
欢迎观看大模型日报,如需进入大模型日报群和空间站请直接扫码。社群内除日报外还会第一时间分享大模型活动。


学习
AI 集群基础设施 InfiniBand 详解
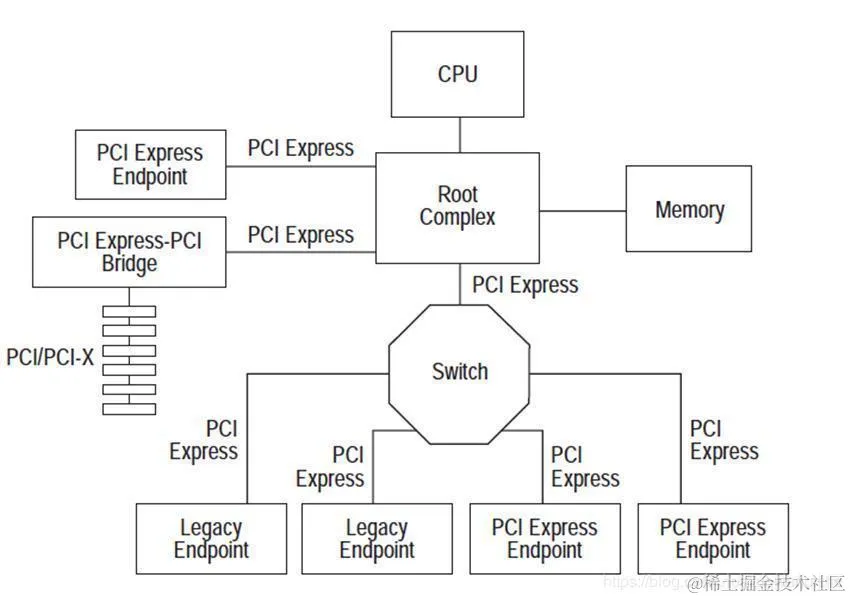 https://mp.weixin.qq.com/s/2phqowTOr4Hf3K9H-8W48w
https://mp.weixin.qq.com/s/2phqowTOr4Hf3K9H-8W48wMoE-SFT:混合专家模型在大模型中的应用
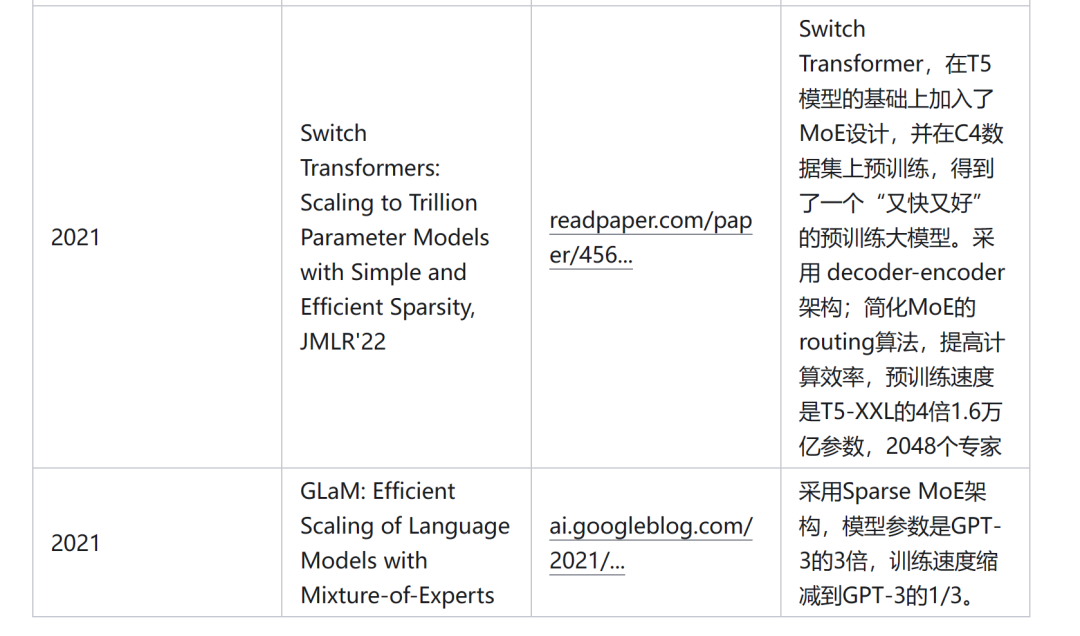 https://zhuanlan.zhihu.com/p/691402411?utm_psn=1762839367150735360
https://zhuanlan.zhihu.com/p/691402411?utm_psn=1762839367150735360Nvidia Blackwell系列GPU性能及总成本分析:B100 vs B200 vs GB200
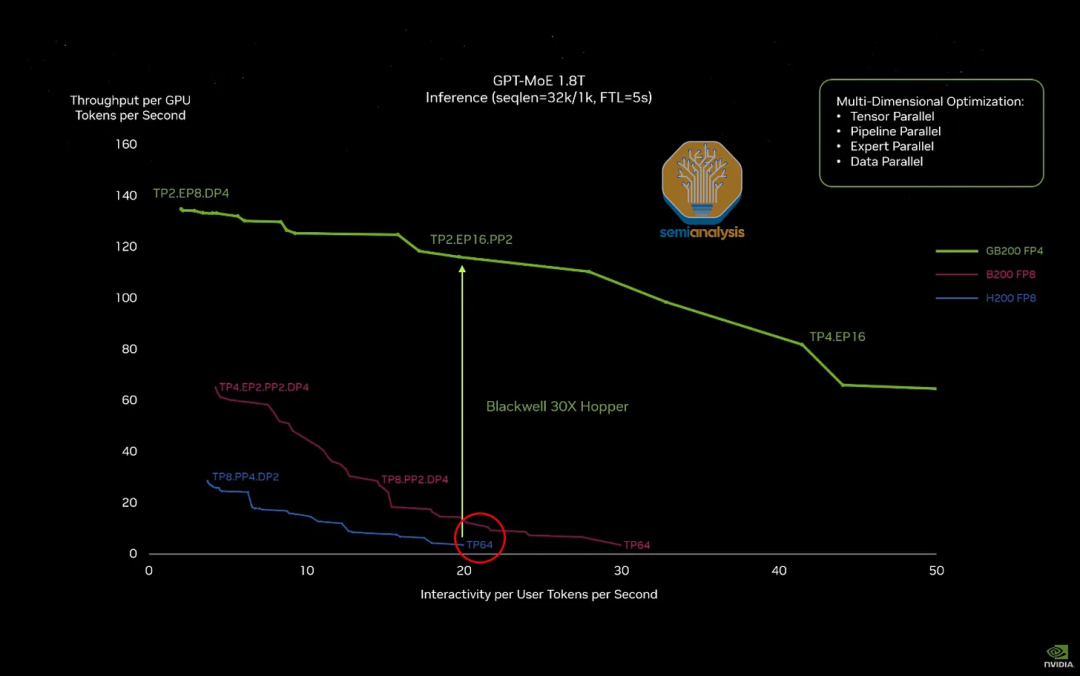 https://www.semianalysis.com/p/nvidia-blackwell-perf-tco-analysis?utm=
https://www.semianalysis.com/p/nvidia-blackwell-perf-tco-analysis?utm=行主序与列主序矩阵:Mojo和NumPy的性能分析
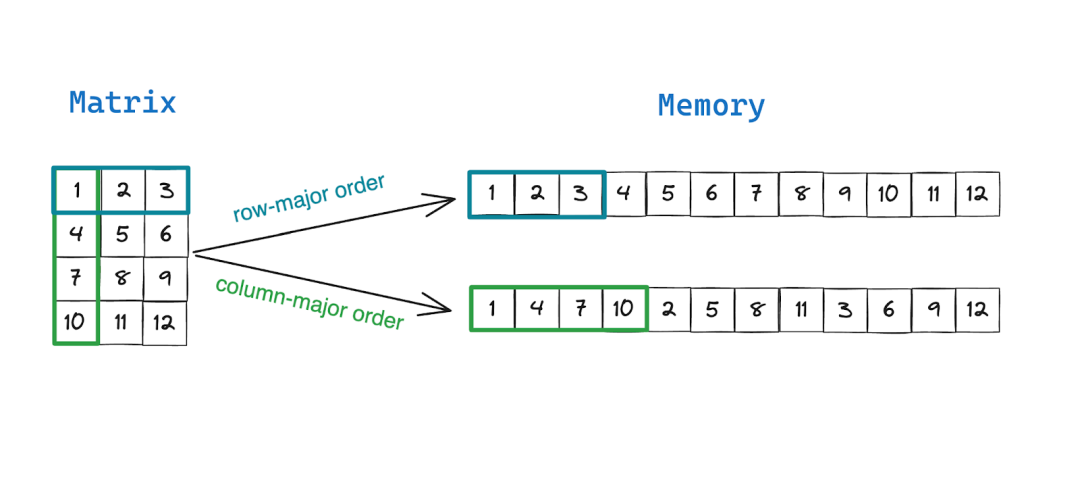 https://www.modular.com/blog/row-major-vs-column-major-matrices-a-performance-analysis-in-mojo-and-numpy
https://www.modular.com/blog/row-major-vs-column-major-matrices-a-performance-analysis-in-mojo-and-numpy多GPU分布式推理技术细节解析
Spring AI
aiXcoder-7B
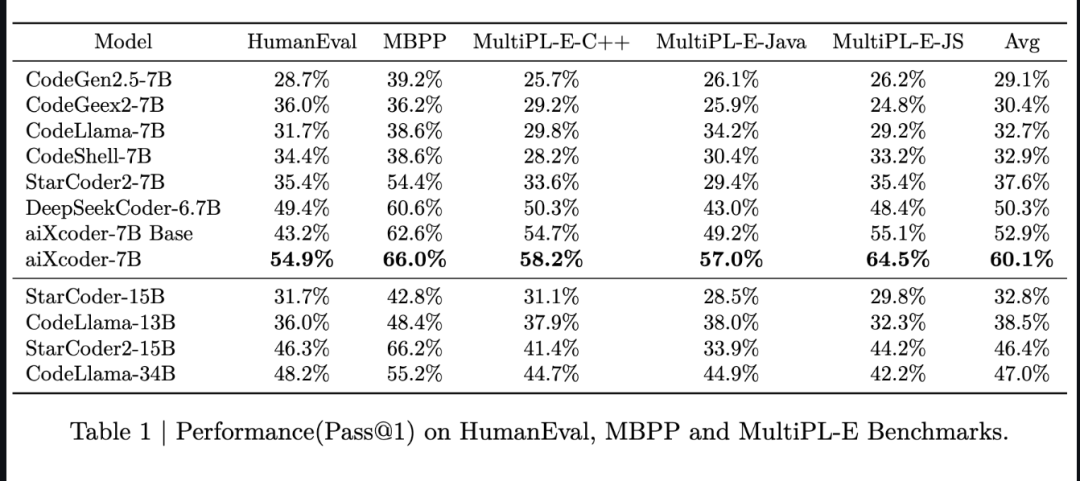 https://github.com/aixcoder-plugin/aiXcoder-7B
https://github.com/aixcoder-plugin/aiXcoder-7Bparler-tts
 https://github.com/huggingface/parler-tts
https://github.com/huggingface/parler-ttsCopilot-For-Security

大模型日报16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/16124.html