
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


论文
xLSTM: 扩展长短期记忆网络
 http://arxiv.org/abs/2405.04517v1
http://arxiv.org/abs/2405.04517v1Granite 代码模型:用于代码智能的开放基础模型家族
 http://arxiv.org/abs/2405.04324v1
http://arxiv.org/abs/2405.04324v1NaturalCodeBench:研究HumanEval和自然用户提示中的编码能力不匹配
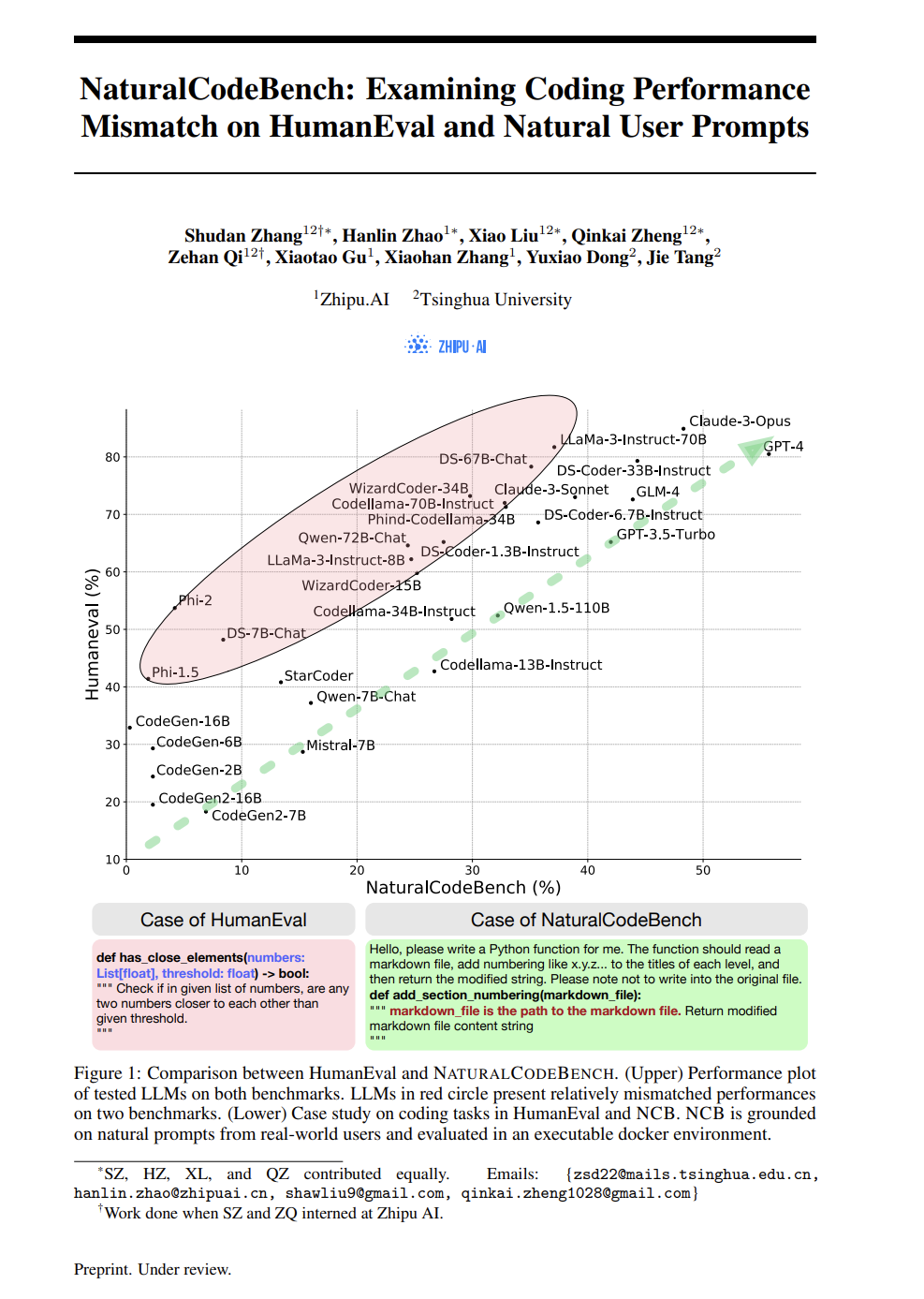 http://arxiv.org/abs/2405.04520v1
http://arxiv.org/abs/2405.04520v1QServe: W4A8KV4量化和系统共同设计,提高高效LLM服务
 http://arxiv.org/abs/2405.04532v1
http://arxiv.org/abs/2405.04532v1vAttention: 为大语言模型提供动态内存管理,无需分页注意力
 http://arxiv.org/abs/2405.04437v1
http://arxiv.org/abs/2405.04437v1StoryDiffusion
 https://github.com/HVision-NKU/StoryDiffusion
https://github.com/HVision-NKU/StoryDiffusionJARVIS
 https://huggingface.co/spaces/KingNish/JARVIS
https://huggingface.co/spaces/KingNish/JARVISScrapeGraphAI
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15557.html