
GitHub链接:https://github.com/multimodal-art-projection/MAP-NEO
顺应人工智能发展需求,大语言模型(LLM)不断更新迭代,在许多自然语言处理(NLP)任务中显示出强大能力。与此同时,大语言模型的快速商业化使最先进的大语言模型均处于闭源状态,许多模型搭建的重要细节,如训练数据、模型架构、基础设施细节等都没有面向公众开放。对于 LLM 研究者而言,这些尚未披露的细节对模型研究和发展都是至关重要的,尽管已经有完全开源的大语言模型供研究者使用,但是这些开源模型的性能和商业大语言模型相比还有着很大的鸿沟,特别在中文语言处理和一些推理任务上的性能仍远远低于商用模型。
MAP-Neo。MAP-Neo公开了经过清理的预训练数据集、数据清理细节、所有 Checkpoint 和评估代码。M-A-P 希望MAP-Neo能够增强和巩固开放研究社区,并激发新一轮的创新浪潮。
作为 M-A-P 团队的一员,整数智能全过程参与到了MAP-Neo的建构过程中。高质量的训练数据对优秀的模型性能表现而言至关重要。MAP-Neo的卓越性能,既源于规模化的训练数据,也归功于严谨的数据清洗和处理流程。同时,引入中文数据集建构双语大型语言模型的尝试,也为训练数据的清洗和筛选带来了新的挑战。在数据集开源的同时,M-A-P 团队还公开发布了 Matrix 数据集与生产 Matrix 数据集的所有代码。
1. MAP-Neo介绍
1.1. 模型简介
在人工智能大模型领域,科技企业巨头利用算法搭建起了一个数据垄断和操纵的数据殖民主义框架。数据殖民主义的概念认为,由美国牵头的科技巨头公司庞大的数据力量,通过大模型算法,操纵着用户的行为和判断,并持续对人的行为和踪迹进行跟踪和记录,并获取行业垄断地位和攫取高额汇报。基于这一现状,人工智能民主化的概念应运而生,提倡者认为,促进所有机构公平地获得人工智能技术,能够推动人工智能资源民主化,从而降低数据殖民主义的风险。在人工智能技术中,大语言模型处于主导地位,增加开源的大语言模型,并和闭源商用模型展开竞争,可以同时解决人工智能开放资源短缺和数据安全隐私的问题。
不仅如此,大多数标榜开源的大语言模型并未公开开发过程中的关键环节,如数据来源、数据预训练代码和数据处理 Pipeline 等重要环节都是不透明的,而这些正是建立大语言模型过程中成本最高的环节。现有的开源大语言模型远不能为研究者提供一个良好的使用和参考资源。
此外,现存的大多数大语言模型都是基于英语语料库从零开始训练搭建的产物,如何使非英语语言社区从开源模型中获益、在非英语地区推行数据与人工智能的民主化,是一条仍需探索的道路。
基于以上种种困境,为实现大语言模型训练过程透明化,Multimodal Art Projection(M-A-P)研发团队发布完全开源的大型语言模型MAP-Neo。MAP-Neo包括最终和中间检查点、自训练标记器、预训练语料库以及高效、稳定的优化预训练代码库。MAP-Neo模型基于4.5T中英文词条从头开始训练生成。在推理、数学和编码等具有挑战性的大语言模型任务中,表现出了优于同等训练数据规模的模型,展现出了媲美专有模型的专业模型性能。

MAP-Neo-7B完全开源,团队公开数据包括基本模型和一系列中间检查点,旨在为学术界和商业界更广泛、更多样的研究提供支持。
1.2. MAP-Neo-7B 模型表现
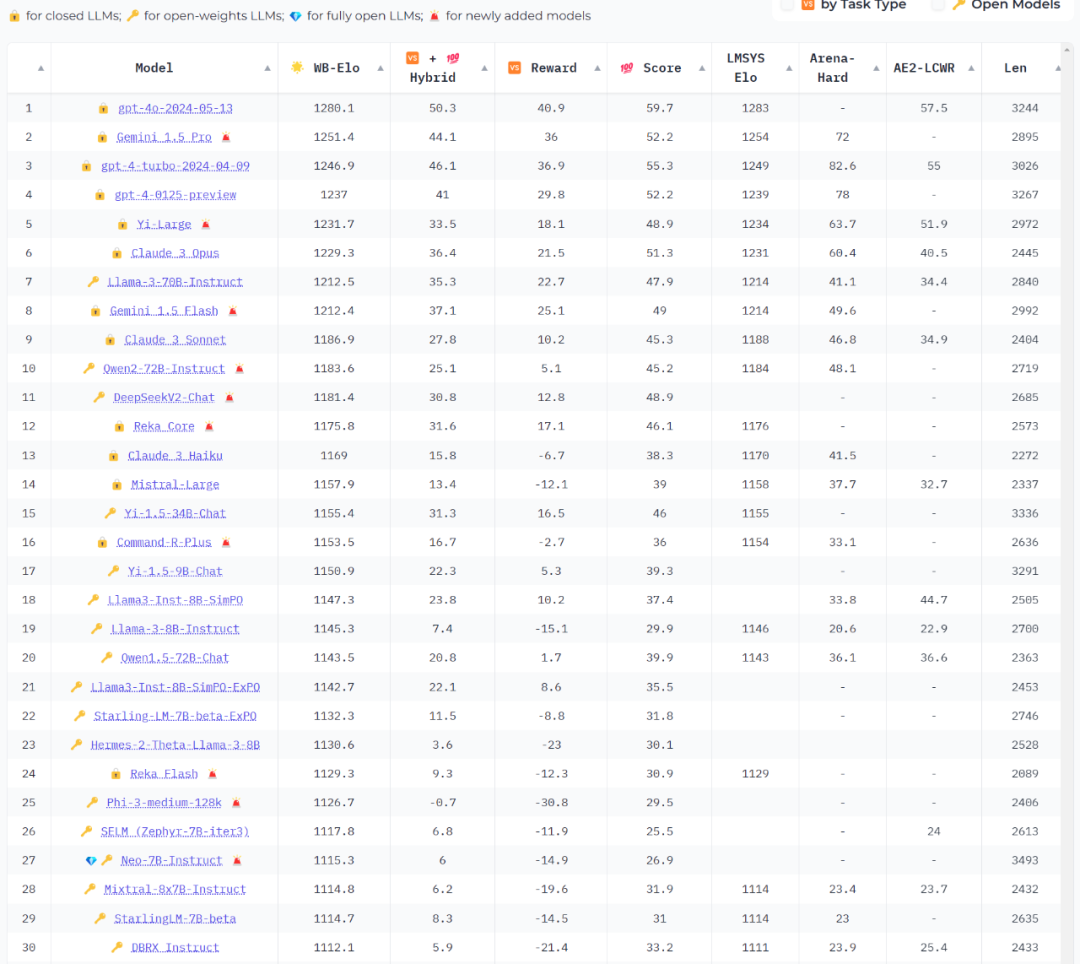
MAP-Neo-7B在广泛的基准测试中展示了卓越的能力,与同训练规模模型相比,MAP-Neo-7B的性能表现已经可以对齐甚至超过前沿的闭源商业化大语言模型。
1.3. 全开源语言模型里程碑
MAP-Neo的问世对于大语言模型研究来说是一个里程碑,它标志着完全开源透明的大语言模型具备了可以和闭源商用大语言模型相媲美的先进能力与优秀性能。M-A-P 团队的贡献远不止构建了一个前所未有的基础模型与全行业研究者共享,更是一个全透明的从零开始构建大语言模型的全流程指导手册。M-A-P 团队欢迎需要中文大模型但是受到有限流通模型限制的企业使用或者参考MAP-Neo,共同助力更加具有活力和多元化的中国大语言模型企业社群,为社会各界,尤其是世界上进行大语言模型研究的非英语地区提供重要参考。
2. 模型优势
相比于过往的大语言模型,MAP-Neo在模型性能和模型透明性上做到了很好地平衡,作为首个开源透明的双语大语言模型,MAP-Neo打破了当下的开源大语言模型性能远远低于闭源商业化大语言模型的现状和困境,也为大语言模型搭建提供了全透明搭建 Pipeline 指引。
2.1. “彻底的”开源模型
MAP-Neo的开源更加彻底,公开了从原始收集数据的来源、数据清洗到预训练代码库的所有关键流程。彻底的全过程开源可以大大降低未来部署和定制大语言模型的成本,尤其是中文大语言模型建构的成本。
M-A-P 团队公开发布并详细介绍了MAP-Neo的以下搭建环节与模型构成:
-
数据整理与处理 团队发布了预训练语料库,即矩阵数据堆(Matrix Data Pile),以及用于监督微调和对齐训练的训练数据。团队进一步整理了中英文训练数据,以及数据清洗的代码和细节,包括一个稳定的 OCR 系统、DeepSeek-Math 中的数据召回机制、以往开源数据处理管道的集成以及基于 Spark2 的分布式数据处理支持等。 -
模型训练架构 团队公开发布了建模架构的代码和细节。提供了标记化器、基本模型、指令调整模型和 RLHFed 模型的训练代码。此外,团队在模型搭建的过程中还解决了 Megatron-LM 框架3的一些问题,增强了其对更稳健、更高效的 LLM 分布式训练的支持。
-
模型检查点 团队在 HuggingFace 上发布了最终模型,并提供了中间检查点。 -
基础设施 团队在模型报告中详细介绍了稳定训练的基础设施。 -
推理与评估 团队提供用于推理优化和全面评估的完整代码。 -
分析与教训 团队本报告阐述了大量技术和秘诀,例如预训练不同阶段的优化技巧,并通过严格的分析和消融,为构建 LLM 的见解。
2.2. 规模化训练数据
在保证训练数据规模的同时,MAP-Neo-7B对训练数据的数量也进行了严格的把控,以保证模型训练的质量和效率。不仅如此,M-A-P 研发团队还全透明公开了数据处理 Pipeline。
2.3. 中英双语语料库
面对高质量中文数据集开发程度低、高质量中文语料短缺的现状,基于中英文训练数据搭建MAP-Neo-7B对于中文数据集的填补完善发挥着巨大的价值。M-A-P 团队不仅丰富了高质量的中文数据集积累,更将如何通过数据过滤筛选获得高质量的中文训练数据的全过程与开源模型一起向公众开放,分享训练数据清洗经验,为之后中文数据集的扩充提供了有效的方法参考和遵循。
2.4. 高质量训练数据集建构
如何获得高质量数据,是保证训练模型性能的关键,通过采用高质量的数据,MAP-Neo在数学、代码和复杂推理方面的测试表现明显由于既往的开源低质量大语言模型(如 Amber 和 Pythia)。团队公开了对包括英文数据和中文数据过滤清洗全流程 Pipeline ,分享了如何有效通过数据清洗获得高质量、满足高效率模型训练需求的中英文训练数据。
2.4.1. 英文数据清洗Pipeline
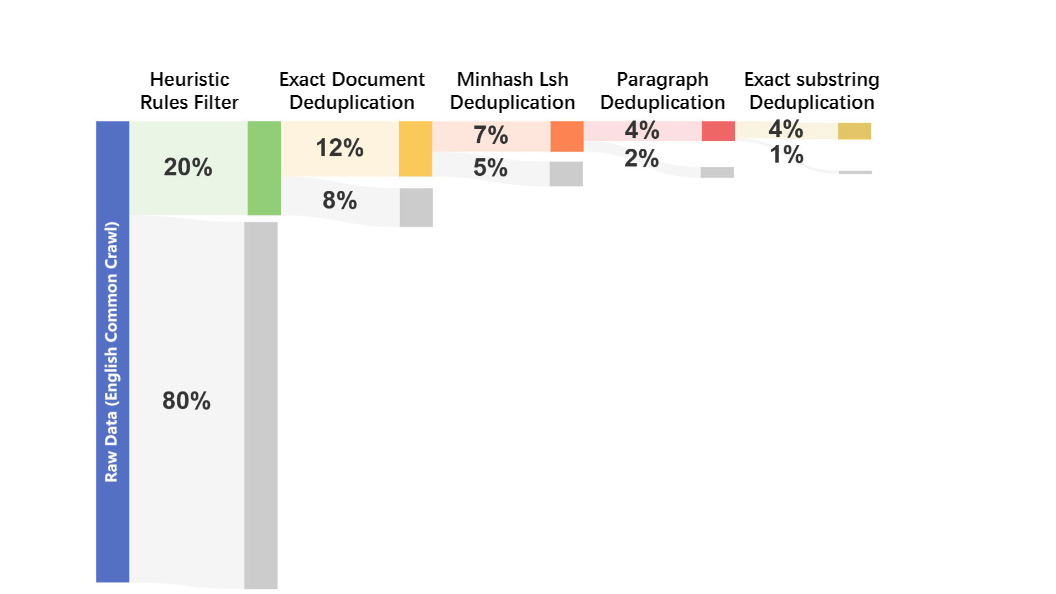
英文数据清洗Pipeline结构
开放数据集再处理Pipeline
基于既往研究中发布的开源预训练语料库,M-A-P 团队设计了一个更加精细的管道,在现有数据的基础上进行再处理,生成 Matrix 数据混合的英语子集,进一步提高数据质量。团队公开了数据来源和数据过滤与去重的步骤。
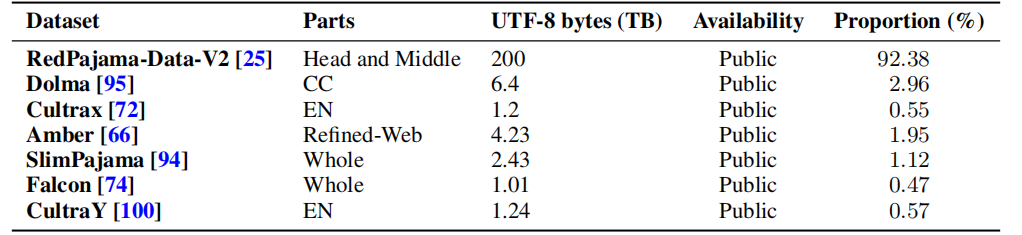
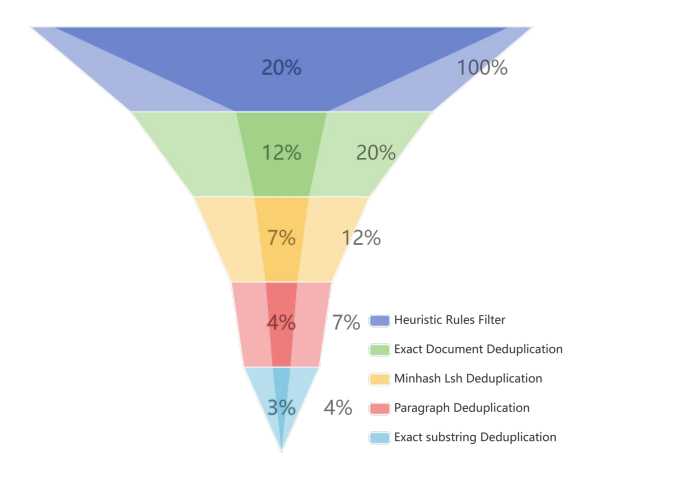
英文子集数据过滤Pipeline及各环节筛选率
值得一提的是,通过使用再处理的更高质量的数据进行持续的预训练,现有的大语言模型的性能也能得到显著而快速的提升。
团队采用了启发式规则进行文本过滤,从开源数据集中过滤到质量较低的语料。启发式规则能够有效识别和删除低质量数据,防止低质量预训练语料库影响模型性能表现。由于团队采用了多种来源的复合数据,基于数据多元性,团队专门设计了清理方法,并为每种方法量身制定规则,以保持数据质量的一致性。
|
|
文档级别和句子级别过滤 | 确保文本长度和字符意义一致 |
| 2 | 删除重复文本(n元语法和句子) | |
原创文章,作者:整数智能,如若转载,请注明出处:https://www.agent-universe.cn/2024/06/8362.html Like (0)
关于作者
那些悄咪咪阶跃的繁星(一)
Previous
2024-06-17 23:37
大模型日报(6月18日 资讯篇)
Next
2024-06-18 20:04
相关推荐
|