


刚好最近在整理ChatGPT的一些伦理问题,打算梳理一下类似ChatGPT等AI工具或者AI平台的几大伦理问题,计划写一个系列的文章。
这里先从偏见(Bias)开始,文章不长,只是表达一些自己的所读、所践和所想,留下一些文字,以备将来不时之需。

ChatGPT是否会产生偏见或歧视?
随着人工智能技术的快速发展,AI模型如ChatGPT也越来越广泛地应用于各个领域。然而,与其它技术一样,AI模型可能会存在偏见或歧视问题。
如果ChatGPT对女性或少数族裔的求职候选人推荐率相对较低,这可能是由于训练数据本身存在性别或种族偏见,或者使用某些非强相关特征(例如是否已婚、出生地等)来做出决策,而这些特征本身可能存在偏见或与性别、种族等个人因素相关联。

偏见问题属于ChatGPT和AI的伦理问题之一,它对个人、组织乃至整个社会来说至关重要,因为它们会影响模型的准确性、公平性和可信度。因此,我们需要通过不断地监测和调整来确保AI模型不会受到任何偏见的影响。
偏见可能发生在模型从开发至使用过程的各个阶段。AI模型从创建到运行大致分为三个阶段,包含数据获取和预处理、模型训练和验证、以及模型与用户交互。
一方面,用于训练模型的数据存在偏差。例如,如果数据集包含关于一个组的数据多于另一个组的数据,则该模型可能会学习偏向于该组而不是其他组。
另一方面,模型中使用的算法也可能存在偏差。例如,有明显偏差的决策边界或分配给不同特征的权重相差较大。这可能会导致模型产生有偏见的结果,偏向于一组而不是另一组。
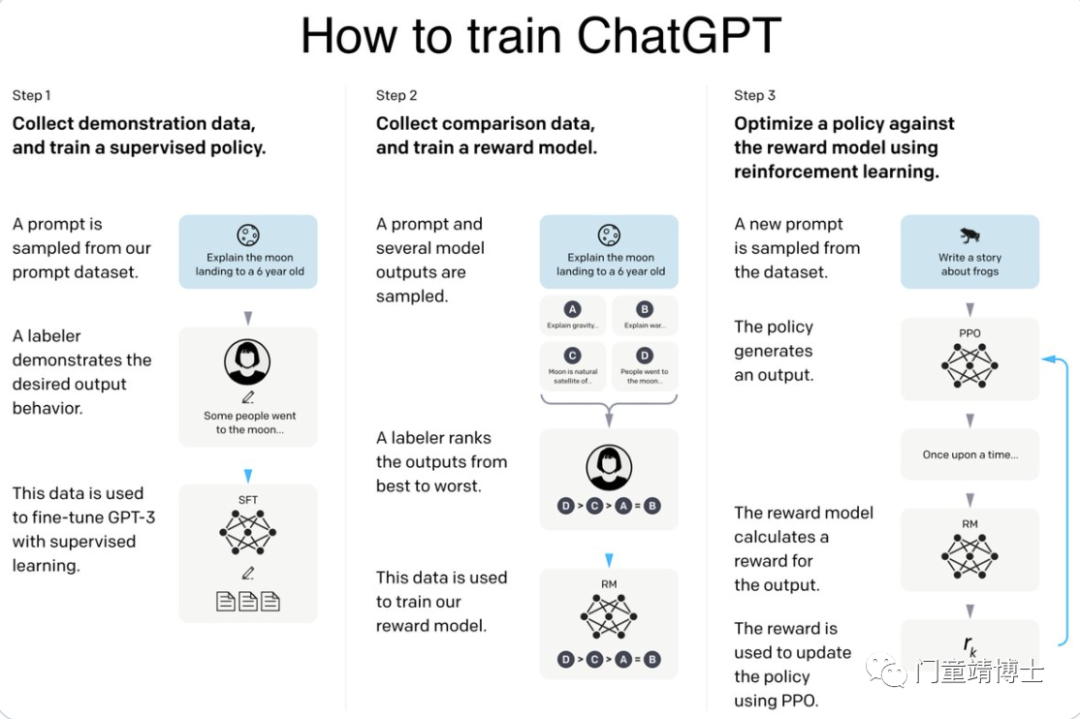
最后,用户和模型之间的交互也会引入偏差。例如,用户可能会问一些偏向一组的问题,导致模型产生有偏差的结果。

那么,如何识别ChatGPT中可能存在的偏见问题?可以从三个角度来考虑:数据、模型和交互。
从数据的角度来看,重要的是要确保用于训练 ChatGPT 的数据具有多样性和包容性。这可以通过使用包容性数据收集方法、基于透明和公正的标准选择数据点以及使用多样化和包容性的团队进行数据注释和预处理来实现。
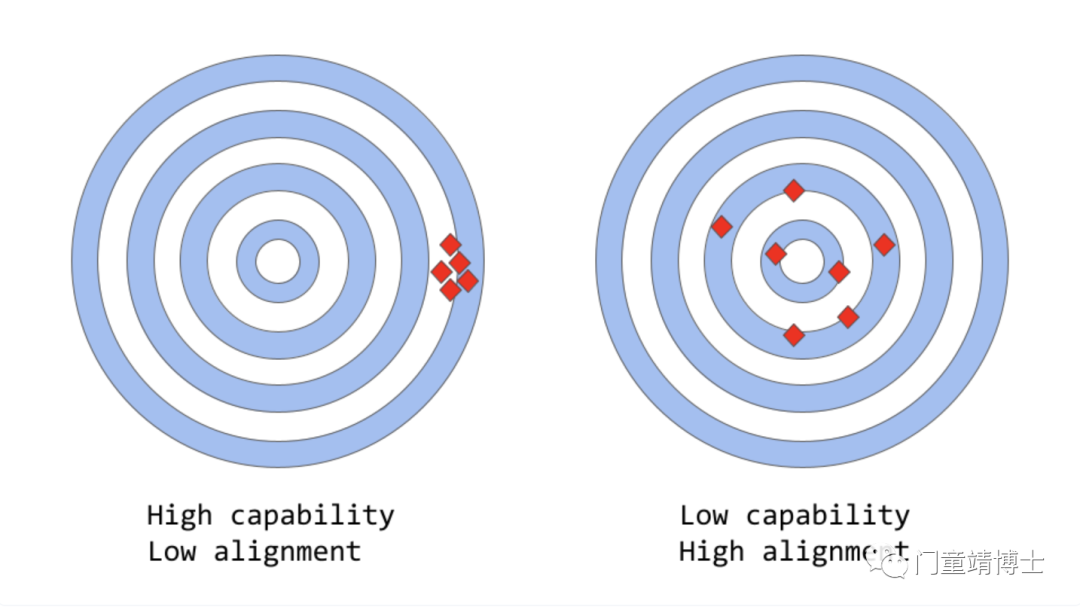
从模型的角度来看,组建多元化和包容性的团队,使用多种模型和技术来识别ChatGPT中的潜在偏差,同时通过偏差测试或对抗性测试,以识别有偏差的决策边界或分配给特征的不平等权重。
最后,我们需要监测和调整 ChatGPT 的交互方式,以确保模型不会受到任何偏见的影响。这可以包括监测用户反馈和使用行为,以及对模型进行定期的审查和测试。
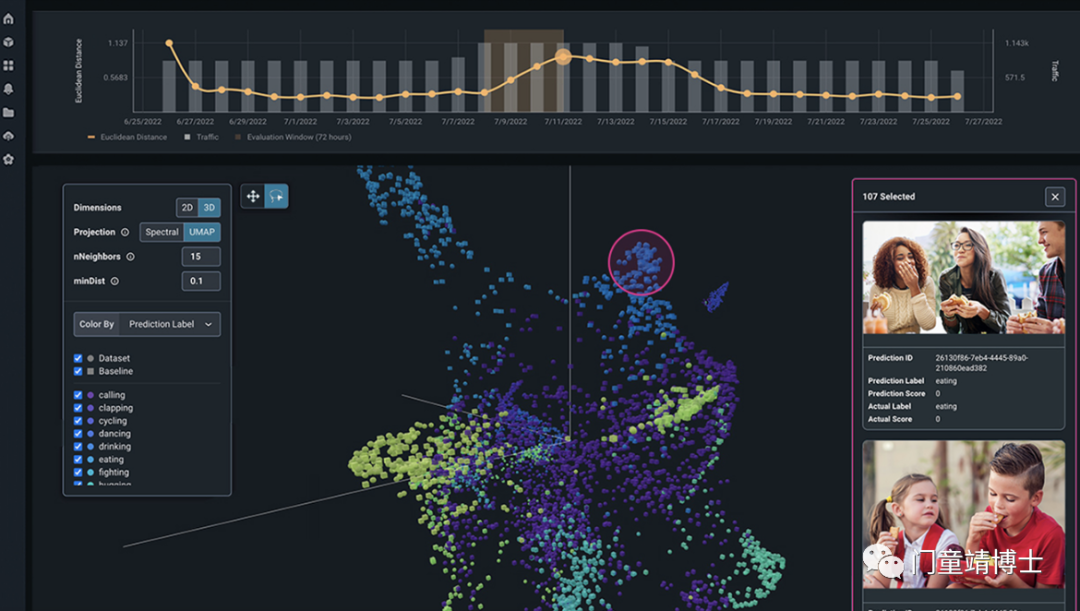
此外,应对ChatGPT中偏见问题是一个持续的过程,需要不断地监测和调整。在模型使用过程中,需要对模型进行定期审查和测试,以确保模型的公正性和可信度。
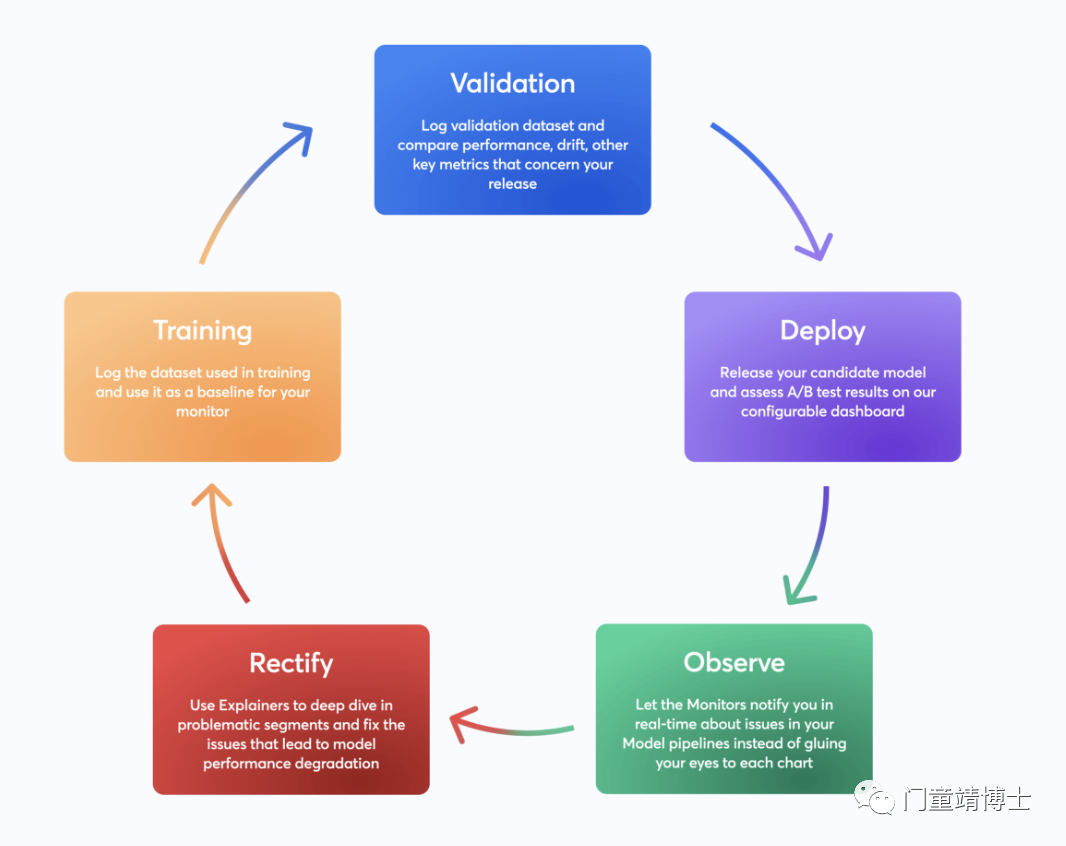
如果发现模型存在偏见问题,需要立即采取措施进行修正,同时对修正后的模型进行再次测试和审查,确保问题得到了解决。只有这样,我们才能保证ChatGPT和其他AI模型的公正性和可信度,从而更好地发挥AI的效能。
总之,AI模型的偏见问题是一个需要认真对待的伦理问题。ChatGPT作为一个强大的语言模型,已经成为AI发展中重要的里程碑。然而,由于数据、算法和交互等方面存在偏见的可能性,我们需要提早地通过多方合作和不断地监测和调整,确保模型的公正性和可信度。

只有这样,我们才能发挥AI模型的潜力,更好地服务于人类社会的发展和进步。
原创文章,作者:门童靖博士,如若转载,请注明出处:https://www.agent-universe.cn/2023/03/12474.html