


微软最近推出了一种名为“Visual ChatGPT”的新模型,它结合了不同类型的视觉基础模型 (VFM),包括 Transformers、ControlNet 和 Stable Diffusion with ChatGPT。该系统支持与 ChatGPT 进行超越语言的交互。
此连接允许通过聊天发送消息并在聊天期间接收图像,同时还可以注入一系列可视化模型提示来编辑图像。如下是通过使用Visual ChatGPT实现图片的配置和更改的Demo:

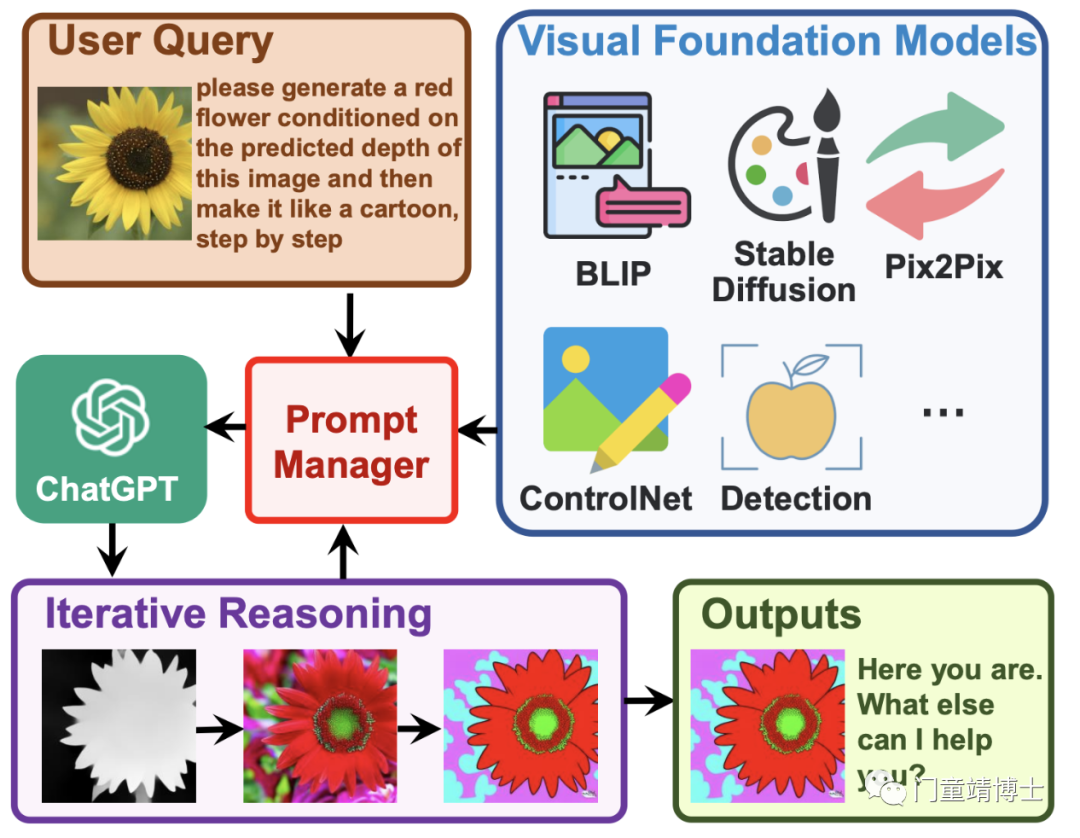
作为 ChatGPT 和 VFM 之间的桥梁,提示管理器(Prompt Manger)明确告知 ChatGPT 每个 VFM 的功能并指定必要的输入输出格式。
它将各种类型的视觉信息(例如 png 图像、深度图像和遮罩矩阵)转换为语言格式以帮助 ChatGPT 理解。同时管理不同 VFM 的历史记录、优先级和冲突。
通过使用提示管理器,ChatGPT 可以有效地利用 VFM 并以迭代的方式接收他们的反馈,直到满足用户的要求或达到结束条件。
这使用户不仅可以使用文本,还可以使用图像与 ChatGPT 进行交互。
此外,用户还可以通过不同人工智能模型的多步骤协作,提出复杂的图像问题或视觉编辑。用户还可以要求对结果进行更正和反馈。这个是系统架构图:
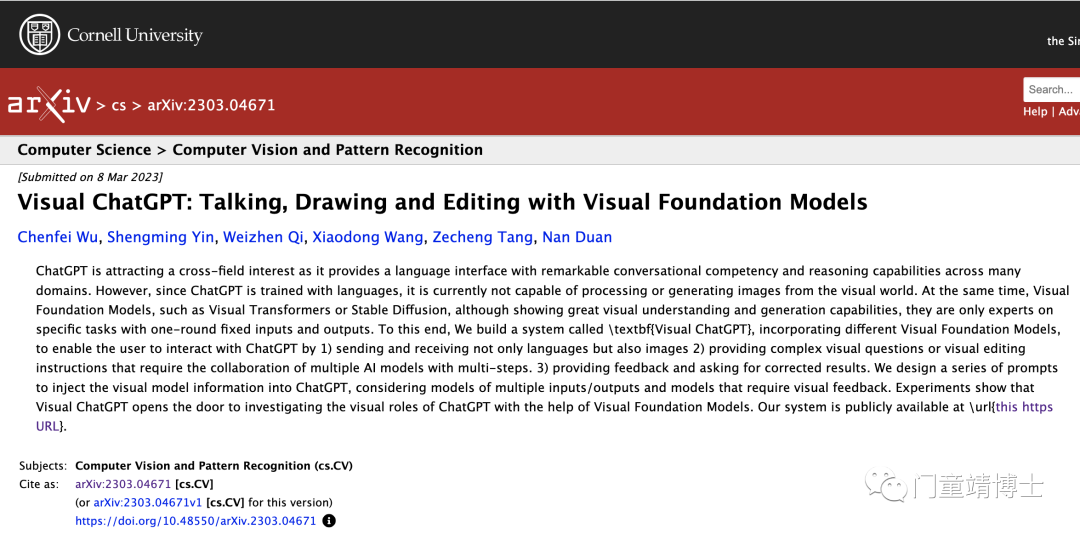
这篇论文是3月8号提交的,而现在这个工具已经可以使用了,可见Arxiv的评审效率之高!
那么,效果到底如何,不如上手一试:
在开始如下步骤前,需要安装并运行Anaconda,然后进入Terminal开始如下操作:
1. 创建环境
# create a new environment
conda create -n visgpt python=3.8

2. 激活环境
# activate the new environment
conda activate visgpt
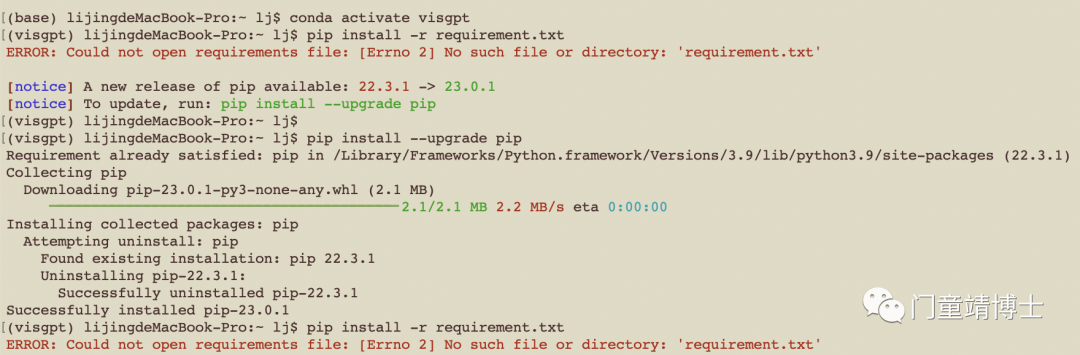
3. 准备环境, 期间会出现如下问题,最后通过stackoverflow解决了该问题。
# prepare the basic environments
pip install -r requirement.txt


4. 下载模型,似乎没法进行下去…
# download the visual foundation models
bash download.sh
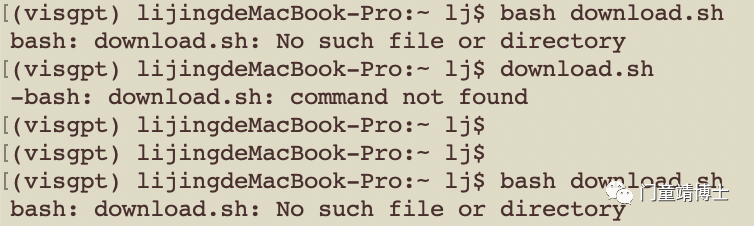
查了一下该Github issue确实存在一些问题:

于是暂时另辟蹊径,通过Google Colab来进行配置 (人家的资源就是比本地的稳当…)
具体直接进入Github,通过Google Colab按照如下步骤,即可完成安装
https://github.com/goldboy225/ChatGPT-for-Research/blob/main/Copy_of_visual_chatgpt_colab.ipynb
终于大功告成!
可以在本地执行,也可以提供远程URL运行
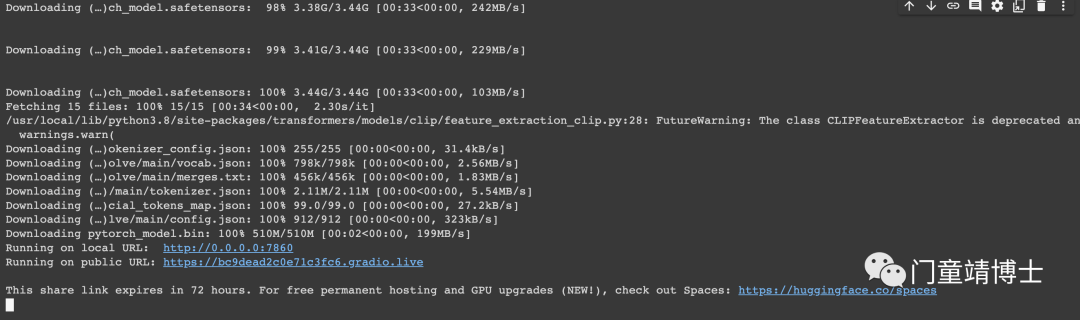
接下来开始表演Visual ChatGPT的表演:
输入“generate a young girl walking on the beach”

输入“generate a little girl reading a book“

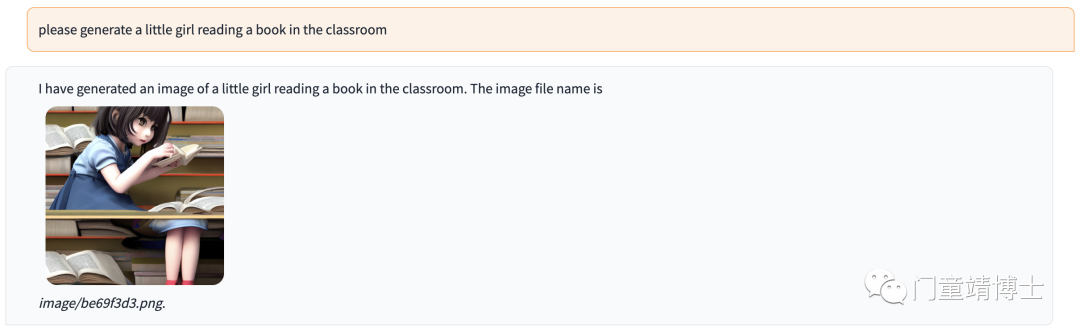
输入“generate a little girl reading a book in the classroom“
输入“please generate a Chinese little girl reading a book”

这里就开个头,更多玩法,大家可以自己尝试~
建议通过Google Colab来配置运行,毕竟免费的服务不用可惜了,具体步骤参考如下Github:
https://github.com/goldboy225/ChatGPT-for-Research/blob/main/Copy_of_visual_chatgpt_colab.ipynb
参考文献:
[1] https://github.com/microsoft/visual-chatgpt
[2] https://arxiv.org/abs/2303.04671
[3]https://github.com/goldboy225/ChatGPT-for-Research/blob/main/Copy_of_visual_chatgpt_colab.ipynb
[4] https://analyticsindiamag.com/microsoft-unveils-visual-chatgpt-a-chatgpt-for-images/
原创文章,作者:门童靖博士,如若转载,请注明出处:https://www.agent-universe.cn/2023/03/12486.html