
欢迎观看大模型日报,如需进入大模型日报群和空间站请直接扫码。社群内除日报外还会第一时间分享大模型活动。


论文
Megalodon:具有无限上下文长度的高效LLM预训练和推理
 http://arxiv.org/abs/2404.08801v1
http://arxiv.org/abs/2404.08801v1TransformerFAM:反馈注意力即为工作记忆
 http://arxiv.org/abs/2404.09173v1
http://arxiv.org/abs/2404.09173v1
压缩线性表达智能
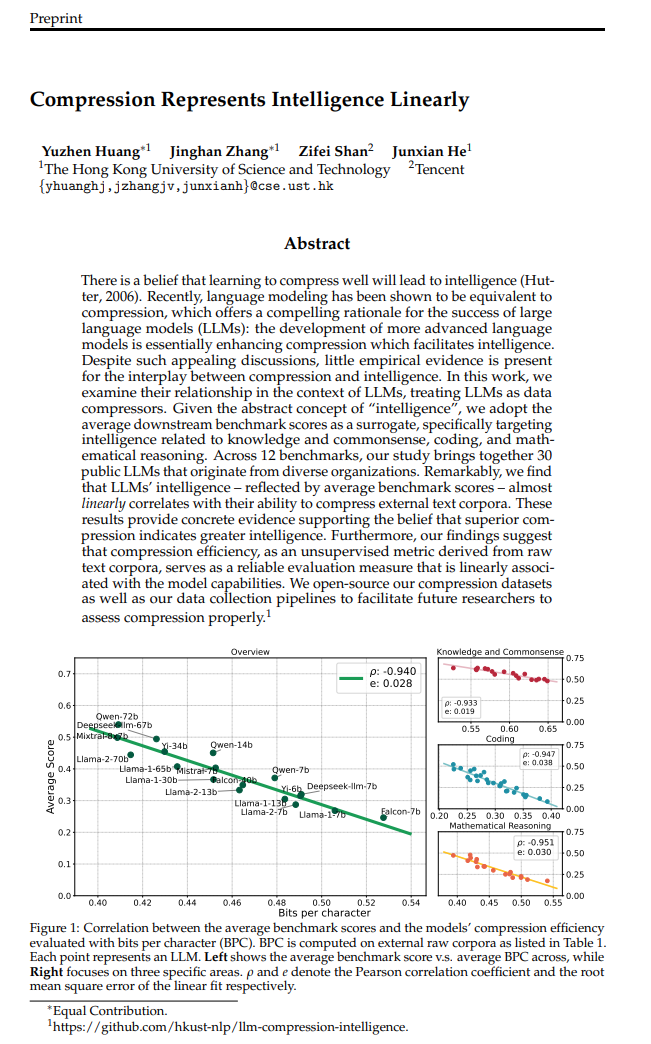 http://arxiv.org/abs/2404.09937v1
http://arxiv.org/abs/2404.09937v1大语言模型在上下文中的召回是与提示相关的
 http://arxiv.org/abs/2404.08865v1
http://arxiv.org/abs/2404.08865v1关于多模态大语言模型的推测性解码
 http://arxiv.org/abs/2404.08856v1
http://arxiv.org/abs/2404.08856v1状态空间模型中状态的错觉
 http://arxiv.org/abs/2404.08819v1
http://arxiv.org/abs/2404.08819v1英语是新的编程语言吗?伪码工程呢?
 http://arxiv.org/abs/2404.08684v1
http://arxiv.org/abs/2404.08684v1一种合成数据生成模型的评估框架
 http://arxiv.org/abs/2404.08866v1
http://arxiv.org/abs/2404.08866v1大语言模型中的故障token:分类分类与有效检测
MiniCPM-V和OmniLMM
-
MiniCPM-V 2.8B:可在终端设备上部署的先进多模态大模型。最新发布的 MiniCPM-V 2.0 可以接受 180 万像素的任意长宽比图像输入,实现了和 Gemini Pro 相近的场景文字识别能力以及和 GPT-4V 相匹的低幻觉率。 -
OmniLMM-12B:相比同规模其他模型在多个基准测试中具有领先性能,实现了相比 GPT-4V 更低的幻觉率。
 https://github.com/OpenBMB/MiniCPM-V
https://github.com/OpenBMB/MiniCPM-V
llm-universe——适合小白的入门教程
-
大模型简介,何为大模型、大模型特点是什么、LangChain 是什么,如何开发一个 LLM 应用,针对小白开发者的简单介绍; -
如何调用大模型 API,本节介绍了国内外知名大模型产品 API 的多种调用方式,包括调用原生 API、封装为 LangChain LLM、封装为 Fastapi 等调用方式,同时将包括百度文心、讯飞星火、智谱AI等多种大模型 API 进行了统一形式封装; -
知识库搭建,不同类型知识库文档的加载、处理,向量数据库的搭建; -
构建 RAG 应用,包括将 LLM 接入到 LangChain 构建检索问答链,使用 Streamlit 进行应用部署 -
验证迭代,大模型开发如何实现验证迭代,一般的评估方法有什么;

大模型日报16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/16043.html