
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


学习
Blaze:SparkSQL Native算子优化在快手的深度优化及大规模应用实践
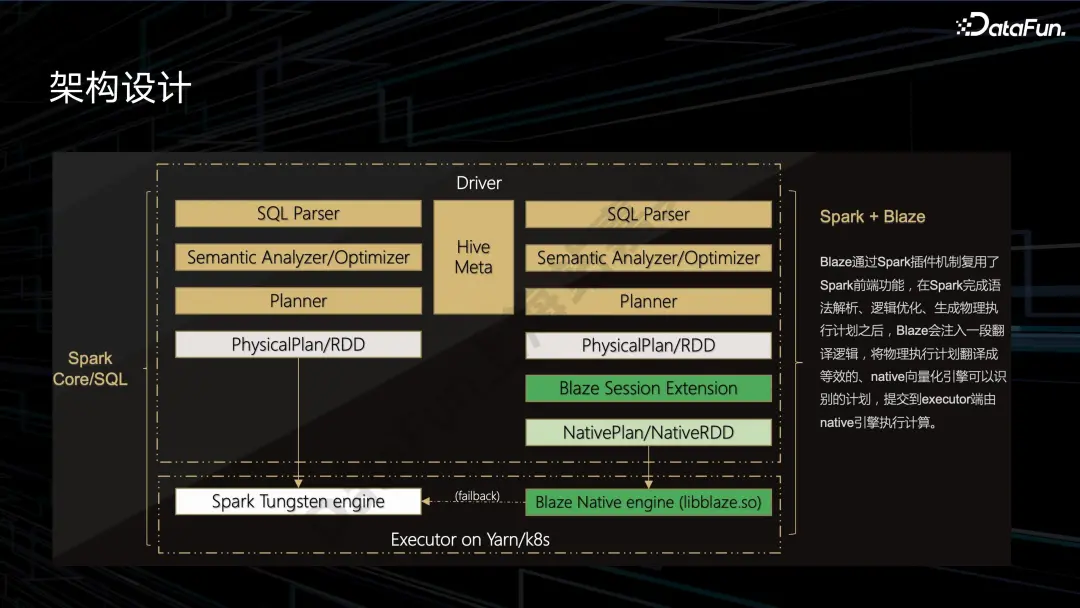 https://mp.weixin.qq.com/s/ne5FCgFDK29BWbLHjm0ZqA
https://mp.weixin.qq.com/s/ne5FCgFDK29BWbLHjm0ZqAAI计算时代的数据中心转型
 https://mp.weixin.qq.com/s/yqMsg0_ZBPp3XriKihceLA
https://mp.weixin.qq.com/s/yqMsg0_ZBPp3XriKihceLA语言模型的训练时间:从估算到 FLOPs 推导
训练时间 ≈ 6TP/nX,其中 T 是总 token 数量,P 是模型参数量,n 是显卡数量,X 是每张卡每秒实际做的浮点运算数。文章详细阐述了 FLOPs 的估算和精算过程,指出了在计算中只考虑权重矩阵的矩阵乘法,并且展示了如何将 FLOPs 转换为实际的训练时间。此外,作者还讨论了模型训练中的激活值重计算、显存带宽瓶颈以及不同硬件对 FLOPS 的影响。通过这篇文章,读者可以学习到如何基于模型参数和硬件性能来估算训练大型语言模型所需的时间,并理解在实际训练中可能遇到的技术细节和挑战。 https://zhuanlan.zhihu.com/p/646905171?utm_psn=1788246568375296000
https://zhuanlan.zhihu.com/p/646905171?utm_psn=1788246568375296000CUDA实现矩阵乘法的性能优化
 https://zhuanlan.zhihu.com/p/708583794?utm_psn=1795762463217680384
https://zhuanlan.zhihu.com/p/708583794?utm_psn=1795762463217680384序列并行云台第29将
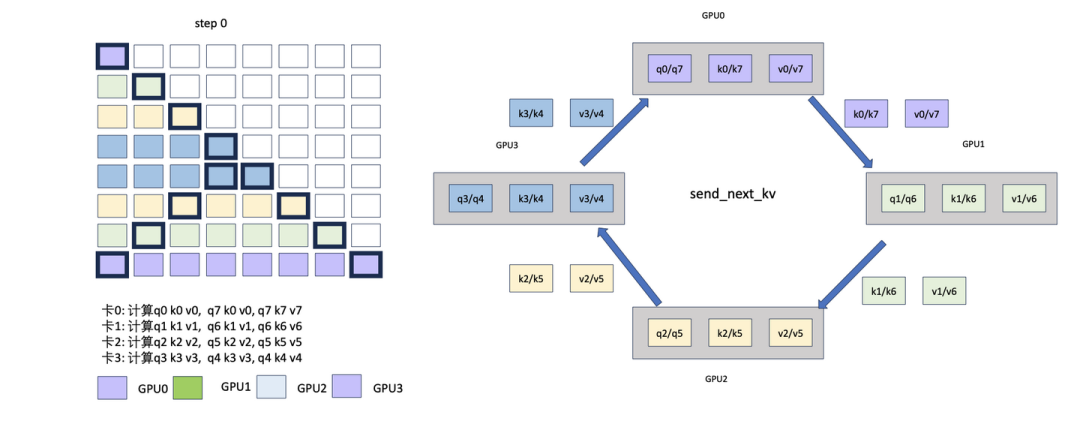 https://zhuanlan.zhihu.com/p/708670154?utm_psn=1795760188160094209
https://zhuanlan.zhihu.com/p/708670154?utm_psn=1795760188160094209CUDA-MODE 课程笔记 第四课: PMPP 书的第4-5章笔记
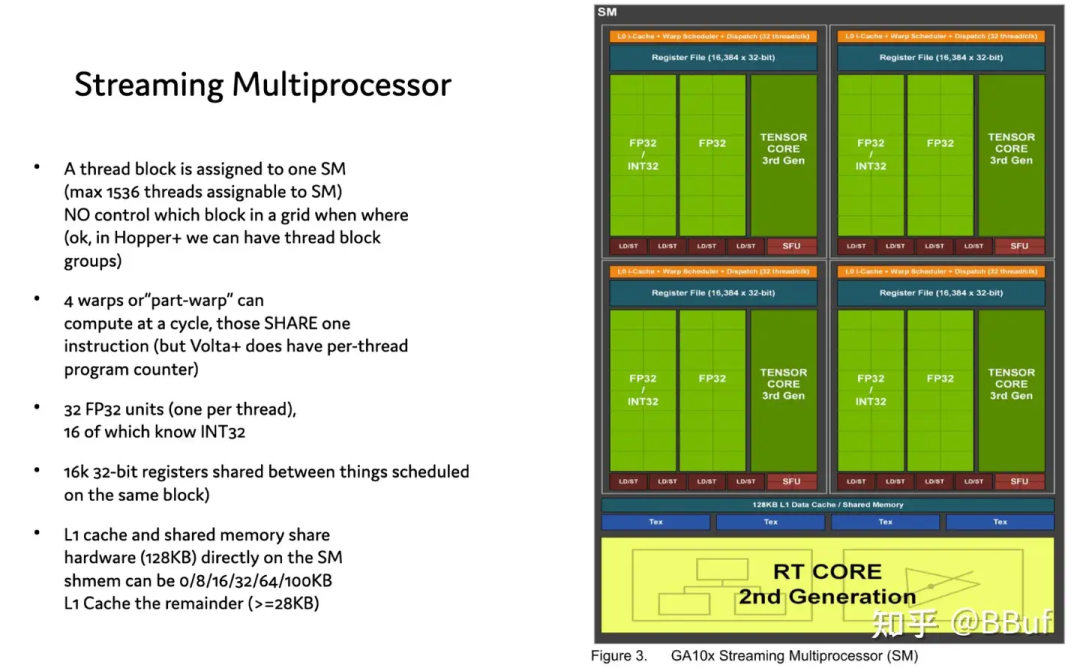 https://zhuanlan.zhihu.com/p/708682239?utm_psn=1795759927307952128
https://zhuanlan.zhihu.com/p/708682239?utm_psn=1795759927307952128LLM前沿技术跟踪:experts是否越多越好?MOE的Scaling law研究
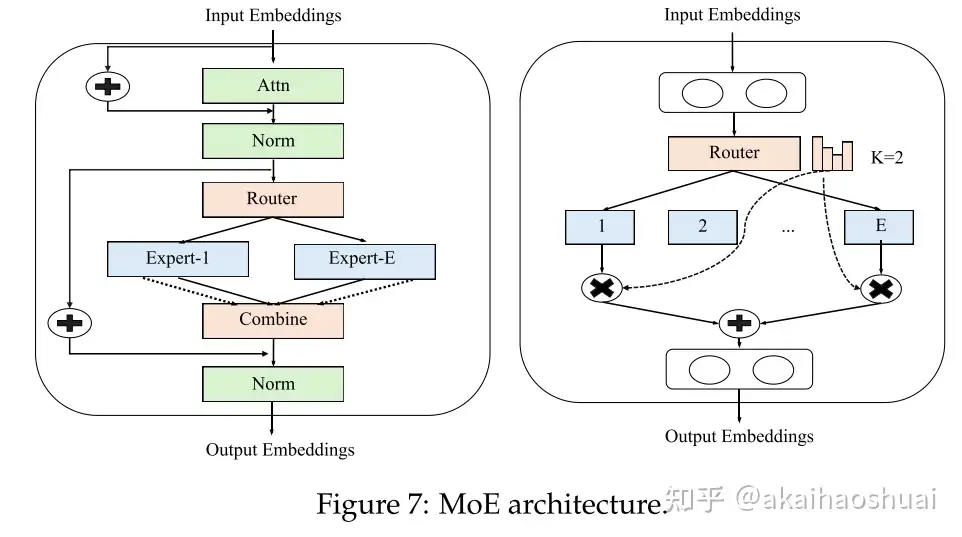 https://zhuanlan.zhihu.com/p/700582171?utm_psn=1779899329677246464
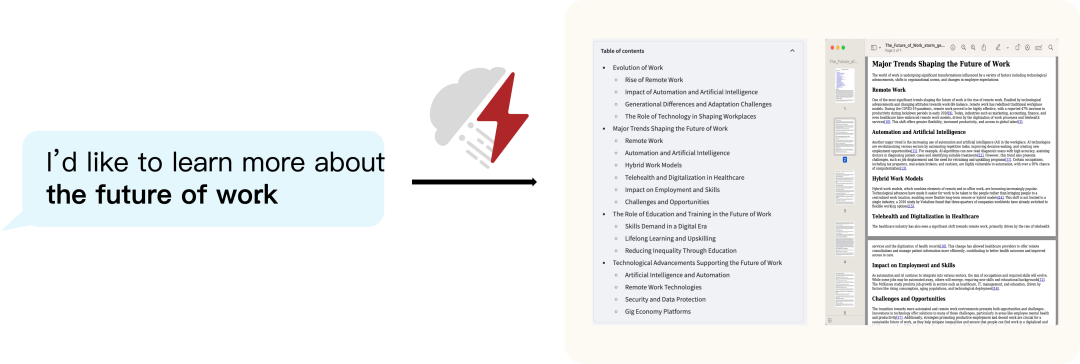
https://zhuanlan.zhihu.com/p/700582171?utm_psn=1779899329677246464Strom
-
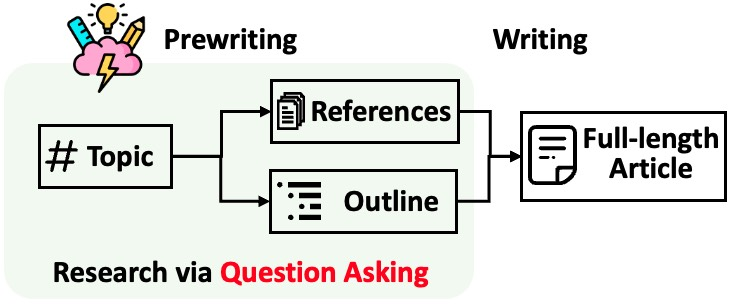
预写作阶段:系统通过互联网搜索收集相关信息,并生成大纲。 -
写作阶段:系统使用收集的信息和生成的大纲来生成完整的文章,并添加引用。
-
基于视角的问题生成:系统根据输入的主题,调查相似主题的现有文章,并使用这些视角来控制问题生成过程。 -
模拟对话:系统模拟了一个维基百科作者和主题专家之间的对话,以更新对主题的理解并提出后续问题。
 https://github.com/stanford-oval/storm
https://github.com/stanford-oval/stormCradle
 https://github.com/BAAI-Agents/Cradle
https://github.com/BAAI-Agents/Cradle原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/07/14144.html