特别活动!


欢迎观看大模型日报,如需进入大模型日报群和空间站请直接扫码。社群内除日报外还会第一时间分享大模型活动。

推特
三大巨头同时版本更新:Google Gemini Pro 1.5、OpenAI GPT-4 Turbo、Mixtral 8x22B
11:01am:Google Gemini Pro 1.5 正式发布,这里是相关博客文章——他们的 100 万令牌上下文 GPT-4 级模型现在没有等待名单,可供 180 个国家(据我所知不包括欧洲或英国)的任何人使用,最令人印象深刻的是,所有 API 都有免费层,每天最多可以进行 50 个请求,但速率限制为每分钟 2 个。超过这个限制,您可以支付每百万输入令牌 7 美元和每百万输出令牌 21 美元,这比 GPT-4 Turbo 略低,比 Claude 3 Sonnet 略高。Gemini Pro 现在还支持音频输入和系统提示。
11:44am:OpenAI 终于发布了 GPT-4 Turbo 的非预览版,直接将 GPT-4 Vision 集成到模型中(以前是单独的)。Vision 模式现在支持函数和 JSON 输出,以前对图像输入不可用。OpenAI 还声称新模型”大幅改进”,但没有人知道他们指的是什么。
6:20pm(在他们的祖国法国是凌晨3:20):Mistral 在推特上发布了一个 281GB 的 Mixtral 8x22B 磁力 BitTorrent 链接——这是他们最新的开放许可模型版本,比他们之前最好的开放模型 Mixtral 8x7B 大得多。我还没有看到任何人运行这个模型,但考虑到原始 Mixtral 的优异表现,它很可能会表现得非常出色。
 https://x.com/simonw/status/1777927896881065989
https://x.com/simonw/status/1777927896881065989
Anthropic AI语言模型说服力的测量:每一代模型的说服力都比前一代模型更高
长期以来,人们一直在质疑AI模型是否会在某个时刻变得像人类一样有说服力,能够改变人们的想法。但是,关于模型规模与模型输出说服力之间关系的实证研究还比较有限。为了解决这个问题,我们开发了一种基本方法来衡量说服力,并用它来比较Anthropic的各种模型,这些模型跨越了三个不同的代(Claude 1、2和3)和两个类别的模型(更小、更快、更具成本效益的紧凑型模型,以及更大、更强大的前沿模型)。
在每一类模型(紧凑型和前沿型)中,我们发现了一个明显的跨代模型的缩放趋势:每一代模型的说服力都比前一代模型更高。我们还发现,我们最新、最强大的模型Claude 3 Opus生成的论点在说服力方面与人类写的论点没有统计学上的差异(图1)。
 https://x.com/AnthropicAI/status/1777728366101119101
https://x.com/AnthropicAI/status/1777728366101119101
在家里运行Command-R+模型!Carrigan分享教程
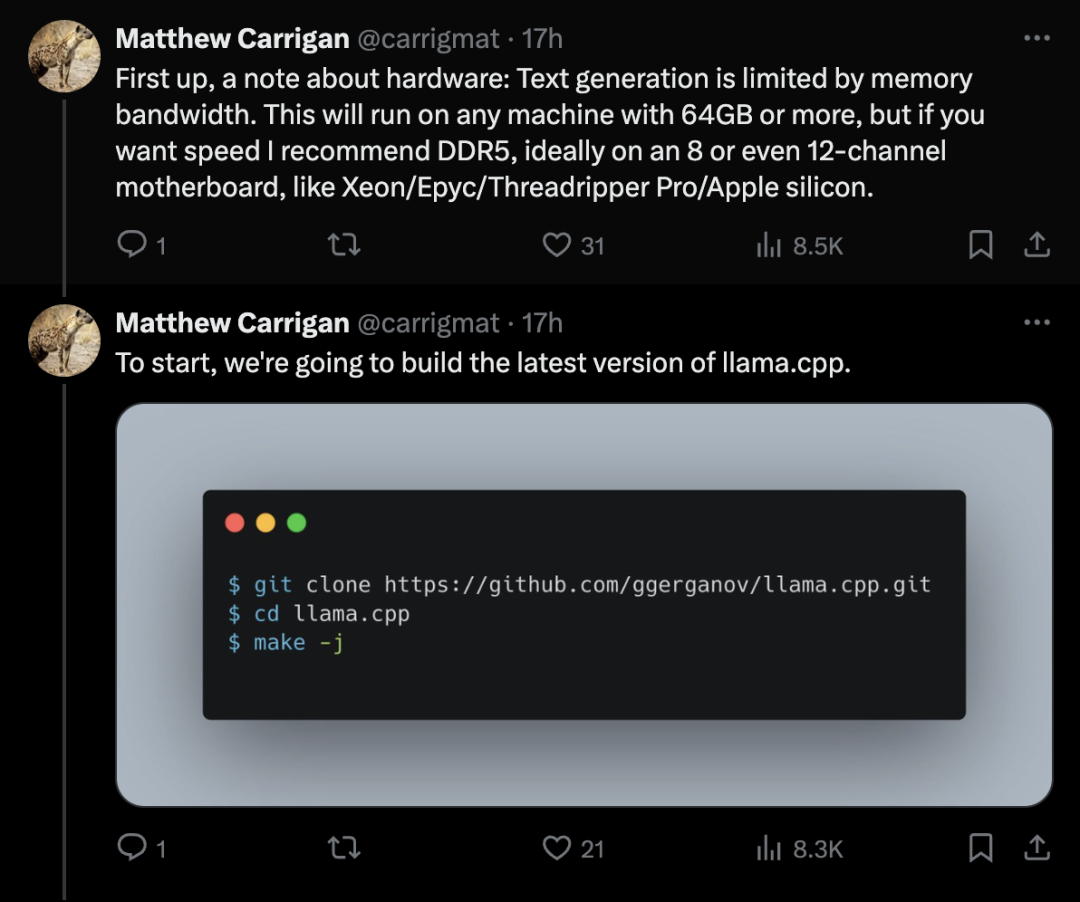
首先,关于硬件的说明:文本生成受内存带宽的限制。这可以在任何具有64GB或更多内存的机器上运行,但如果你想要速度,我建议使用DDR5,最好是在8通道或甚至12通道主板上,如Xeon/Epyc/Threadripper Pro/苹果芯片。
为了开始,我们将构建最新版本的llama.cpp。
接下来,我们将获取GGUF格式的压缩Command-R+模型和权重。在这里:
https://huggingface.co/dranger003/c4ai-command-r-plus-iMat.GGUF/tree/main…
下载你能装入RAM的最大尺寸,可能需要8-16GB的空间(所以在64GB时,尝试iq3_m或iq3_s,大约48GB)。更大的尺寸是分割的。
现在,让我们使用Command-R+附带的聊天模板准备我们的聊天。安装transformers,然后在Python中运行这个。你可以随意更改聊天内容。
结果是格式化的聊天,准备好传给llama.cpp。将其粘贴到llama.cpp目录中./main的-p参数中,并将你的GGUF文件传递给-m。-n是最大响应长度,以令牌为单位。
为了获得更高的性能,你可以增加更多的内存带宽或使用BLAS支持编译llama.cpp。你还可以使用Python绑定来完成整个过程,这样你就不必来回粘贴了。就是这样:在家中运行GPT-4!
另外,请注意,在较小的量化中,模型会变得更蠢。如果你在iq2上尝试这个,它给你一个可怕的答案,不要怪我!你可能需要128GB的RAM才能装下更高质量的Q6和Q8量化。
 https://x.com/carrigmat/status/1777689816383053855
https://x.com/carrigmat/status/1777689816383053855
UMD教授 Soheil Feizi 讲授深度学习基础:大型语言模型,第二部分
https://youtu.be/mxERaO8FXHc
 https://x.com/FeiziSoheil/status/1777766220617396437
https://x.com/FeiziSoheil/status/1777766220617396437
书生·浦语灵笔2:视觉语言模型,可以处理从336像素到4K高清的分辨率
InternLM-XComposer2-4KHD:一个开创性的大型视觉语言模型,可以处理从336像素到4K高清的分辨率。在16个基准测试中的10个显示出超越GPT4V和Gemini Pro的卓越能力。
https://github.com/InternLM/InternLM-XComposer
https://arxiv.org/abs/2404.06512
 https://x.com/arankomatsuzaki/status/1777872267709464618
https://x.com/arankomatsuzaki/status/1777872267709464618
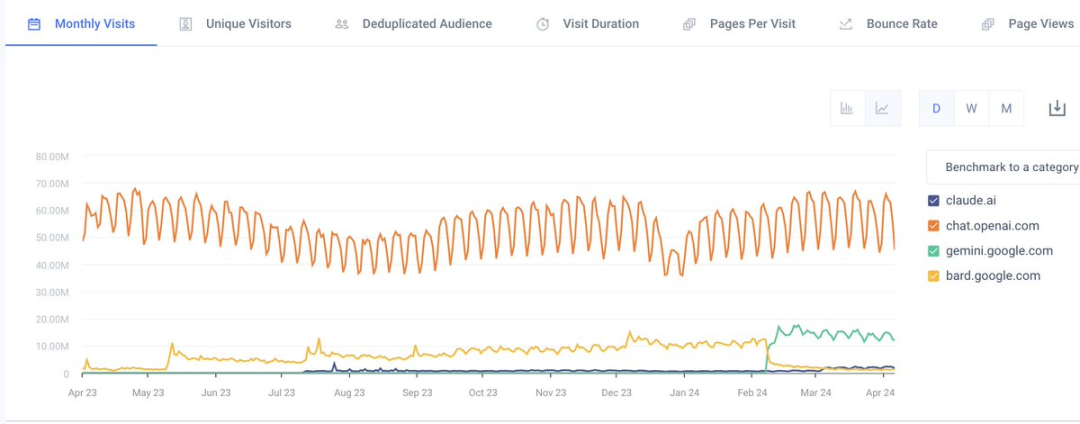
Nat Friedman分享三大语言模型用户数据:Gemini已经达到ChatGPT的25%, Cluade使用率仍然非常低
-
你知道吗,Gemini的流量已经达到了ChatGPT的25%左右?而且Google还没有通过他们巨大的分销渠道(Android、Google、GSuite等)推广它。
-
X上的关注度很高,但Claude的使用率仍然非常低。Anthropic是否应该做广告?
-
ChatGPT仍然是大品牌,但在过去一年中,使用率相对持平。为什么没有增长?OpenAI是受限于算力还是需求?
 https://x.com/natfriedman/status/1777739863678386268
https://x.com/natfriedman/status/1777739863678386268
资讯
全面突围,谷歌昨晚更新了一大波大模型产品
当地时间本周二,谷歌在 Google’s Cloud Next 2024 上发布了一系列 AI 相关的模型更新和产品,包括 Gemini 1.5 Pro 首次提供了本地音频(语音)理解功能、代码生成新模型 CodeGemma、首款自研 Arm 处理器 Axion 等等。
Mistral开源8X22B大模型,OpenAI更新GPT-4 Turbo视觉,都在欺负谷歌
在谷歌昨晚 Cloud Next大会进行一系列重大发布时,你们都来抢热度:前有 OpenAI 更新 GPT-4 Turbo,后有 Mistral 开源 8X22B 的超大模型。今年 1 月,Mistral AI公布了 Mixtral 8x7B 的技术细节,并推出了 Mixtral 8x7B – Instruct聊天模型。该模型的性能在人类评估基准上明显超过了 GPT-3.5 Turbo、Claude-2.1、Gemini Pro 和 Llama 2 70B 聊天模型。短短 3 个月后,Mistral AI 开源了 Mistral 8X22B 模型,为开源社区带来了又一个性能强劲的大模型。
马云内部发声:AI时代刚刚到来,我们正当其时
马云在文中认为,过去这一年阿里最核心的变化,不是去追赶KPI,而是认清自己,重回客户价值轨道。通过向大公司病开刀,阿里重新回归效率至上、市场至上,变得简单和敏捷。他认为新管理层“直面问题、直面未来,相信年轻人,对年轻团队充分授权,对于我们要什么,不要什么,做出了果断清晰的取舍”“不仅是突破昨日固化的战略,更是打造未来的阿里”。针对行业未来,马云判断“三、五年的时间跨度对于互联网领域而言,犹如一个世纪之久,足以发生翻天覆地的变化,AI时代刚刚到来,一切才刚开始,我们正当其时!”
Llama架构比不上GPT2?神奇token提升10倍记忆?
一个 7B 规模的语言模型 LLM 能存储多少人类知识?如何量化这一数值?训练时间、模型架构的不同将如何影响这一数值?浮点数压缩 quantization、混合专家模型 MoE、以及数据质量的差异 (百科知识 vs 网络垃圾) 又将对 LLM 的知识容量产生何种影响?近日,朱泽园 (Meta AI) 和李远志 (MBZUAI) 的最新研究《语言模型物理学 Part 3.3:知识的 Scaling Laws》用海量实验(50,000 条任务,总计 4,200,000 GPU 小时)总结了 12 条定律,为 LLM 在不同条件下的知识容量提供了较为精确的计量方法。作者首先指出,通过开源模型在基准数据集 (benchmark) 上的表现来衡量 LLM 的 scaling law 是不现实的。例如,LlaMA-70B 在知识数据集上的表现比 LlaMA-7B 好 30%,这并不能说明模型扩大 10 倍仅仅能在容量上提高 30%。如果使用网络数据训练模型,我们也将很难估计其中包含的知识总量。再举个例子,我们比较 Mistral 和 Llama 模型的好坏之时,到底是他们的模型架构不同导致的区别,还是他们训练数据的制备不同导致的?综合以上考量,作者采用了他们《语言模型物理学》系列论文的核心思路,即制造人工合成数据(),通过控制数据中知识的数量和类型,来严格调控数据中的知识比特数 (bits)。同时,作者使用不同大小和架构的 LLM 在人工合成数据上进行训练,并给出数学定理,来精确计算训练好的模型从数据中学到了多少比特的知识。
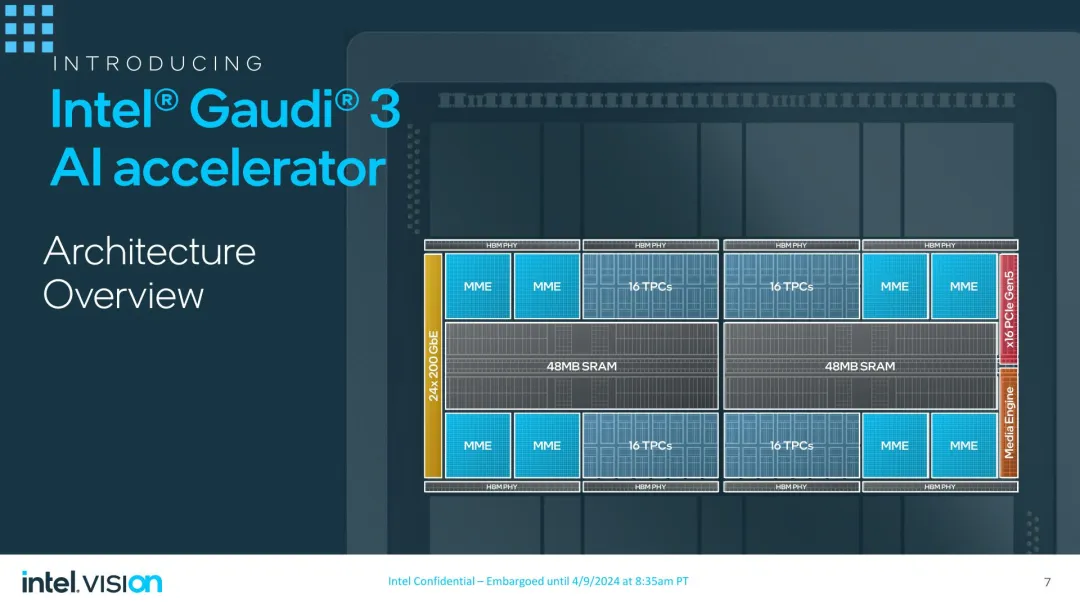
英伟达竞品来了,训练比H100快70%,英特尔发最新AI加速卡
英伟达的 AI 加速卡,现在有了旗鼓相当的对手。今天凌晨,英特尔在 Vision 2024 大会上展示了 Gaudi 3,这是其子公司 Habana Labs 的最新一代高性能人工智能加速器。Gaudi 3 将于 2024 年第三季度推出,英特尔现已开始向客户提供样品。凭借 1835 TFLOPS 的 FP8 计算吞吐量,英特尔相信它足以在广阔的(且昂贵的)AI 计算领域中分得一杯羹。根据内部基准测试,英特尔估计 Gaudi 3 性能部分超过了英伟达的 H100,并且具有更好的能耗比。在一些关键的大型语言模型中,Gaudi 3 能够击败英伟达的旗舰 H100/H200 Hopper 架构 GPU。在当前这个科技领域抢购英伟达 GPU 的时刻,Gaudi 3 或许能为英特尔在 AI 加速器市场打开一扇门。Gaudi 3 的发布也正值英特尔对其 AI 加速器产品的定位发生变化之际:当前,Gaudi 系列已升级为英特尔旗舰 AI 加速器。
开源模型首胜GPT-4!竞技场最新战报引热议,Karpathy:这是我唯二信任的榜单
能打得过GPT-4的开源模型出现了!大模型竞技场最新战报:1040亿参数开源模型Command R+攀升至第6位,与GPT-4-0314打成平手,超过了GPT-4-0613。这也是第一个在大模型竞技场上击败GPT-4的开放权重模型。大模型竞技场,可是大神Karpathy口中唯二信任的测试基准之一。Command R+来自AI独角兽Cohere。这家大模型创业公司的联合创始人兼CEO,正是Transformer最年轻作者Aidan Gomez()(简称割麦子)。
Google 仍在内耗,OpenAI 继续挖人
2022 年 11 月 ChatGPT 发布的热烈反响震惊了 Google,多年来 Google 运营着世界上两个最先进的机器学习团队。Google Brain 是构建语言模型的先驱,并且还发明了 Transformer 技术,OpenAI 用它来创建 ChatGPT。与此同时,DeepMind构建了能够精通国际象棋和围棋等游戏的 AI,但这两个团队经常因为一切从共享代码到计算资源而争执,两者都没有能够发布一个像 ChatGPT 那样在互联网上引起轰动的产品。在 OpenAI 发布 ChatGPT 几周内,Google CEO Sundar Pichai 指示 Google Brain 和 DeepMind 的高管合作开发一个被称为 Gemini 的单一 AI 模型,而不是追求分开的努力。与此同时,Pichai 开始准备一个更大的步骤:合并 AI 单位。DeepMind CEO Demis Hassabis 似乎并不热衷于这样的组合,他曾表示不确定是否想要领导这个联合单位,并且思考着离开 Google,筹集数十亿美元来启动一个新的研究实验室。这样的举动将使他能够从越来越多占据他时间的组织政治中重新开始。
 https://mp.weixin.qq.com/s/p3pAwj6r0diMXU_cnfqXXQ
https://mp.weixin.qq.com/s/p3pAwj6r0diMXU_cnfqXXQ
产品
Chat2DB
Chat2DB 是一款多数据库客户端工具,支持在 Windows、Mac 上进行本地安装,也支持服务器端部署和通过 web 网页访问。与传统的数据库客户端软件如 Navicat 和 DBeaver 相比,Chat2DB 集成了 AIGC 的能力,能够将自然语言转换为 SQL,也可以将 SQL 转换为自然语言,并且可以给出研发人员 SQL 的优化建议,极大地提升了人员的效率。它是 AI 时代数据库研发人员的利器,未来即使不懂 SQL 的运营业务也可以使用它进行快速查询业务数据和生成报表。
 https://chat2db.ai/
https://chat2db.ai/
Muraena.ai
Muraena.ai 是一款新的 B2B 潜在客户生成工具,旨在简化小型团队和销售发展代表(SDR)的整个潜在客户获取过程。该平台利用人工智能技术,以较低的价格、简单易用的特点,为用户带来更接近正确潜在客户的解决方案。
 https://muraena.ai/
https://muraena.ai/
墨芯人工智能完成数亿元A+轮和B轮融资,加速AI芯片研发
墨芯人工智能近半年内完成了数亿元人民币的A+轮和B轮融资。B轮融资由蚂蚁集团领投,盛景嘉成跟投;A+轮则由金浦投资上海金融科技基金领投,华大松禾天使基金等跟投。资金将用于公司二代AI芯片”Antoum”的研发、市场拓展及构建稀疏化生态。墨芯致力于通过稀疏计算技术,提供高算力、低功耗的AI算力服务,面向互联网、医疗等众多行业。公司产品主要聚焦大模型推理市场,旨在提升数据吞吐率,降低成本,提升整体TCO。
公司官网:http://www.moffettai.com/
 https://36kr.com/p/2724861966967815
https://36kr.com/p/2724861966967815
海港城获得数千万元A轮投资
海港城是一家人工智能大模型技术创新与应用落地公司,目前主打产品为抹香鲸APP,这是一款能够让你与人工智能技术创造的“角色”聊天实时互动,共同创造美好回忆的应用。公司日前数千万元A轮投资,投资方包括王慧文、嘉程资本等。
 https://new.qq.com/rain/a/20240409A05FFM00
https://new.qq.com/rain/a/20240409A05FFM00
特斯联完成20亿元D轮融资,国际、国有资本双领投
特斯联宣布完成20亿元人民币D轮融资,由国际投资机构AL Capital和国内产业基金阳明股权投资基金共同领投,加上多家新老股东跟投。融资将用于提升其垂直领域大模型的多模态能力,并构建高性能的智算基础设施,进一步在AIoT领域构建技术壁垒,加强国际竞争力。特斯联提出的“大模型+系统”技术路径,旨在通过深度结合具体场景的垂直领域模型,解决跨模态数据的建模难题,加速大模型的场景化落地。
 https://www.stcn.com/article/detail/1171108.html
https://www.stcn.com/article/detail/1171108.html
GoodGist Inc成功筹集100万美元资金,应对企业技能危机
GoodGist Inc,一家在企业技能发展和知识管理自动化领域的创新企业,宣布成功筹集100万美元资金。本轮融资由FortyTwo.VC, Cedar Ridge Ventures, DX Partners以及来自微软和亚马逊等领先技术公司的著名天使投资者参与。资金将用于推出其多语言平台,扩大团队,加强研发力度,并改进产品以缓解技能差距和信息过载问题。GoodGist Inc旨在利用其先进的AI Curator及其专利技术,个性化地促进个人的学习和研究旅程,加快劳动力的技能提升和再培训。
公司官网:https://www.goodgist.com/#/new
 https://www.accesswire.com/849867/goodgist-inc-secures-1-million-funding-in-fight-against-corporate-skills-crisis
https://www.accesswire.com/849867/goodgist-inc-secures-1-million-funding-in-fight-against-corporate-skills-crisis
Symbolica通过符号模型押注,希望避免AI军备竞赛
Symbolica AI,由前特斯拉工程师George Morgan创立,致力于开发新型AI模型,以减少数据需求和训练时间,降低成本,并提供结构化输出。公司已成功获得由Khosla Ventures领投的3300万美元投资,其他投资者包括Abstract Ventures、Buckley Ventures、Day One Ventures和General Catalyst。Symbolica的产品是一个为特定任务(如代码生成和数学定理证明)预训练的符号AI模型工具包,公司计划与大型企业合作伙伴和客户紧密合作,开发定制模型,以提高推理能力,并销售先进的代码合成模型。
公司官网:https://www.symbolica.ai/
 https://www.reuters.com/technology/symbolica-raises-31-mln-develop-ai-systems-compete-with-openai-2024-04-09/
https://www.reuters.com/technology/symbolica-raises-31-mln-develop-ai-systems-compete-with-openai-2024-04-09/
GTM Buddy获得800万美元融资,解决B2B销售渠道漏损问题
GTM Buddy,一家AI驱动的销售使能平台,宣布在与Archerman Capital和Leo Capital的合作下,成功融资800万美元A轮资金。该轮融资还得到了Neon Fund和Stellaris Venture Partners的参与。融资将用于推动收入增长,增强销售使能力,并成为解决销售渠道漏损问题的答案。GTM Buddy推出了包括动态销售策略和AI生成的销售模板在内的AI驱动的销售成功解决方案,旨在通过利用AI提高销售代表的效率,填补销售执行中的漏洞。
公司官网:https://gtmbuddy.ai/
 https://venturebeat.com/ai/gtm-buddy-raises-8-million-to-fix-leaky-b2b-sales-funnels/
https://venturebeat.com/ai/gtm-buddy-raises-8-million-to-fix-leaky-b2b-sales-funnels/
AI数据安全初创公司Cyera确认以14亿美元估值融资3亿美元
Cyera, 一家AI数据安全初创公司,已成功完成3亿美元的C轮融资,公司估值达到14亿美元。该轮融资由Coatue领投,Spark Capital、Georgian及AT&T Ventures等新投资者参与。这标志着公司估值在不到一年的时间里几乎翻了三倍。Cyera开发了一个AI平台,帮助组织理解网络中所有数据的位置和流动,以采取正确的安全措施。此次融资将用于继续扩大其数据安全平台的产品和服务。
公司官网:https://www.cyera.io/
 https://techcrunch.com/2024/04/09/ai-data-security-startup-cyera-confirms-300m-raise-at-a-1-4b-valuation/
https://techcrunch.com/2024/04/09/ai-data-security-startup-cyera-confirms-300m-raise-at-a-1-4b-valuation/
Reshape通过计算机视觉自动化实验室试验,加速生物技术研发
Reshape,一家丹麦初创公司,通过开发配备软件和AI模型的机器人成像系统,帮助科学家追踪培养皿等容器中的视觉变化,以自动化需要视觉检查的实验室试验。公司在A轮融资中筹集了2000万美元,计划将其技术扩展到美国市场。Reshape的系统能够实现特定温度的内置孵化,同时记录数据,确保实验能够轻松重复,从而实现24/7无人直接监管的运行,释放技术人员从事其他关键任务。
公司官网:https://www.reshapebiotech.com/
 https://techcrunch.com/2024/04/09/reshape-wants-to-accelerate-biotech-rd-by-bringing-computer-vision-to-lab-experiments/
https://techcrunch.com/2024/04/09/reshape-wants-to-accelerate-biotech-rd-by-bringing-computer-vision-to-lab-experiments/
PETE获得200万美元种子轮融资,推动下一代劳动力学习
PETE,一家位于奥兰多的AI教育技术初创公司,成功完成了200万美元的种子轮融资,由Cofounders Capital领投。该轮融资还包括来自奥兰多地区的天使投资者。资金将用于推广公司的销售和战略营销活动,并继续开发其专利待定的AI技术。PETE旨在为个性化和自适应的培训体验提供成本效益高的AI驱动学习解决方案。
公司官网:https://www.pete.com/
 https://www.pete.com/blog/orlando-based-ai-edtech-startup-pete-secures-2-million-in-seed-funding
https://www.pete.com/blog/orlando-based-ai-edtech-startup-pete-secures-2-million-in-seed-funding

大模型日报16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/16227.html