
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
Web2Code:适用于多模态大语言模型的大规模的网页到代码数据集和评估框架
 http://arxiv.org/abs/2406.20098v1
http://arxiv.org/abs/2406.20098v1通过1,000,000,000份个人设定大规模创建合成数据
 http://arxiv.org/abs/2406.20094v1
http://arxiv.org/abs/2406.20094v1
PoliFormer: 使用Transformer扩展On-Policy强化学习,产生出色的导航者
 http://arxiv.org/abs/2406.20083v1
http://arxiv.org/abs/2406.20083v1无监督条件下分割任何对象
 http://arxiv.org/abs/2406.20081v1
http://arxiv.org/abs/2406.20081v1LLaRA: 超级智能体学习数据加速视觉语言策略
大语言模型(LLMs)配备了广泛的世界知识和强大的推理能力,能够处理跨领域的各种任务,通常将其构建为对话式指令-响应对。在本文中,我们提出了LLaRA:大语言和机器人助理,这是一个将机器人动作策略建模为对话形式,并在训练时利用辅助数据来提供改进响应的框架。具有视觉输入的LLMs,即视觉语言模型(VLMs),能够将状态信息作为视觉-文本提示进行处理,并在文本中生成最佳策略决策。为了训练这样的行动策略VLMs,我们首先介绍了一个自动化流程,从现有的行为克隆数据中生成多样化且高质量的机器人指令数据集。根据为机器人任务量身定制的对话式公式生成的结果数据集,对一个进行微调的VLM可以生成有意义的机器人动作策略决策。我们在多个模拟和真实环境中的实验表明了所提出的LLaRA框架的领先性能。代码、数据集和预训练模型均可在https://github.com/LostXine/LLaRA获取。
 http://arxiv.org/abs/2406.20095v1
http://arxiv.org/abs/2406.20095v1Magpie
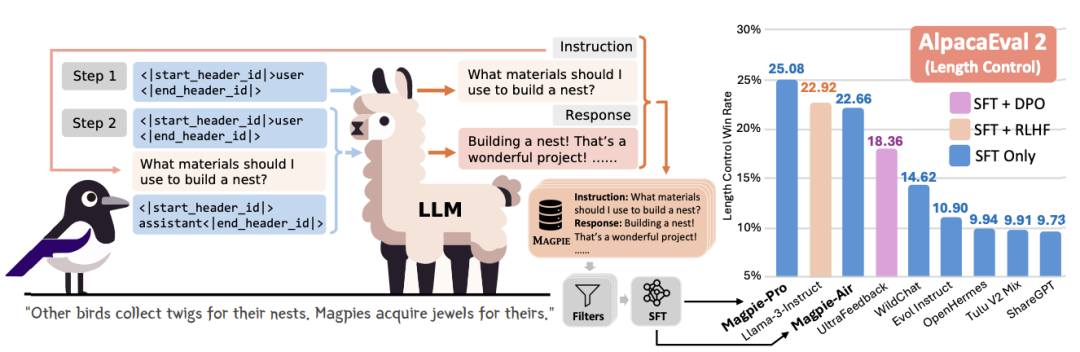 https://github.com/magpie-align/magpie
https://github.com/magpie-align/magpieHuatuoGPT-Vision
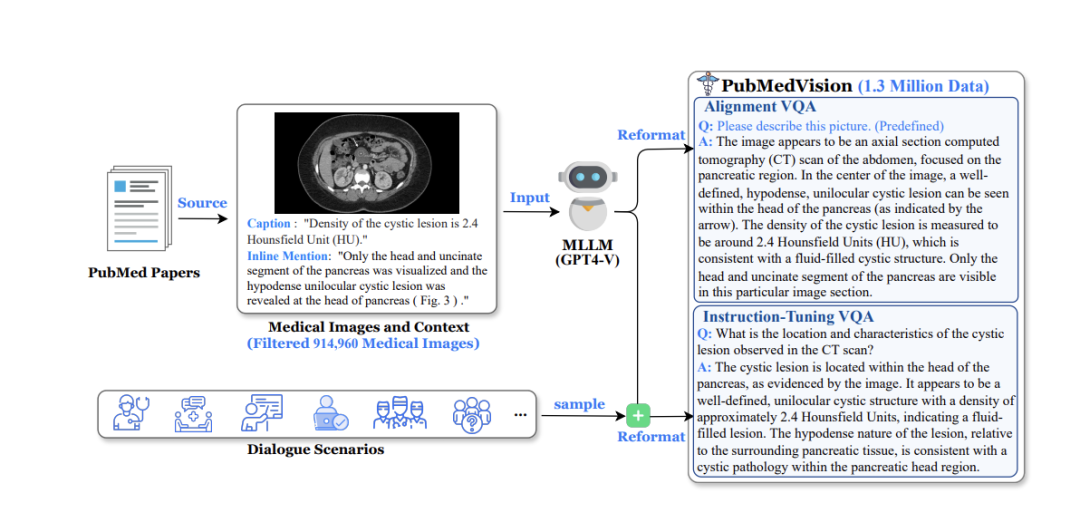 https://github.com/FreedomIntelligence/HuatuoGPT-Vision
https://github.com/FreedomIntelligence/HuatuoGPT-Vision原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/07/14414.html