
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
Nemotron-4 340B 技术报告
 http://arxiv.org/abs/2406.11704v1
http://arxiv.org/abs/2406.11704v1大语言模型在预训练过程中如何获取事实知识?
 http://arxiv.org/abs/2406.11813v1
http://arxiv.org/abs/2406.11813v1Datacomp LM: 寻找下一代语言模型训练集
 http://arxiv.org/abs/2406.11794v1
http://arxiv.org/abs/2406.11794v1长代码竞技场:长文本代码模型基准集
 http://arxiv.org/abs/2406.11612v1
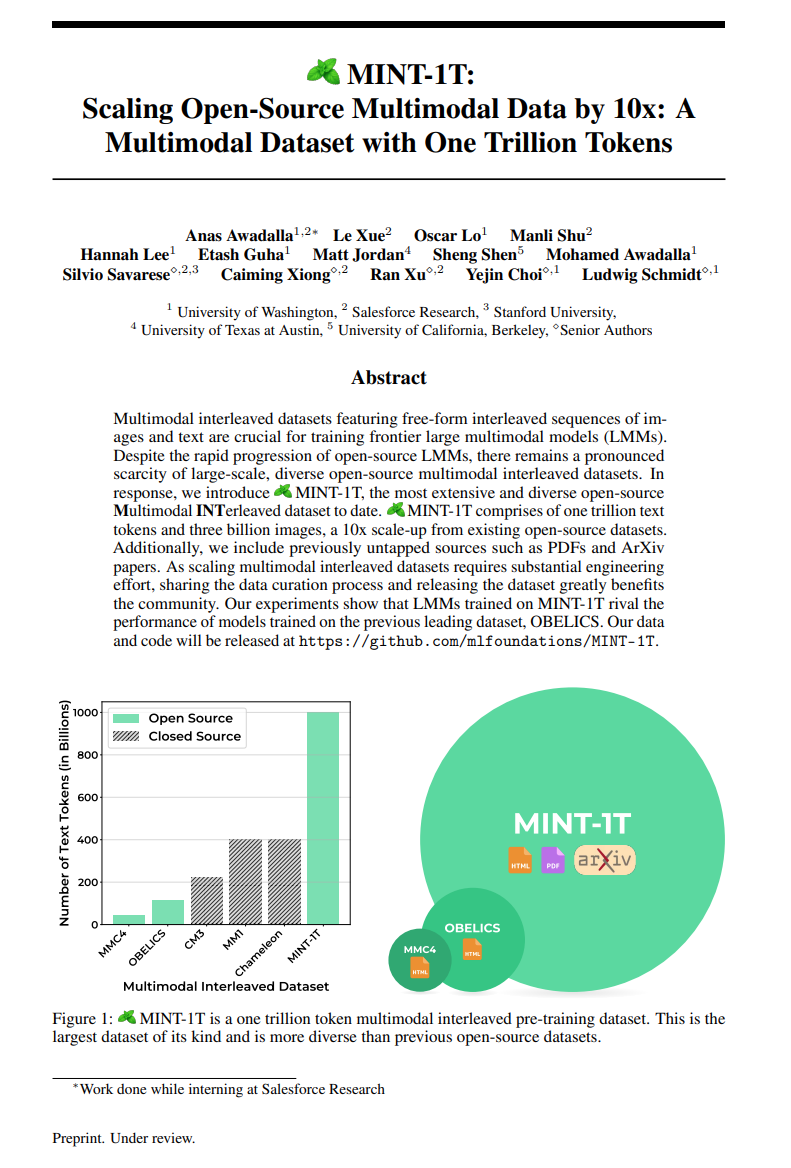
http://arxiv.org/abs/2406.11612v1MINT-1T:将开源多模态数据扩展10倍:一个含有万亿个token的多模态数据集
 http://arxiv.org/abs/2406.11271v1
http://arxiv.org/abs/2406.11271v1HumanPlus: 从人类智能体进行人类仿真和模仿
 http://arxiv.org/abs/2406.10454v1
http://arxiv.org/abs/2406.10454v1unitycatalog
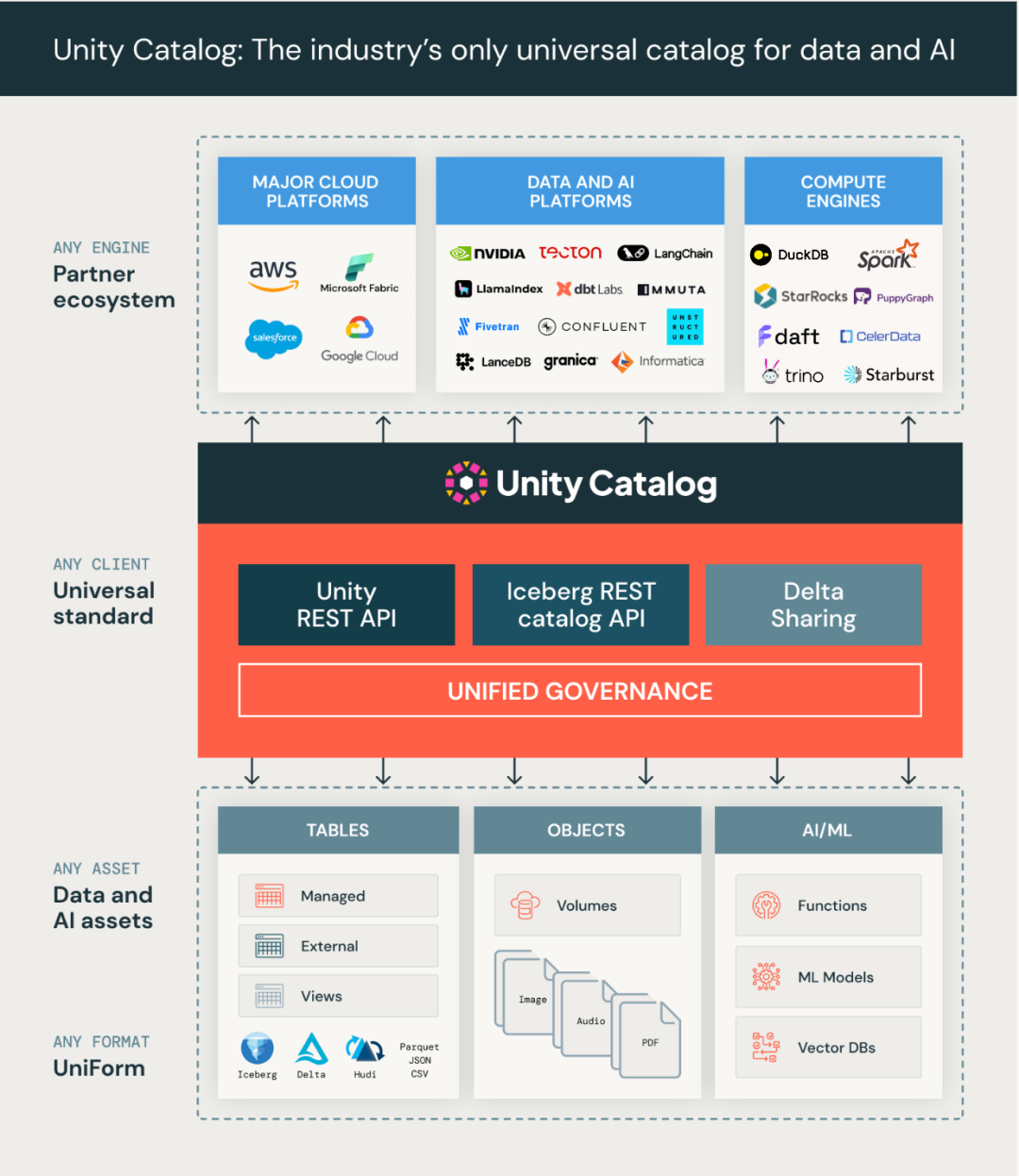 https://github.com/unitycatalog/unitycatalog
https://github.com/unitycatalog/unitycatalogAI Math Notes
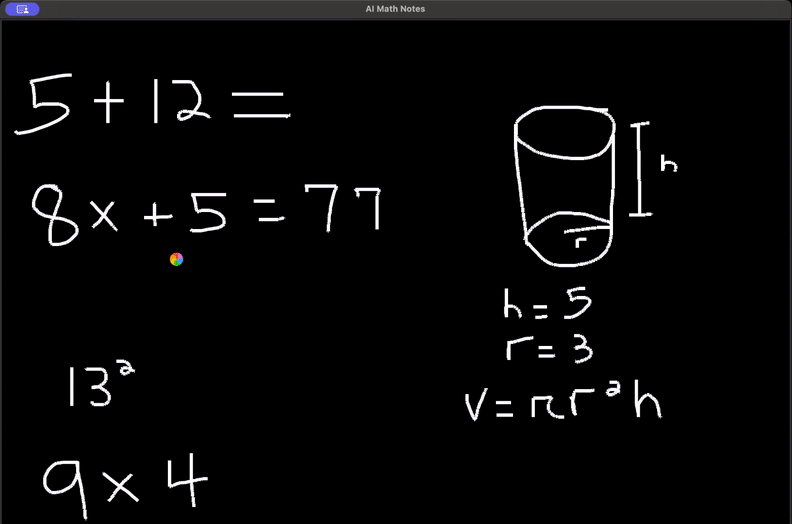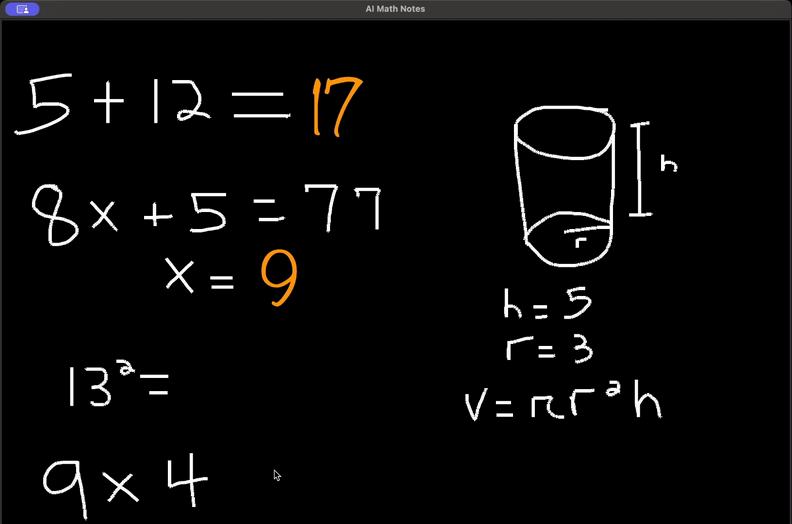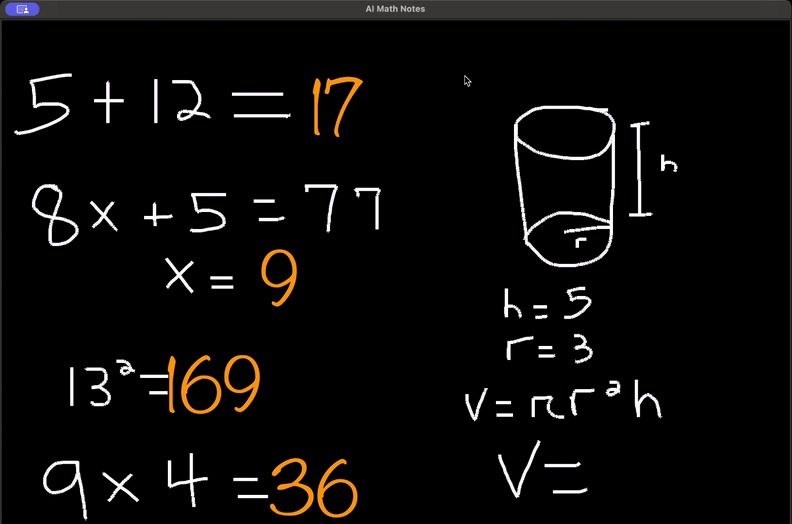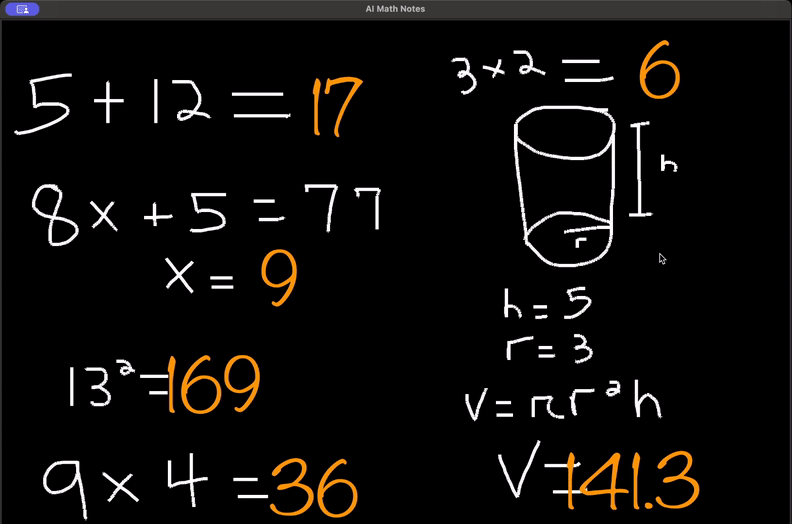 https://github.com/ayushpai/AI-Math-Notes
https://github.com/ayushpai/AI-Math-Notes原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/06/14666.html