
欢迎观看大模型日报,如需进入大模型日报群和空间站请直接扫码。社群内除日报外还会第一时间分享大模型活动。


论文
OSWorld:在真实计算机环境中为开放式任务基准测试多模态智能体
 http://arxiv.org/abs/2404.07972v1
http://arxiv.org/abs/2404.07972v1蒙特卡罗树搜索与玻尔兹曼探索
 http://arxiv.org/abs/2404.07732v1
http://arxiv.org/abs/2404.07732v1使用更少token预训练小型基础LLM
 http://arxiv.org/abs/2404.08634v1
http://arxiv.org/abs/2404.08634v1ChatGPT是否改变了学术写作风格?
 http://arxiv.org/abs/2404.08627v1
http://arxiv.org/abs/2404.08627v1LLM中Token的理论
 http://arxiv.org/abs/2404.08335v1
http://arxiv.org/abs/2404.08335v1减小差异的零阶方法用于微调语言模型
 http://arxiv.org/abs/2404.08080v1
http://arxiv.org/abs/2404.08080v1STORM
 https://github.com/stanford-oval/storm
https://github.com/stanford-oval/stormMagicTime
 https://github.com/PKU-YuanGroup/MagicTime
https://github.com/PKU-YuanGroup/MagicTimeMaxKB
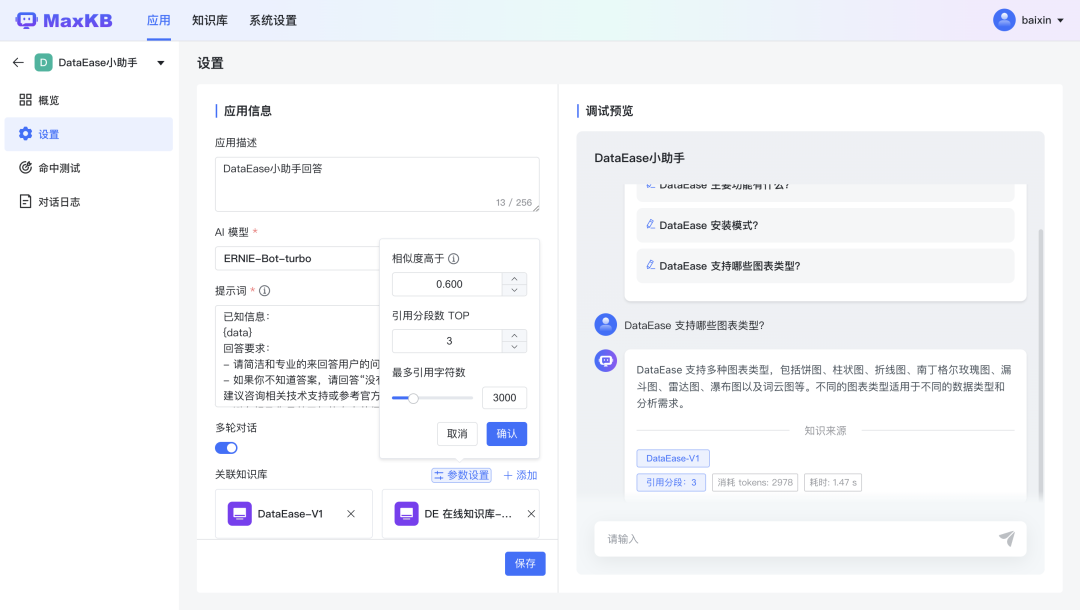 https://github.com/1Panel-dev/MaxKB
https://github.com/1Panel-dev/MaxKB
大模型日报16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/16081.html