
特别活动!


欢迎观看大模型日报,如需进入大模型日报群和空间站请直接扫码。社群内除日报外还会第一时间分享大模型活动。

论文
数据过滤的扩展定律 — 数据构建不可能与计算无关
 http://arxiv.org/abs/2404.07177v1
http://arxiv.org/abs/2404.07177v1诱导头电路取得成功需要什么?在上下文学习电路及其形成的机制研究
 http://arxiv.org/abs/2404.07129v1
http://arxiv.org/abs/2404.07129v1不落下任何上下文:高效的无限上下文Transformer与无限注意力
 http://arxiv.org/abs/2404.07143v1
http://arxiv.org/abs/2404.07143v1探索概念深度:大语言模型如何在不同层面获得知识?
 http://arxiv.org/abs/2404.07066v1
http://arxiv.org/abs/2404.07066v1思维雕刻:使用中间修订和搜索进行推理
 http://arxiv.org/abs/2404.05966v1
http://arxiv.org/abs/2404.05966v1麻婆豆腐中包含咖啡吗:探索大语言模型中的食品文化知识
 http://arxiv.org/abs/2404.06833v1
http://arxiv.org/abs/2404.06833v1简化能提升事实一致性自动评估效果
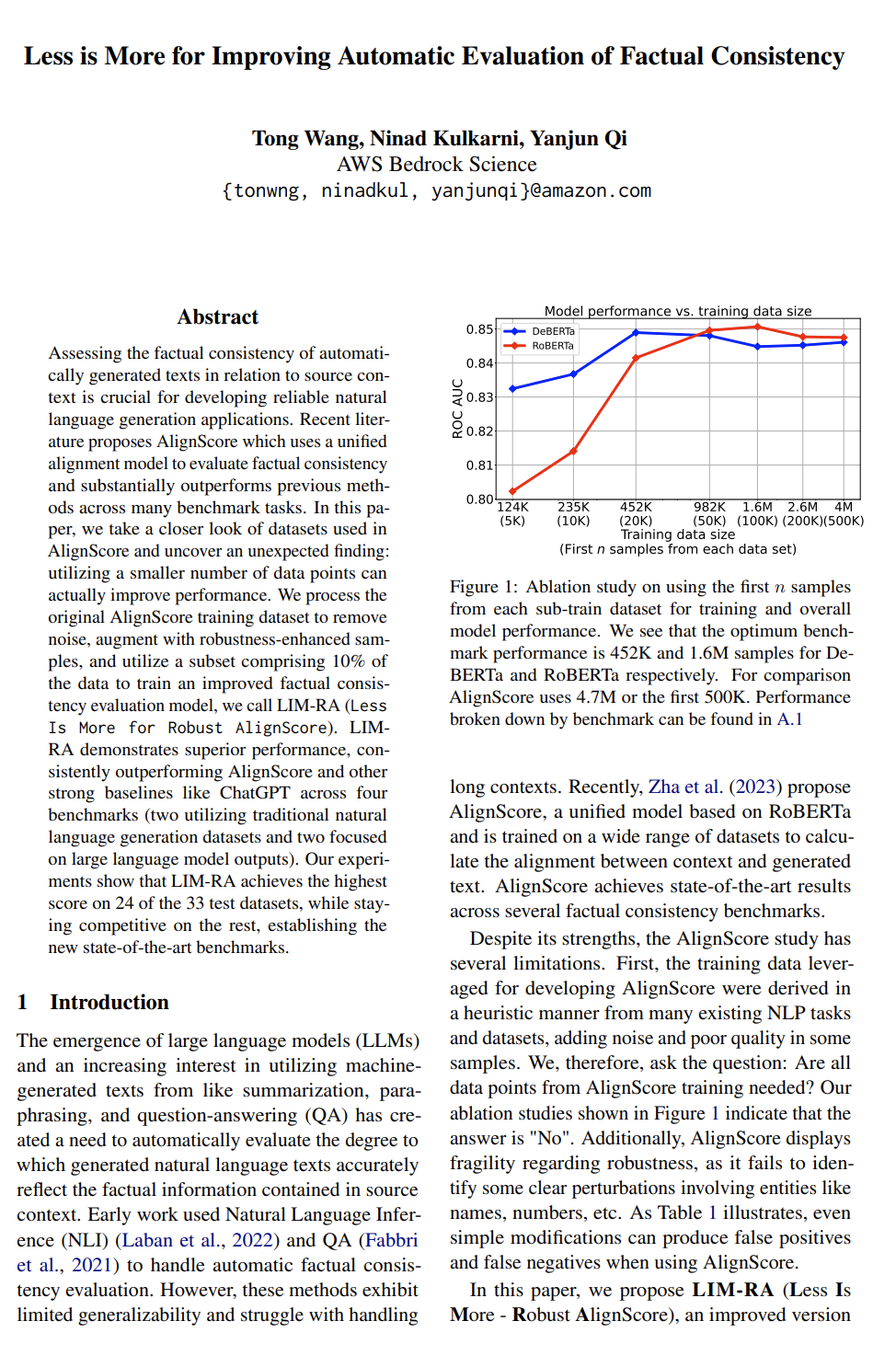 http://arxiv.org/abs/2404.06579v1
http://arxiv.org/abs/2404.06579v1
morphic
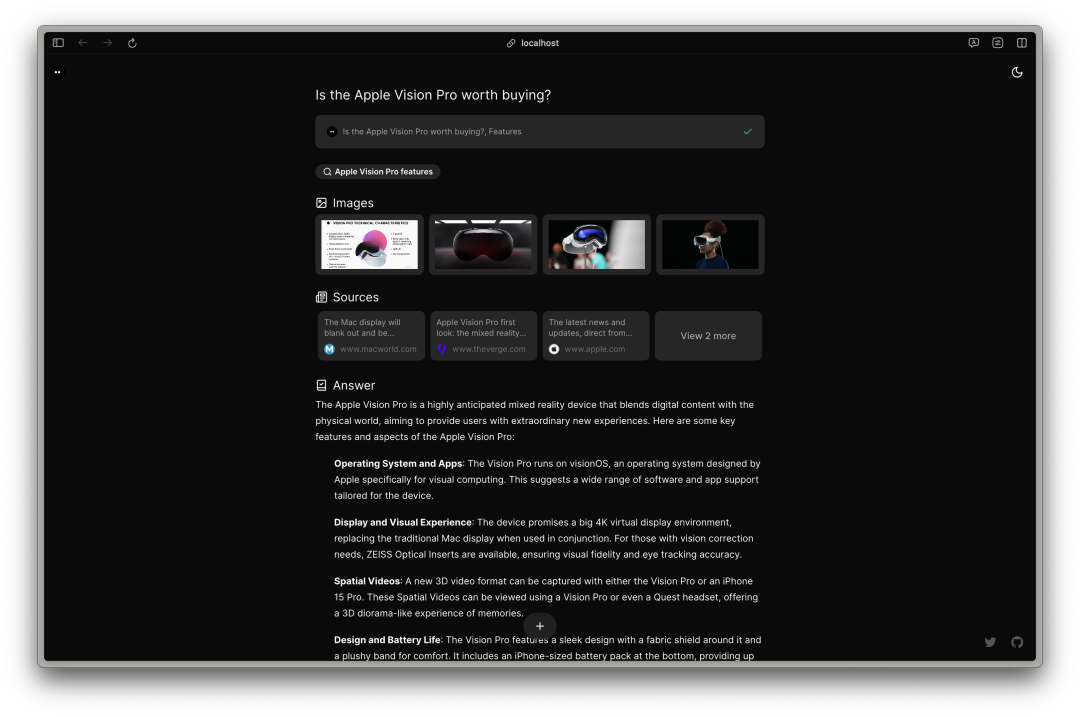
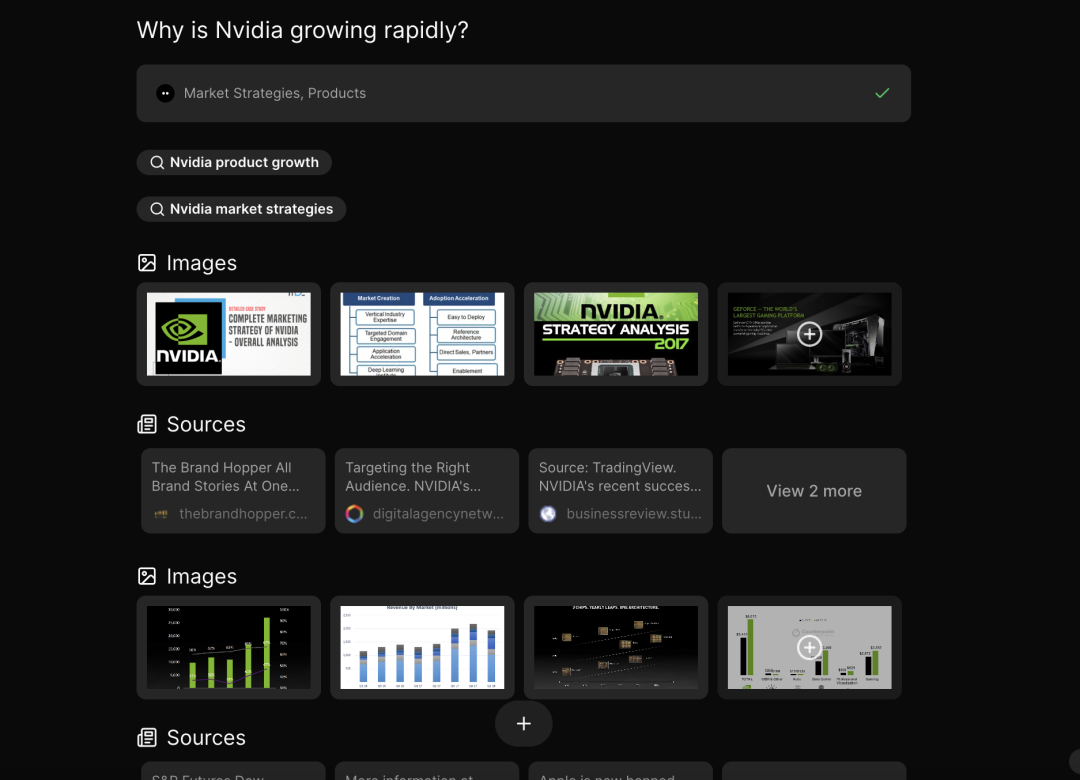 https://github.com/miurla/morphic
https://github.com/miurla/morphicCodefuse-ModelCache
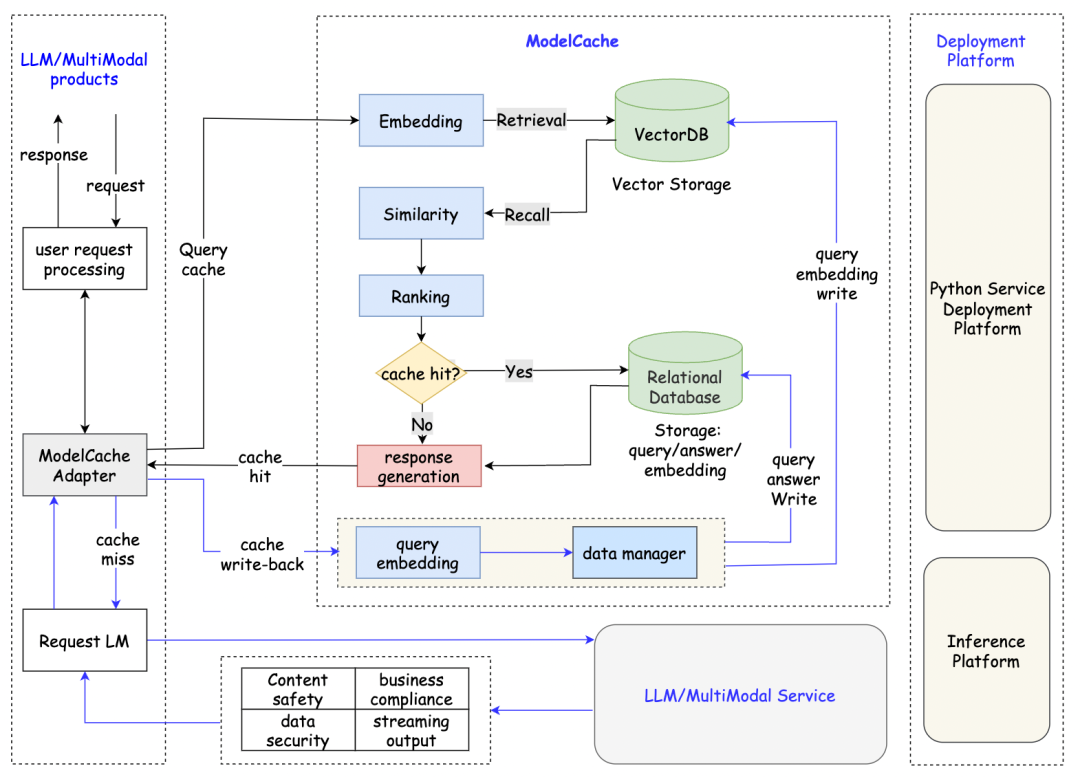 https://github.com/codefuse-ai/CodeFuse-ModelCache?tab=readme-ov-file
https://github.com/codefuse-ai/CodeFuse-ModelCache?tab=readme-ov-fileEasy-Edit
 https://github.com/zjunlp/EasyEdit
https://github.com/zjunlp/EasyEdit
大模型日报16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/16212.html