
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。


论文
AlphaMath几乎无需过程监督
 http://arxiv.org/abs/2405.03553v1
http://arxiv.org/abs/2405.03553v1MAmmoTH2:利用网络数据扩展指令集
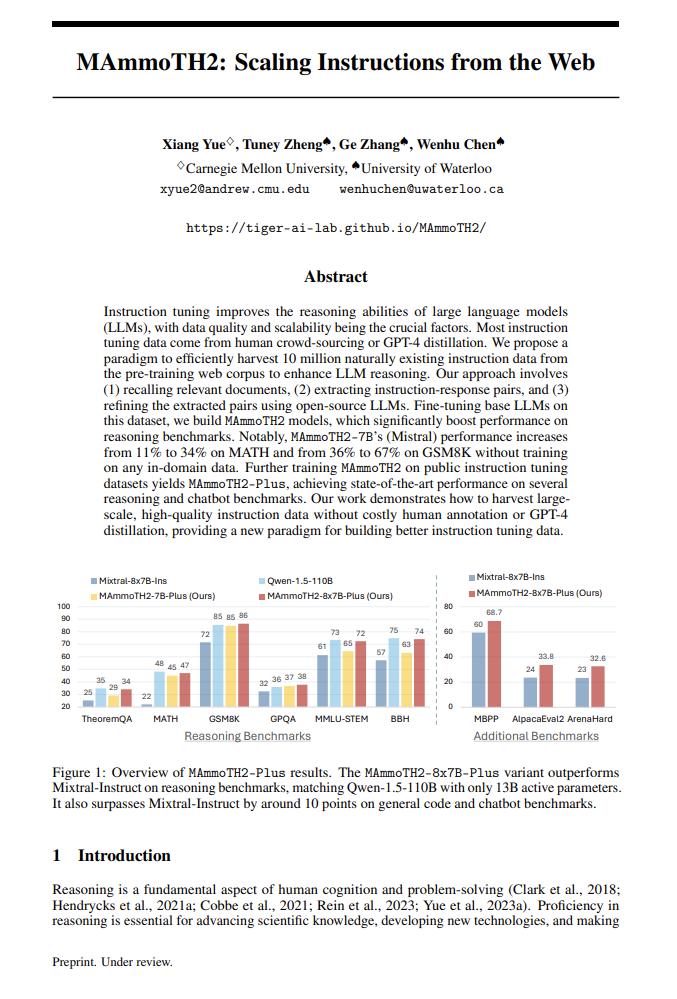 http://arxiv.org/abs/2405.03548v1
http://arxiv.org/abs/2405.03548v1推进 Gemini 多模态医疗能力
 http://arxiv.org/abs/2405.03162v1
http://arxiv.org/abs/2405.03162v1具备 3D 理解能力的语言-图像模型
 http://arxiv.org/abs/2405.03685v1
http://arxiv.org/abs/2405.03685v1ImageInWords:解锁超详细图像描述
 http://arxiv.org/abs/2405.02793v1
http://arxiv.org/abs/2405.02793v1使用离散傅里叶变换的参数高效微调
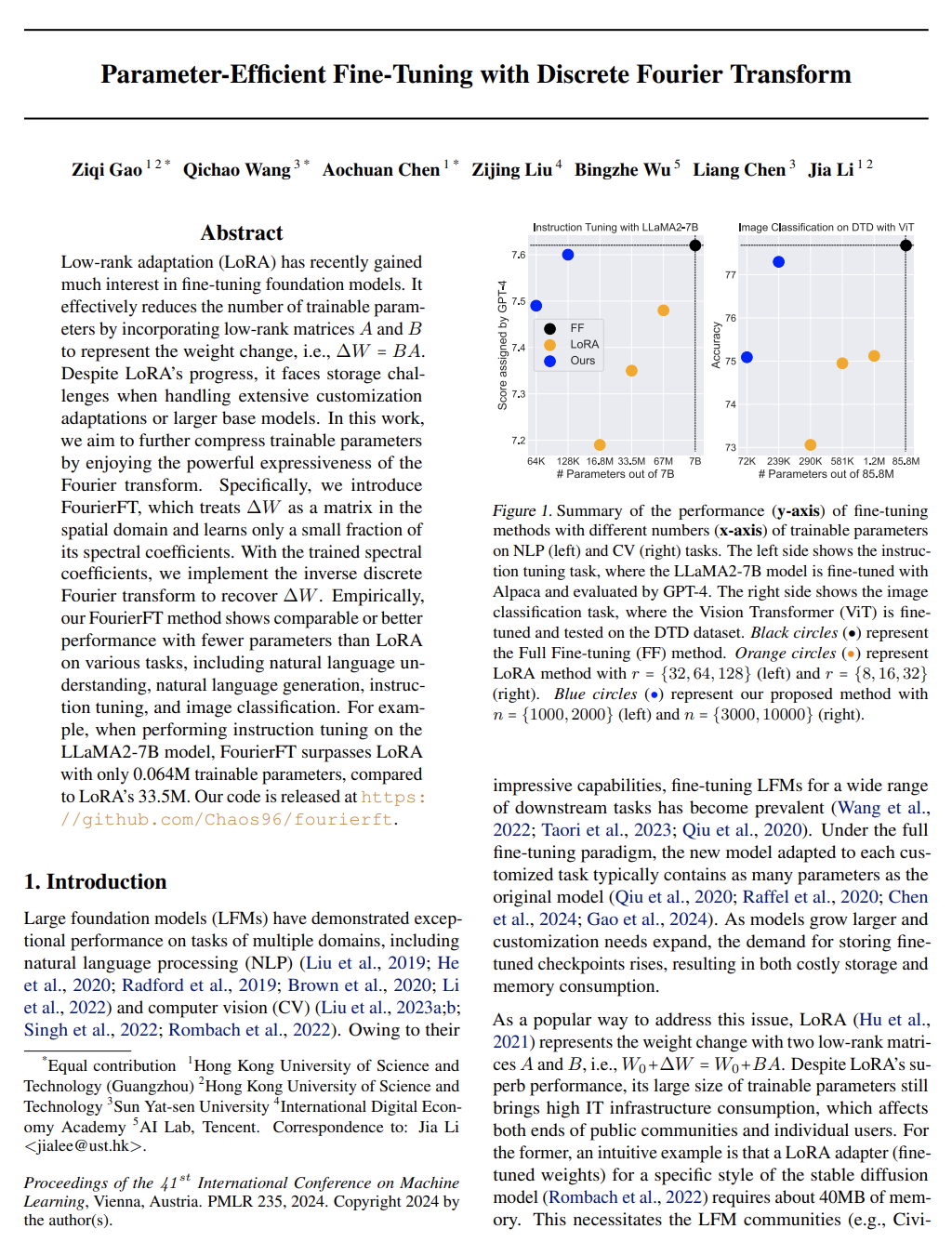 http://arxiv.org/abs/2405.03003v1
http://arxiv.org/abs/2405.03003v1以少搏多:在LLMs的微调热身中的基于原则的数据选择
 http://arxiv.org/abs/2405.02774v1
http://arxiv.org/abs/2405.02774v1高稀疏性基础 Llama 模型的高效预训练与部署
 http://arxiv.org/abs/2405.03594v1
http://arxiv.org/abs/2405.03594v1Vibe-Eval:用于衡量多模态语言模型进展的苛刻评估集
 http://arxiv.org/abs/2405.02287v1
http://arxiv.org/abs/2405.02287v1REASONS:测试开源和闭源LLM检索和自动引用科学句子的基准
 http://arxiv.org/abs/2405.02228v1
http://arxiv.org/abs/2405.02228v1通过符合性弃权来减轻LLM的幻觉
 http://arxiv.org/abs/2405.01563v1
http://arxiv.org/abs/2405.01563v1理解LLM需要不仅仅是统计泛化
 http://arxiv.org/abs/2405.01964v1
http://arxiv.org/abs/2405.01964v1大语言模型中GLU变体的依赖感知半结构化稀疏性
 http://arxiv.org/abs/2405.01943v1
http://arxiv.org/abs/2405.01943v1JAT:不偏科的RL智能体“六边形战士”
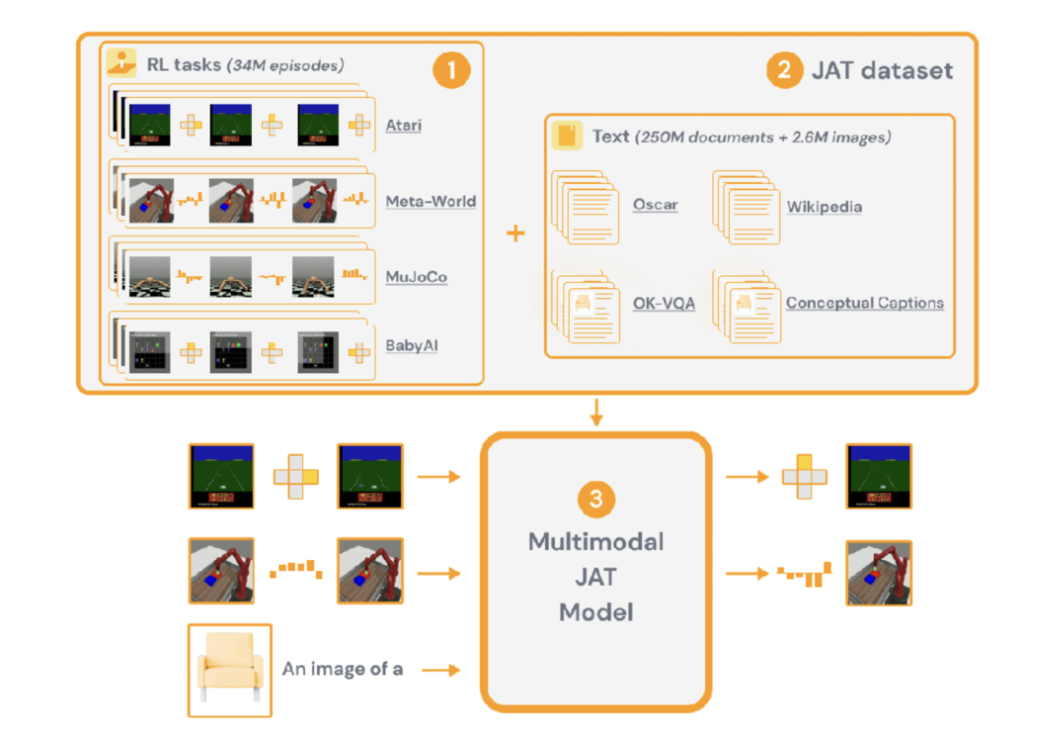 https://huggingface.co/jat-project/jat
https://huggingface.co/jat-project/jatLong Context ICL 的表现超过 fine-tuning

语言模型过拟合评测
efficient-kan
Unitxt
 https://github.com/IBM/unitxt
https://github.com/IBM/unitxt原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15588.html