
特别活动!


欢迎观看大模型日报,如需进入大模型日报群和空间站请直接扫码。社群内除日报外还会第一时间分享大模型活动。

论文
RecurrentGemma:超越Transformer以提高效率的开放语言模型
 http://arxiv.org/abs/2404.07839v1
http://arxiv.org/abs/2404.07839v1JetMoE: 用10万美元达到Llama2性能
 http://arxiv.org/abs/2404.07413v1
http://arxiv.org/abs/2404.07413v1Rho-1: 并非所有 token 都是你所需的
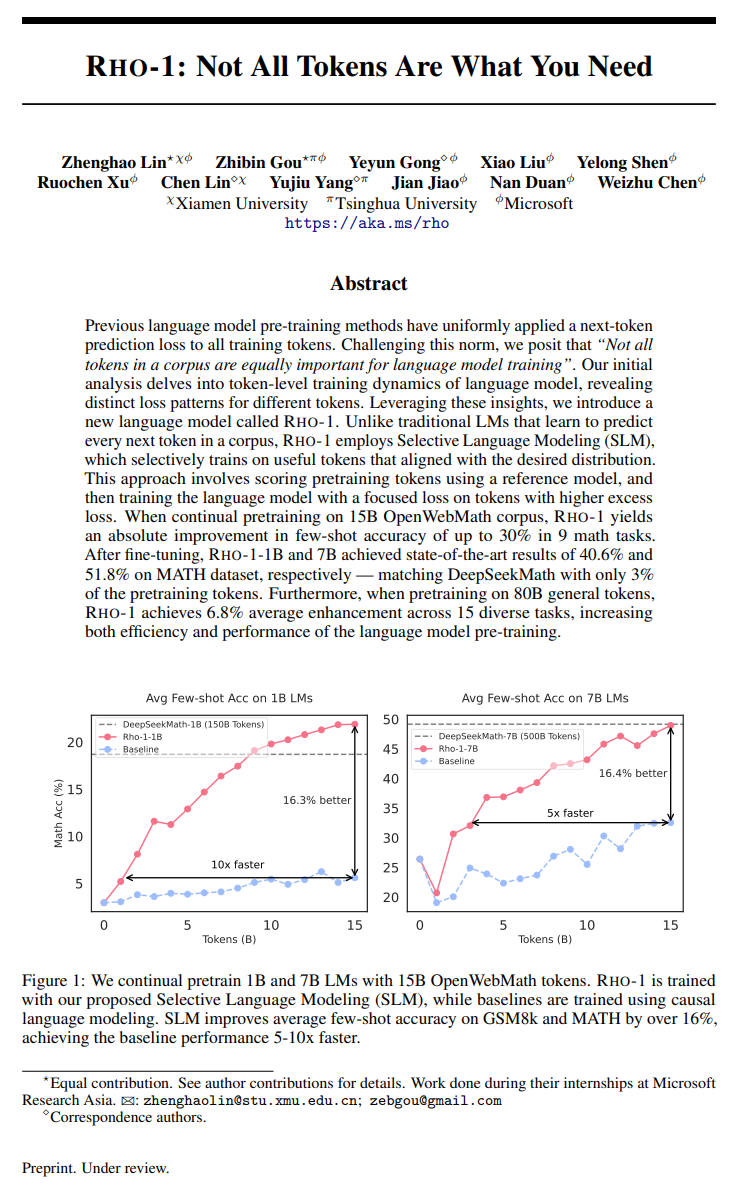 http://arxiv.org/abs/2404.07965v1
http://arxiv.org/abs/2404.07965v1语言模型合成数据的最佳实践和经验教训
 http://arxiv.org/abs/2404.07503v1
http://arxiv.org/abs/2404.07503v1HGRN2:具有状态扩展的门控线性RNN
 http://arxiv.org/abs/2404.07904v1
http://arxiv.org/abs/2404.07904v1ResearchAgent:利用大语言模型在科学文献中进行迭代研究思想生成
 http://arxiv.org/abs/2404.07738v1
http://arxiv.org/abs/2404.07738v1为什么小型语言模型表现不佳?通过Softmax瓶颈研究语言模型饱和
 http://arxiv.org/abs/2404.07647v1
http://arxiv.org/abs/2404.07647v1从单词到数字:你的大语言模型在给定上下文示例时悄悄成为了一个能干的回归器
 http://arxiv.org/abs/2404.07544v1
http://arxiv.org/abs/2404.07544v1llm.c
Realmdreamer
 https://realmdreamer.github.io/
https://realmdreamer.github.io/recurrentgemma-2b

大模型日报16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/16165.html