
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


学习
预训练一个72b模型需要多久?
 https://mp.weixin.qq.com/s/E0OIgufVW8dm-fRhlRoA6A
https://mp.weixin.qq.com/s/E0OIgufVW8dm-fRhlRoA6A3D DRAM 集成 AI 处理:一项可能取代现有 HBM 的新技术
 https://zhuanlan.zhihu.com/p/714967226?utm_psn=1808194402641928194
https://zhuanlan.zhihu.com/p/714967226?utm_psn=1808194402641928194使用 Llama.cpp 或 Gemini 的 API 强制 JSON 输出的教程
Nsight Compute 使用指南
 https://zhuanlan.zhihu.com/p/715022552?utm_psn=1808193403386744833
https://zhuanlan.zhihu.com/p/715022552?utm_psn=1808193403386744833Survey of Deep Learning AcceleratorsSurvey of Deep Learning Accelerators
 https://zhuanlan.zhihu.com/p/714927573?utm_psn=1808192899151716352
https://zhuanlan.zhihu.com/p/714927573?utm_psn=1808192899151716352大模型微调炼丹心得十问
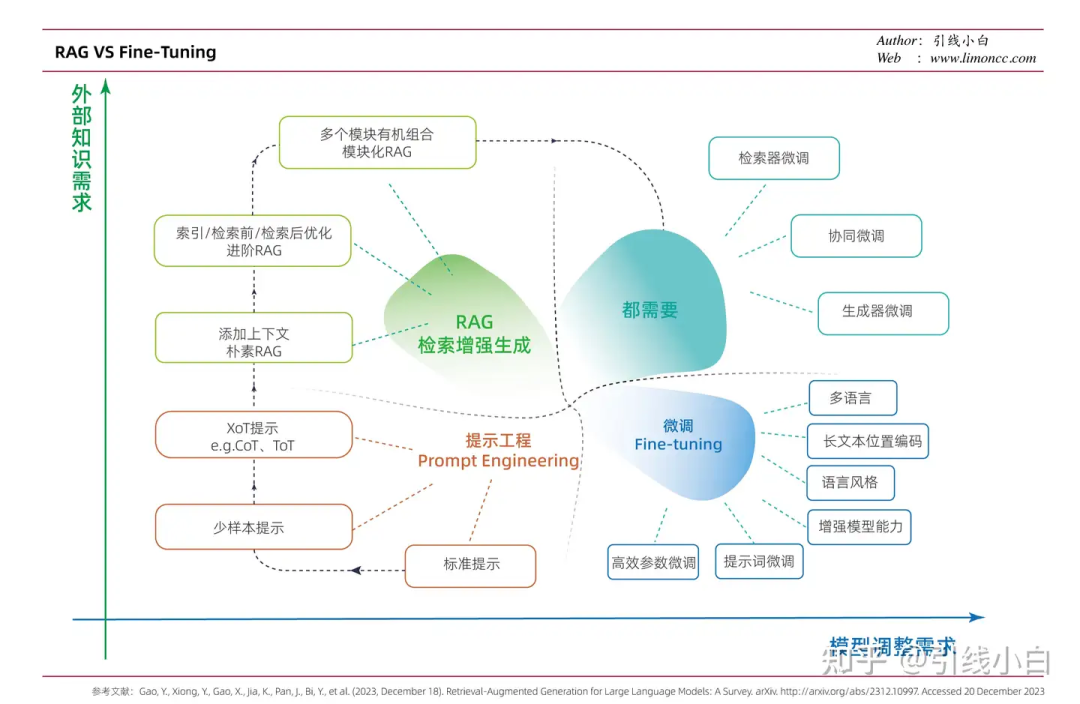 https://zhuanlan.zhihu.com/p/704809979?utm_psn=1808193035047141376
https://zhuanlan.zhihu.com/p/704809979?utm_psn=1808193035047141376我没有大模型经验,可以给个机会吗?
nous
 https://github.com/TrafficGuard/nous
https://github.com/TrafficGuard/nous原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/08/13566.html