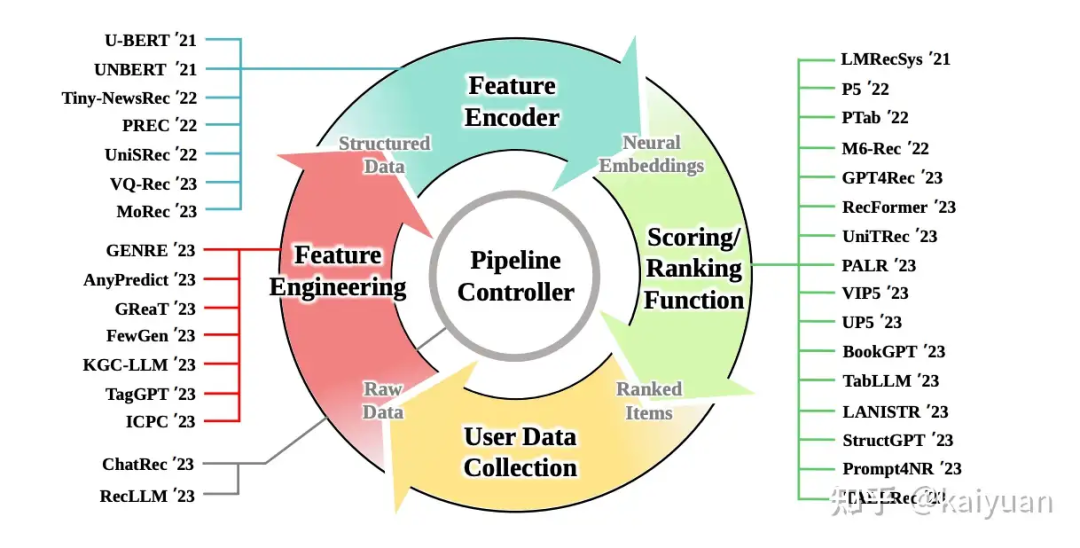 https://zhuanlan.zhihu.com/p/668673674
https://zhuanlan.zhihu.com/p/668673674GPU 利用率低常见原因分析及优化
-
数据加载:采用多进程并行读取、启用提前加载机制、使用共享内存 pin_memory,确保数据与计算资源同城,选择高性能存储介质,合并小文件。 -
数据预处理:简化预处理逻辑,使用 GPU 加速,如 Nvidia DALI 库。 -
模型保存:减少保存频率,避免 CPU 成为瓶颈。 -
指标计算:简化 loss计算,抽样上报指标。 -
日志打印:减少打印频率,避免频繁 CPU-GPU 切换。
DistributedDataParallel进行数据并行。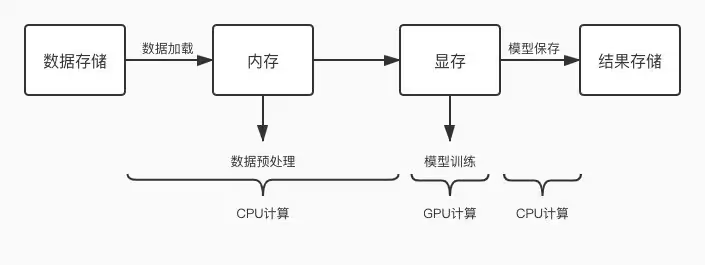 https://zhuanlan.zhihu.com/p/410244780
https://zhuanlan.zhihu.com/p/410244780Agent的九种设计模式(图解+代码)
 https://zhuanlan.zhihu.com/p/692971105
https://zhuanlan.zhihu.com/p/692971105全面探究英伟达GPU SM内CUDA core-Tensor core能否同时计算?(上篇)
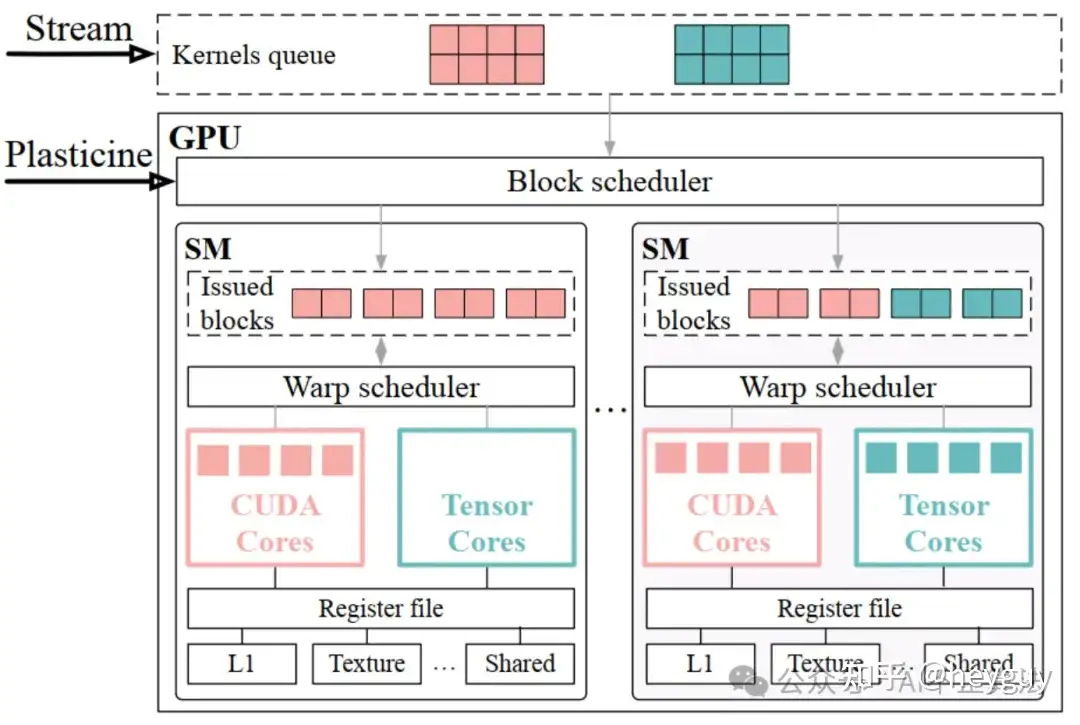 https://zhuanlan.zhihu.com/p/697000619
https://zhuanlan.zhihu.com/p/697000619全面探究GPU SM内CUDA core-Tensor core能否同时计算?(下篇)
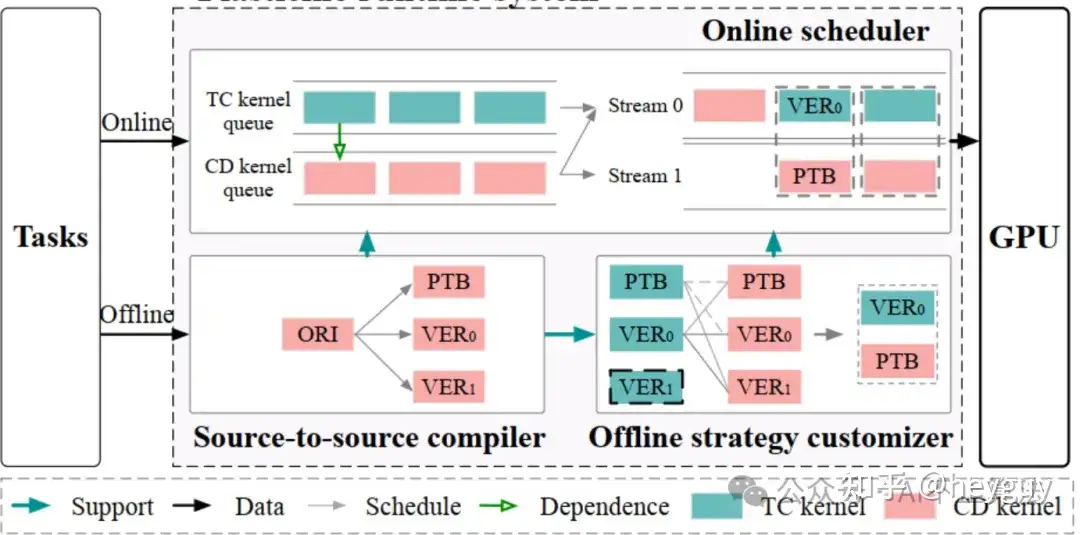 https://zhuanlan.zhihu.com/p/698572611
https://zhuanlan.zhihu.com/p/698572611陪伴机器人:未来家庭新成员
 https://mp.weixin.qq.com/s/6MiGyuT2oQc73DhqV0F9WQ
https://mp.weixin.qq.com/s/6MiGyuT2oQc73DhqV0F9WQRAGapp
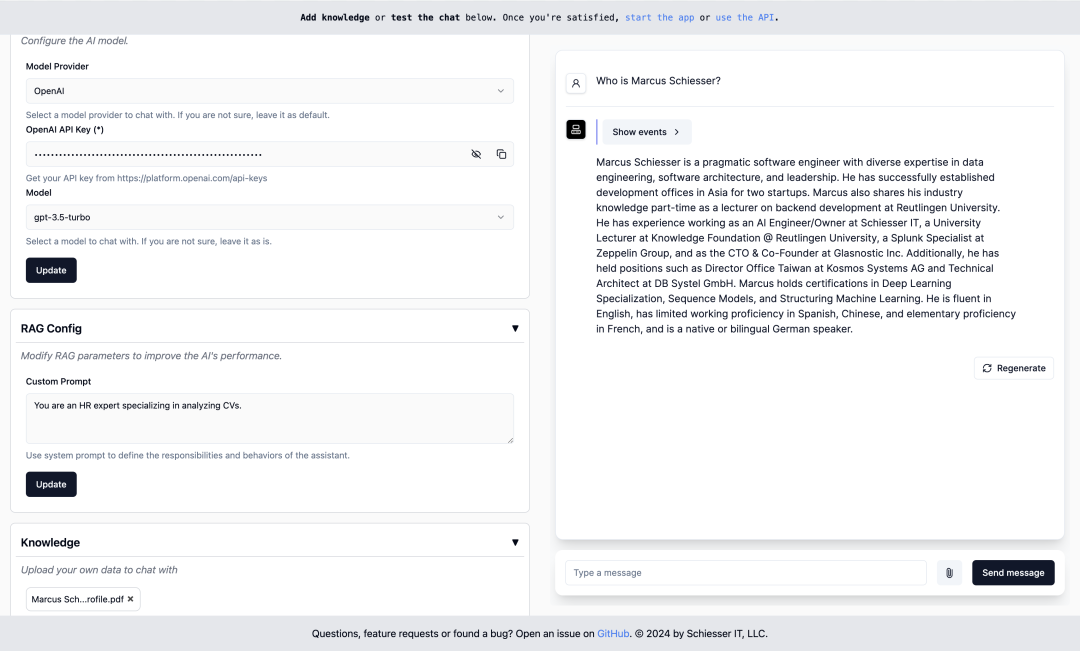 https://github.com/ragapp/ragapp
https://github.com/ragapp/ragappKsanaLLM —— 一念 LLM
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15125.html