

以下以一篇关于机器学习在计算机网络安全领域的文章写作为例:
一,首先从摘要(Abstract)着手
二,接下来看下文章标题 (Title)
三,如何根据Results来进行Discussion
四,如何生成相关工作文献(Related Works)
五,如何生成该主题文章的提纲(Outline)
六,需要多少数据集来验证模型(Dataset)
七,能否从实验结果中提取方法论(Methodology)
一,首先从Abstract着手:

总字符数为1242,那么假设摘要的字数需要限制在900以内~

给ChatGPT下指令“shorten to 900 characters:” 并带上相应的文字

ChatGPT返回如下对应的文字,大致浏览一遍发现,语句流畅,并且重要的信息基本都在,比如Idea是什么,方法是什么,怎么实现的,结果如何,解决了什么问题等。
此外,检查一下文字数量为861,同时基本满足了字数要求。

二,接下来看下文章标题 (Title)
基于上述摘要,让ChatGPT给出5建议的标题,输入“suggest 5 titles for this paper”,反馈如下,可见几个核心词汇都出现在如下几个标题当中,比如 early detection, IoT botnets, edge, machine learning,可以根据自己的文章写作重点,选择其中的标题。

当然你也可以继续询问,看是否有更好的标题。

上述标题似乎都有点中庸,那么我们也可以尝试调皮一点的标题,通过“more creative titles please”,Guardian Angel, Botnet Hunter, Empowering, Stay ahead of the game, Safeguarding,这些词明显要更具活力一些,这对于吸引读者和编辑的注意力来说,是非常值得尝试的标题。

三,如何根据results来进行Discussion?
Discussion是文章的核心,也是相对比较难入手的一部分。如下是该文章的results, 原文章总共分为四个部分,Scanning activity detection performance, Bot-CnC communication detection performance, robustness test, and runtime performance of EDIMA.




现在将结果给到ChatGPT,“discuss these results” 看看他是如何分析和讨论的:

该文章的results部分比较长,所以ChatGPT反馈too long, 那么接下来,进一步将几个部分分解开来做尝试。

Result 1:

GhatGPT反馈的结果对上述的测试结果做了一个基本的总结,没有数据相关的描述

此外,与原文的discussion做了大概的比较,结果发现ChatGPT所生成的discussion与原文的discussion基本不太一样。
原因:生成的discussion主要讨论几个机器学习模型做了哪些事情,而原文的第一部分的discussion是讨论为何用机器学习模型,而不用基于规则的DPI检测方式(因为开销比较大),可见原文的discussion是基于整个结果,即4个results而得出的discussion, 而刚才的测试只输入了result 1,因此结果不同也是合理的。


另外取一篇文章来进行测试,原文章总共有三个明确的results,作者对每一个result从small screen, medium screen 和 large screen 分别进行了讨论。

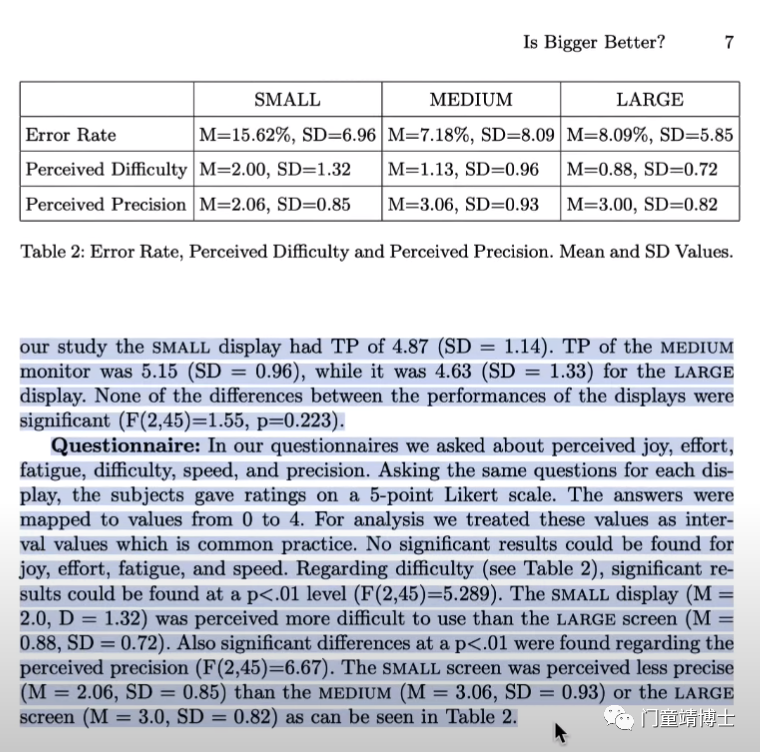


ChatGPT反馈如下,他将所有的结果统一在一个段落讨论了

为了达到分别讨论的效果,对ChatGPT重新进行询问“discuss the results for the small screen”

同理,对ChatGPT重新进行询问“discuss the results for the medium screen”, “discuss the results for the large screen”


四, 如何生成相关工作文献
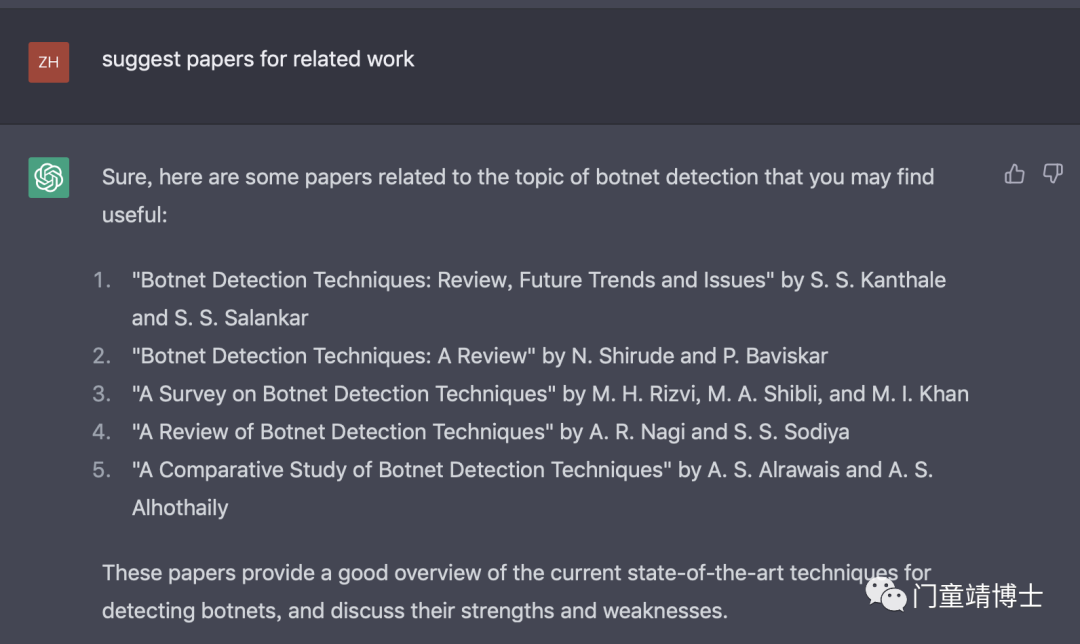
直接向ChatGPT询问 “suggest papers for related work”, 返回了关于botnet detection techniques 的survey 和 review文献。
由于都是综述类文献,那么可以继续追问,实验型文献,似乎ChatGPT不清楚我想要搜索的领域,所以并没有想要的文献,但提出了相应的解决方案。
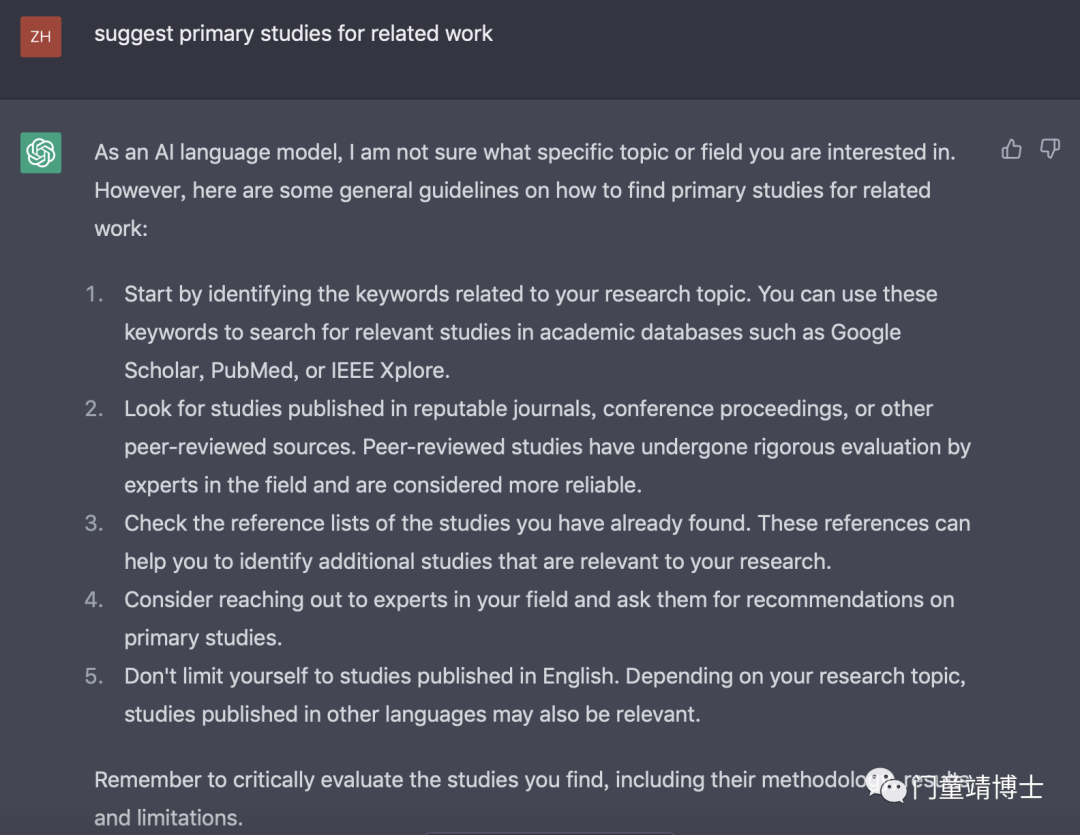
进一步明确搜索领域 “botnet detection using machine learning methods”

五,如何生成该主题文章的提纲
基于上述主题,让ChatGPT直接生成文章的提纲,基本把关于该主题该有的章节全部涵盖进去了


六,需要多少数据集来验证模型
ChatGPT的回复如下,根据实际情况而定,但一般为了支持多样性,至少要两个数据集,比如原因包括避免overfitting, 同时建议cross-validation来提高模型的泛化能力等。

进一步询问是否有建议的数据集来验证botnet detection model?

那么,请建议一下接下来的工作,数据集多样性,更新的机器学习算法,与现实环境集成,验证更高级攻击下的模型可用性,以及和同行对比以验证其优越性…

上述回复稍显general,能否有更具体的ideas,让我们继续 “suggest 5 more creative ideas”… 很明显,ideas更为具体了…

七,能否从实验结果中提取方法论呢?
能否从results中提取方法论的指导步骤…




以上均为实际实验所得,有兴趣的同学可以按照此思路继续探索,同时也会有
新的发现,也相信能够激发写作和实验灵感。
参考文献:
[1] https://github.com/goldboy225/ChatGPT-for-Research
[2] https://www.youtube.com/watch?v=tEdM9e_ycFU&t=9s
[3] https://www.youtube.com/watch?v=B9m-aV51Xdo
原创文章,作者:门童靖博士,如若转载,请注明出处:https://www.agent-universe.cn/2023/02/12545.html
