
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


学习
零一万物面向万卡集群的AI基础设施建设
 https://mp.weixin.qq.com/s/gBF2eK6eNfyHjoTRGu6XTA
https://mp.weixin.qq.com/s/gBF2eK6eNfyHjoTRGu6XTALlama3.1–post-training要点一览
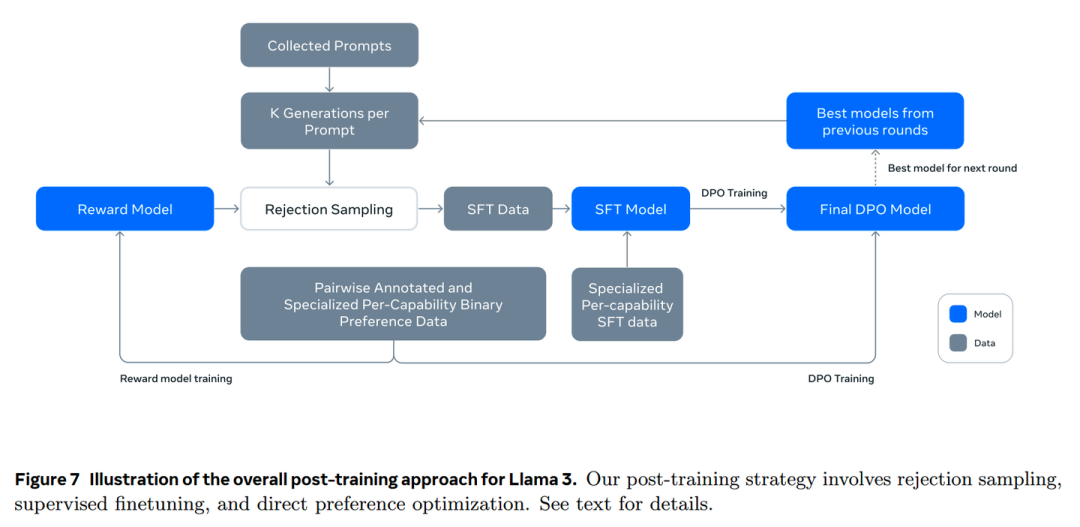 https://zhuanlan.zhihu.com/p/711295334?utm_psn=1801036979611254784
https://zhuanlan.zhihu.com/p/711295334?utm_psn=1801036979611254784在单个节点上使用Snowflake的内存优化AI堆栈对Llama 3.1 405B进行微调
lora_r 为 64,减少了内存需求。此外,他们实施了 FP8 量化,进一步降低了内存占用。他们还采用了类似 ZeRO-3 的权重分片策略,并通过针对性的参数卸载到 CPU 来解决激活内存和其他内存开销的问题。这些技术细节的优化使得在 8 x H100-80GB 主机上进行模型微调成为可能,大大降低了对硬件资源的需求,并且这些优化已经开源,也将集成到 Snowflake Cortex 的微调功能中。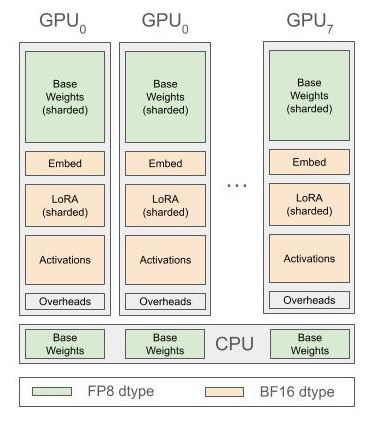 https://www.snowflake.com/engineering-blog/fine-tune-llama-single-node-snowflake/
https://www.snowflake.com/engineering-blog/fine-tune-llama-single-node-snowflake/vTensor: Flexible Virtual Tensor Management for Efficient LLM Serving
 https://zhuanlan.zhihu.com/p/711174278?utm_psn=1801031207485583361
https://zhuanlan.zhihu.com/p/711174278?utm_psn=1801031207485583361Physics of Language Models(面向应用层读者)
 https://zhuanlan.zhihu.com/p/711391378?utm_psn=1801032178664103936
https://zhuanlan.zhihu.com/p/711391378?utm_psn=1801032178664103936[Triton] Kernel Optim
人形机器人:历史回顾,进展梳理(技术&应用&挑战)和未来展望
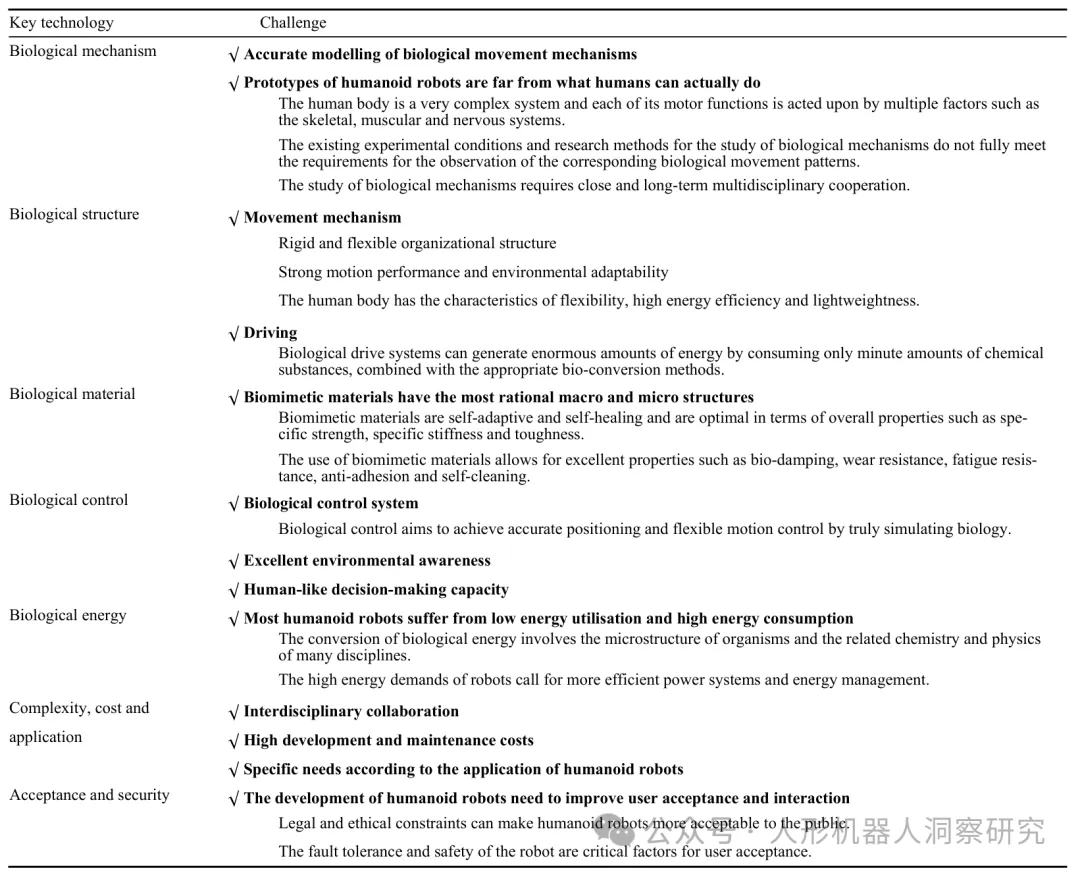 https://mp.weixin.qq.com/s/Ylk-pFc_7gQ7PGEcvP4pxg
https://mp.weixin.qq.com/s/Ylk-pFc_7gQ7PGEcvP4pxgllm-colosseum
Lollms
 https://github.com/ParisNeo/lollms
https://github.com/ParisNeo/lollms原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/07/13968.html