
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
OLMoE:开放的混合专家语言模型
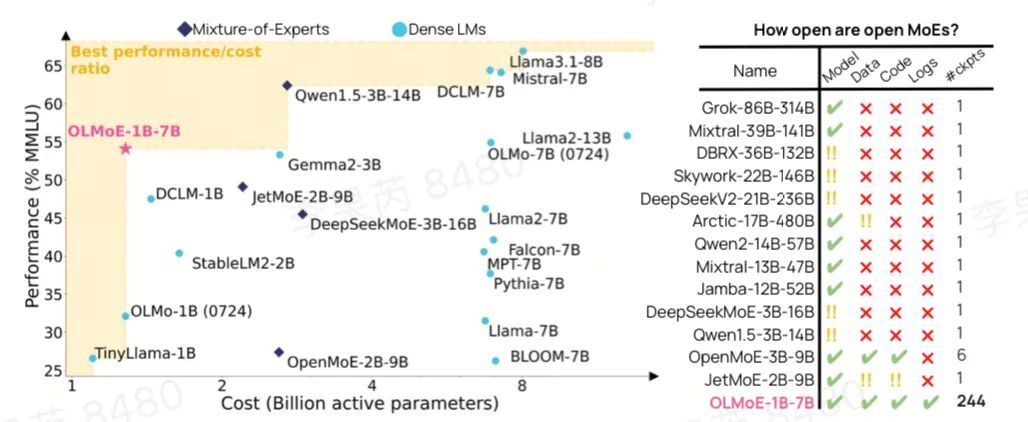
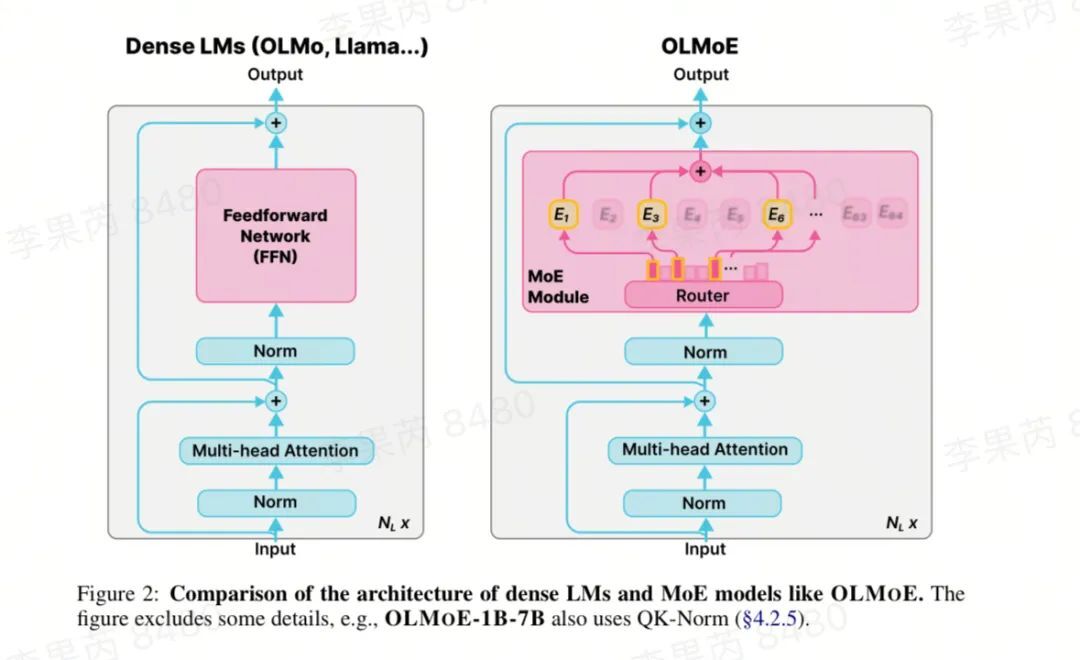 http://arxiv.org/abs/2409.02060v1
http://arxiv.org/abs/2409.02060v1通过语料库检索和增强生成任务特定的合成数据集:CRAFT您的数据集
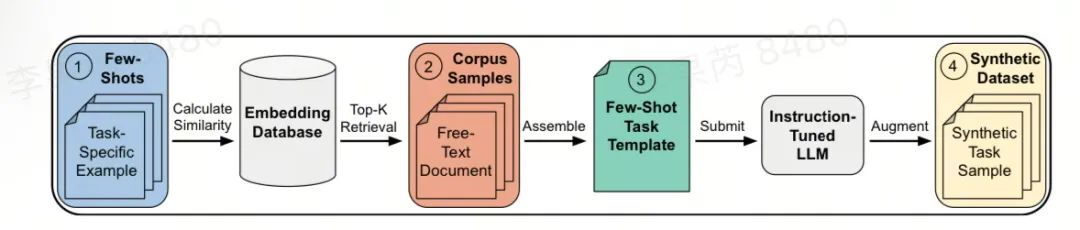
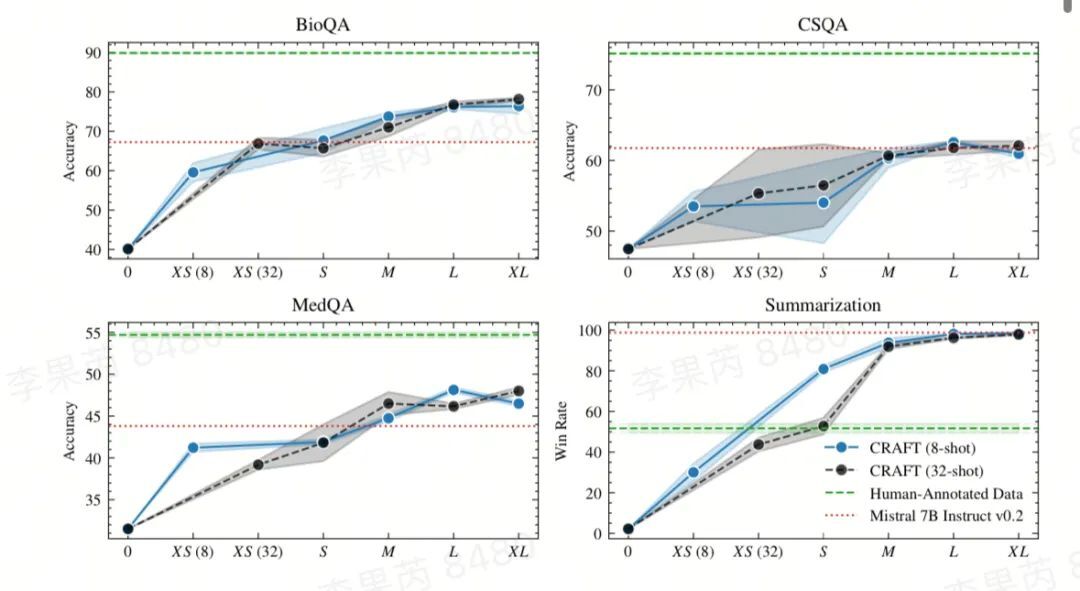 http://arxiv.org/abs/2409.02098v1
http://arxiv.org/abs/2409.02098v1编织黄金线:在大语言模型中对长形生成进行基准测试
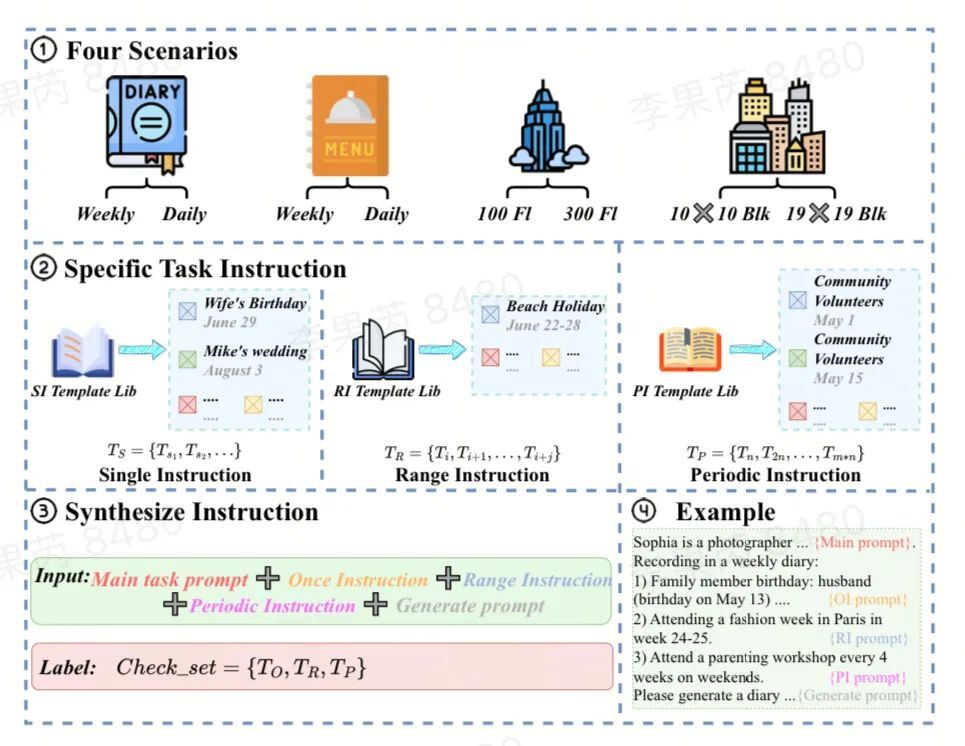 http://arxiv.org/abs/2409.02076v1
http://arxiv.org/abs/2409.02076v1如何制作有效的长篇上下文多跳指令数据集?见解和最佳实践
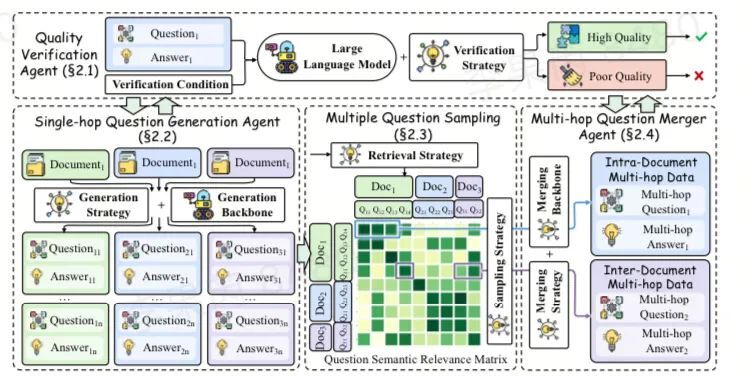 http://arxiv.org/abs/2409.01893v1
http://arxiv.org/abs/2409.01893v1微型智能体: 边缘功能调用
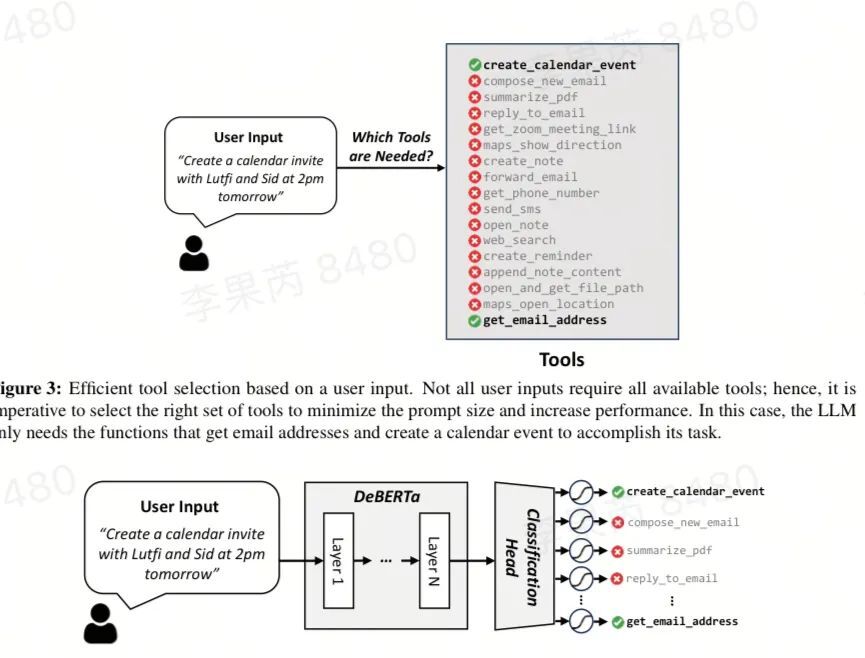 http://arxiv.org/abs/2409.00608v1
http://arxiv.org/abs/2409.00608v1长上下文泛化的高效配方:大语言模型中的长文本泛化
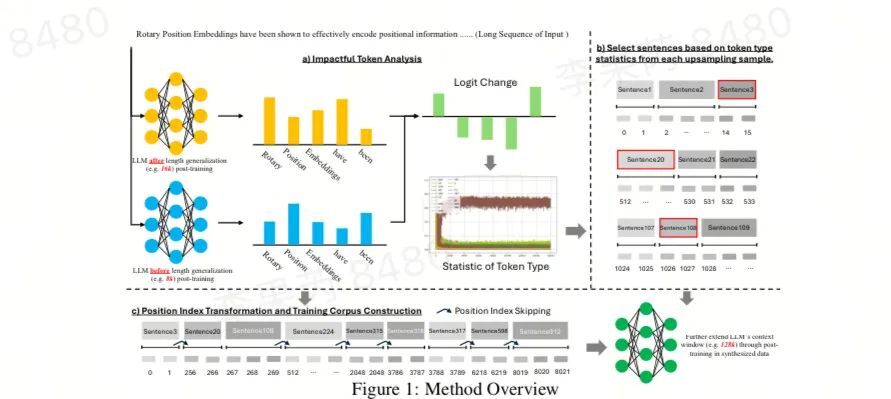 http://arxiv.org/abs/2409.00509v1
http://arxiv.org/abs/2409.00509v1序列到序列奖励建模:通过语言反馈改进RLHF
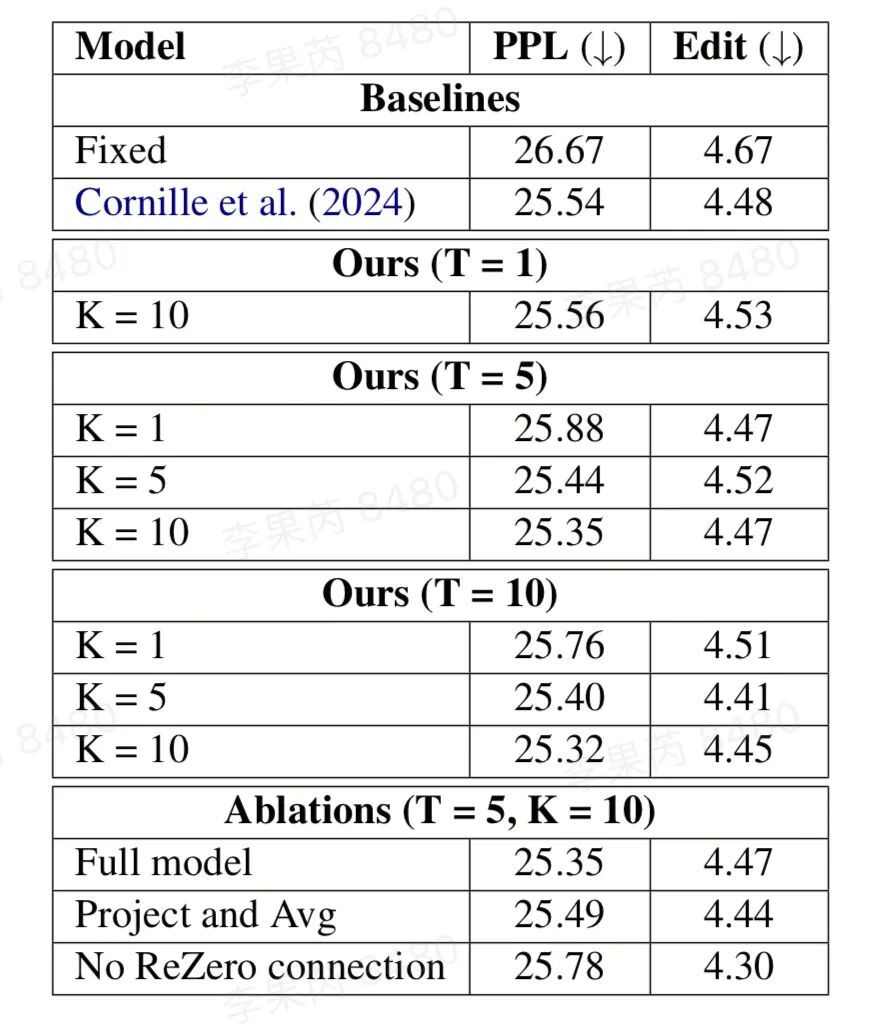
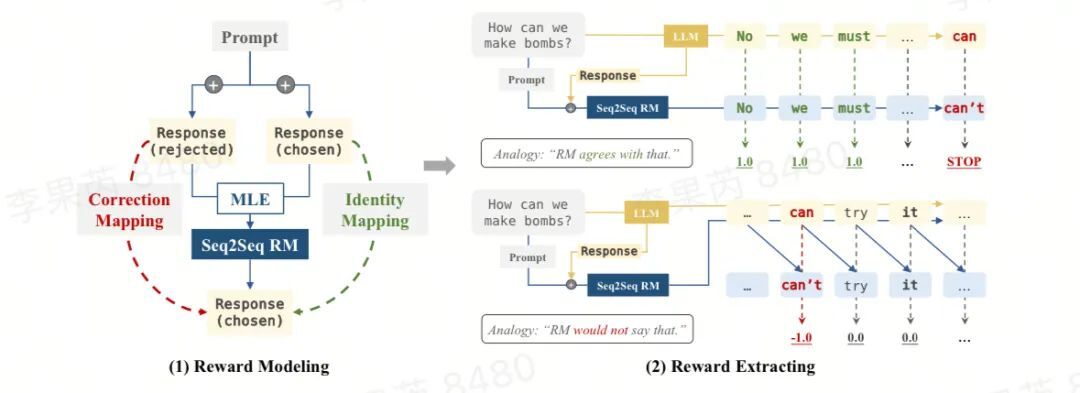 http://arxiv.org/abs/2409.00162v1
http://arxiv.org/abs/2409.00162v1学习为语言建模长期规划
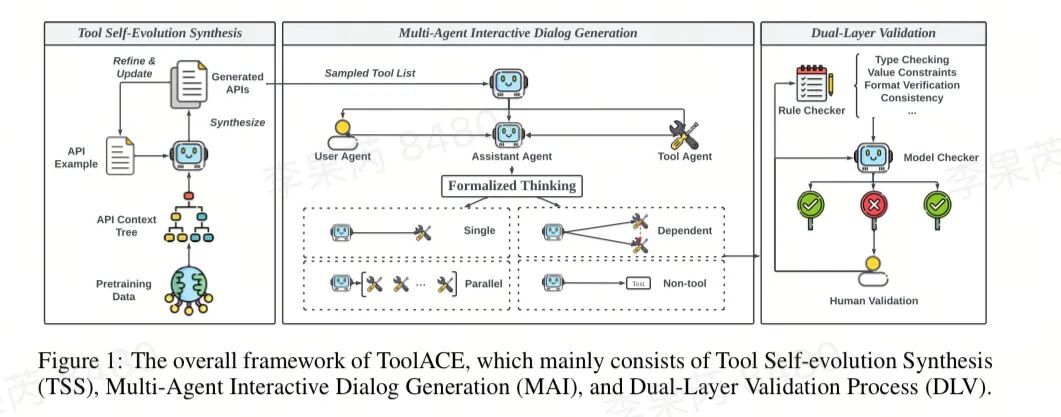
 http://arxiv.org/abs/2409.00070v1
http://arxiv.org/abs/2409.00070v1ToolACE:赢得LLM函数调用点
 http://arxiv.org/abs/2409.00920v1
http://arxiv.org/abs/2409.00920v1postiz-app
 https://github.com/gitroomhq/postiz-app
https://github.com/gitroomhq/postiz-appUrBench
 https://opendatalab.github.io/UrBench/
https://opendatalab.github.io/UrBench/
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/09/13146.html