欢迎观看大模型日报 , 如 需 进 入 大 模 型 日 报 群 和 空 间 站 请 直 接 扫 码 。 社 群 内 除 日 报 外 还 会 第 一 时 间 分 享 大 模 型 活 动 。
推特 震惊!爆火推特7万点赞:由AI生成的弹钢琴的忧郁女孩演绎MIT许可证的文本内容 由AI生成的弹钢琴的忧郁女孩演绎MIT许可证的文本内容。 https://x.com/goodside/status/1775713487529922702
Anthropic新研究论文:多样本越狱 我们研究了一种长上下文越狱技术,对大多数大型语言模型都有效,包括由Anthropic和我们的许多同行开发的模型。 https://x.com/AnthropicAI/status/1775211248239464837 Stable Audio 2.0发布:根据单一自然语言提示生成高质量、完整的音轨 今天,我们很高兴地介绍 Stable Audio 2.0。该模型能够根据单一自然语言提示生成高质量、完整的音轨,长度可达 3 分钟,采样率为 44.1 kHz 立体声,具有连贯的音乐结构。 新模型不仅具备文本到音频的功能,还包括音频到音频的能力。用户现在可以上传音频样本,并通过自然语言提示将这些样本转换成各种声音。此次更新还扩展了音效生成和风格迁移功能,为艺术家和音乐家提供了更多的灵活性、控制力和更高的创作过程。 Stable Audio 2.0 建立在 Stable Audio 1.0 的基础之上。Stable Audio 1.0 于 2023 年 9 月首次亮相,是第一个商业上可行的 AI 音乐生成工具,利用潜在扩散技术能够生成高质量的 44.1kHz 音乐。此后,它被 TIME 杂志评为 2023 年最佳发明之一。 https://x.com/StabilityAI/status/1775501906321793266
Opera允许用户在本地下载和使用大语言模型,使用Ollama开源框架 Opera浏览器现在允许用户在本地计算机上下载和运行大语言模型 网络浏览器公司Opera今天宣布,现在允许用户在本地计算机上下载和使用大语言模型(LLM)。此功能首先向获得开发者流更新的Opera One用户推出,将允许用户从超过50个家族的150多个模型中进行选择。 这些模型包括Meta的Llama、Google的Gemma和Vicuna。作为Opera的AI功能下降计划的一部分,此功能将提供给用户,让用户能够提前使用一些AI功能。 该公司表示,它在浏览器中使用Ollama开源框架在你的计算机上运行这些模型。目前,所有可用的模型都是Ollama库的子集,但未来,公司希望包括来自不同来源的模型。 https://techcrunch.com/2024/04/03/opera-will-now-allow-users-download-and-use-llms-locally/?utm_source=tldrai Qwen1.5-32B和Qwen1.5-32B-Chat发布:仅仅稍微落后于72B模型 今天,我们发布了Qwen1.5系列的新模型:Qwen1.5-32B和Qwen1.5-32B-Chat! 博客:https://qwenlm.github.io/blog/qwen1.5-32b Hugging Face:https://huggingface.co/Qwen,在模型名称中搜索包含”Qwen1.5-32B”的仓库。 GitHub:https://github.com/QwenLM/Qwen1.5 长期以来,我们的用户一直要求我们提供一个30B规模的模型,因为它应该比13-14B的模型更有能力,但在部署和微调方面对计算资源的需求比70B的模型少得多。 在我们的基准测试中,我们发现基础模型和聊天模型在语言理解、多语言评估、编程、数学等方面的评估中都能达到与最新SOTA模型相当的性能,它们只是稍微落后于72B模型。 我们希望新模型能够为您的研究和开发做出贡献,并期望它能够推动微调模型和应用程序的发展!尽情享用吧! https://x.com/Alibaba_Qwen/status/1776262376700223968 AssemblyAI推出Universal-1:强大的语音识别模型,多语言音频数据上训练 介绍Universal-1,我们迄今为止最强大的语音识别模型。 Universal-1在超过1250万小时的多语言音频数据上进行了训练,在英语、西班牙语、法语和德语中实现了业界最佳的语音转文本准确率。 http://assemblyai.com/research/universal-1 https://x.com/AssemblyAI/status/1775527556042629437?s=20
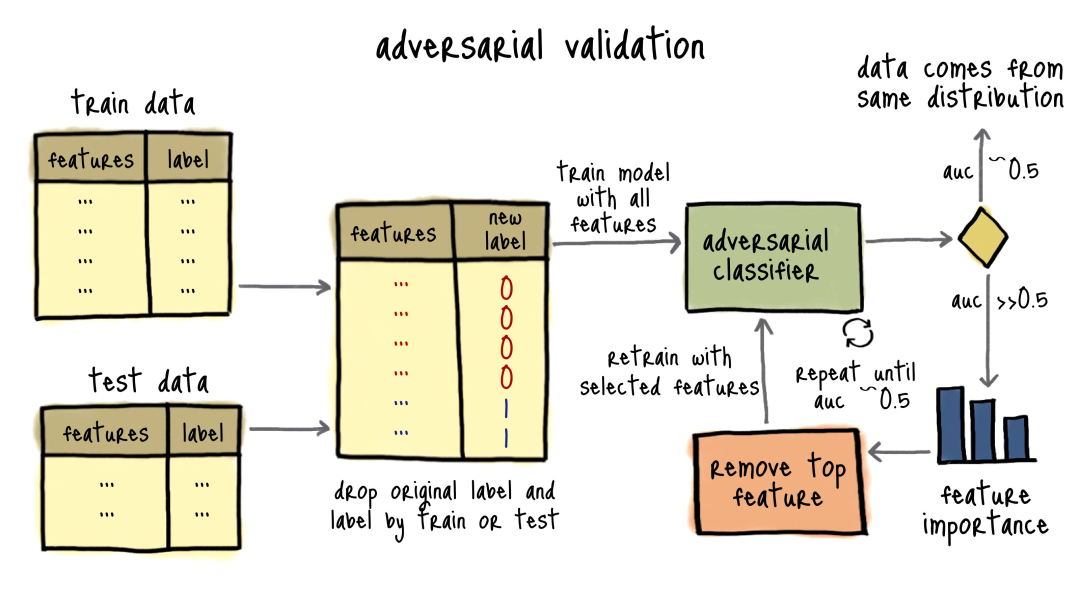
Santiago分享对抗验证(Adversarial Validation):如何判断数据集是否同源 我想给你展示一个聪明的技巧。假设你有六个月的数据,用前五个月训练模型,最后一个月测试。这是常见方法,但可能出现过拟合。在尝试修复前,先回答:测试数据和训练数据是否来自同一分布?
创建新的二元特征,训练集样本为0,测试集样本为1,作为新目标。
训练简单的二元分类模型,预测样本来自训练集还是测试集。
如果AUC接近0.5,说明数据来自同一分布;如果AUC接近1.0,说明数据来自不同分布。这种技术叫对抗验证,可快速判断数据集是否同源。
重新计算ROC-AUC,重复直到AUC接近0.5。
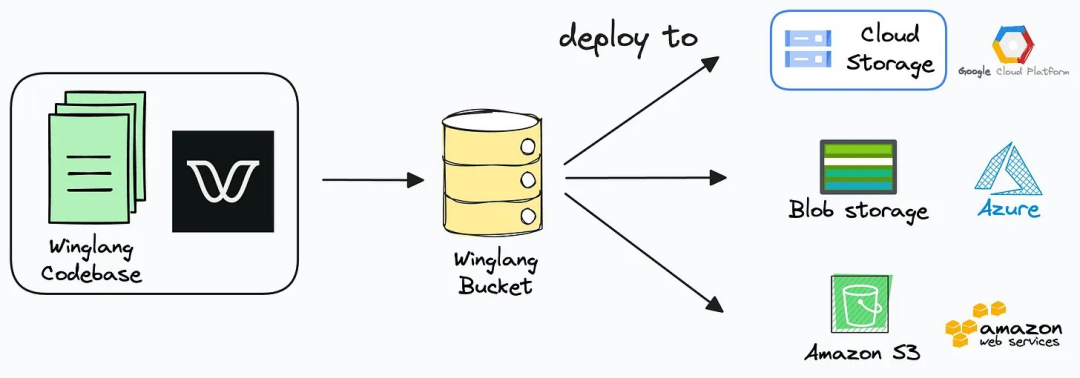
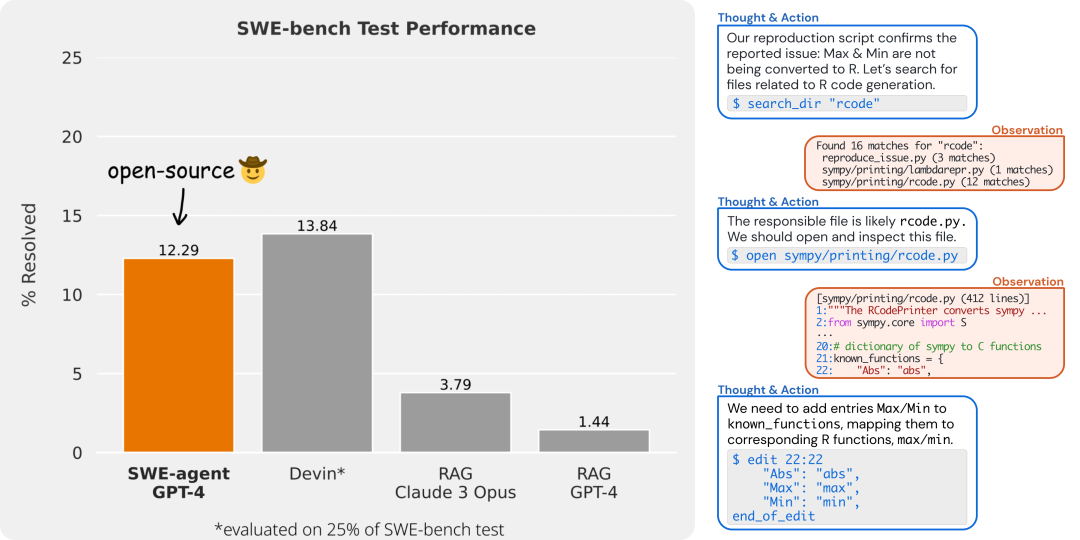
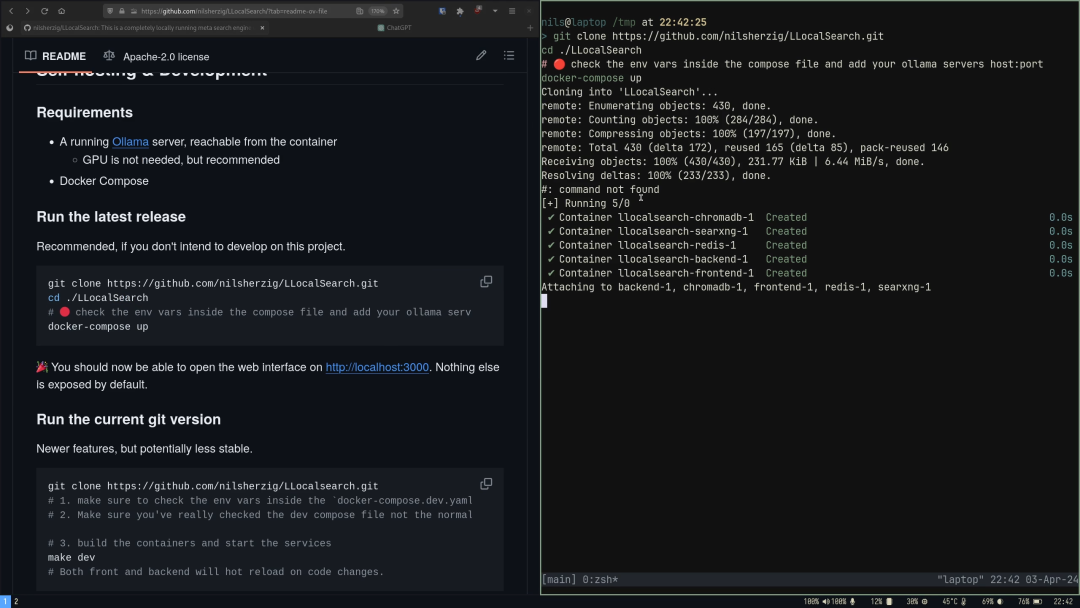
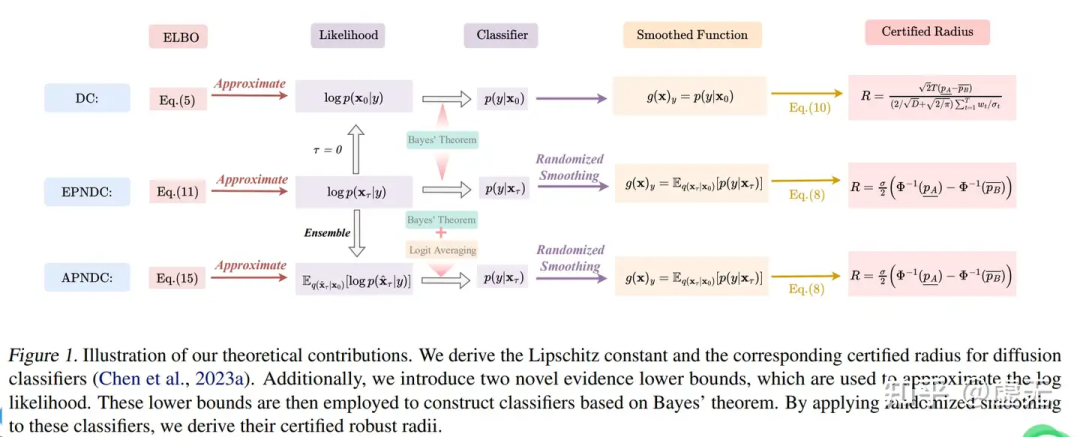
对抗验证在识别生产环境中的分布偏移时特别有用,投资少回报高。 https://x.com/svpino/status/1775154270708396215 Winglang:一种从头开始为云设计的开源语言 AWS CDK的创建者创建了Winglang,这是一种从头开始为云设计的开源语言。 Winglang通过定义标准API来抽象云提供商之间的差异。 无论你想使用AWS、GCP、Azure还是自定义平台,你都可以使用抽象API,稍后编译并部署到任何云提供商。 我这里有一个结合Winglang和OpenAI API的例子。这将帮助你理解它的强大功能: 在这个例子中,你会注意到一些关键点:你可以专注于业务逻辑而不是云机制。在需要之前,你不必担心底层细节。 你可以在这个GitHub仓库(/examples文件夹)中找到这个例子: 感谢Winglang背后的团队与我合作完成这篇文章。 https://x.com/svpino/status/1775514012660236601?s=20 山姆奥特曼:电影将变成电子游戏,而电子游戏将变成难以想象的更好的东西 电影将变成电子游戏,而电子游戏将变成难以想象的更好的东西。 https://x.com/sama/status/1776083954786836979?s=46&t=GRStLXDcUNuun8J5Noyw4Q Shawn Wang:Claude 拥有高达100万 token 的上下文长度,且具有接近完美的记忆力,自信地处理250多个工具 被低估的结果是: @AnthropicAI 的Claude 拥有高达100万 token 的上下文长度,且具有接近完美的记忆力:Claude现在可以自信地处理250多个工具! 当OpenAI的函数调用首次推出时,我想是@simonw 指出由于上下文限制,我们需要”深度”函数-实际上通常最多只有5-10个工具。 现在我们不再有这个问题-Claude现在明确建议”扁平化”工具结构,甚至内置了一些很好的功能,比如思维链”<thinking>” 工具的使用以及带有搜索质量分数的”<search_quality_reflection>”! https://x.com/swyx/status/1775993946935906645?s=46&t=GRStLXDcUNuun8J5Noyw4Q Crescendo:多轮LLM越狱攻击 作为我们在AI安全方面持续工作的一部分,我们发现了一种强大而简单的LLM越狱方法,它利用了我们称之为 “crescendo”的内在LLM行为,并在主要LLM模型和服务的数十个任务上进行了演示:…https://crescendo-the-multiturn-jailbreak.github.io https://x.com/markrussinovich/status/1775966804311183496?s=46&t=GRStLXDcUNuun8J5Noyw4Q AI Fund宣布Workhelix即将推出:基于任务的分析创造商业价值,对职位描述、专业社交数据等进行分析 基于任务的分析,即研究人工智能如何影响工作,是创造商业价值的一种强大技术。这是由Workhelix的Erik Brynjolfsson等人率先提出的。现在,Workhelix已经开发出技术,可以通过自动检查公司的职位描述、专业社交数据和其他信息,在更大范围内应用这一技术,为CEO和董事会提供创造价值的路线图。 AI Fund很高兴支持Workhelix的发布,该发布定于4月9日星期二举行。要了解更多信息,请加入Erik Brynjolfsson、Andrew McAfee、Daniel Rock、James Milin和我在下面的网络研讨会中的对话! https://us06web.zoom.us/webinar/register/6617123414756/WN_Lehgx3_LTrq7AZcwgKeOzw https://x.com/AndrewYNg/status/1776363779141628369 产品 HIPAA SmartChat Assistant HIPAA SmartChat Assistant 是 QuickBlox 公司推出的一款符合 HIPAA 标准的智能聊天助手。它旨在满足医疗保健应用程序对无缝虚拟协助的需求,提供强大且用户友好的功能。这款智能助手具有无代码仪表板,可以让用户轻松构建个性化的 AI 助手,满足各种技术水平的医疗保健专业人员的需求。同时,它考虑到了医疗保健领域的隐私和数据安全,确保数据始终在用户的控制范围内,不会与第三方共享敏感的医疗保健信息。此外,用户还可以使用自己的医疗保健知识库训练 SmartChat Assistant,从而提供量身定制的互动,精确满足患者的需求。 https://quickblox.com/products/ai/healthcare-chatbot/ Airdrop Tracker Airdrop Tracker 旨在帮助用户找到和参与 DeFi 领域的空投活动。通过 AI 数据聚合,它提供了一个方便的平台,使用户能够轻松发现他们有资格参与的空投活动,使用 AI 助手构建适合用户的 DeFi 投资组。 https://defi.oneclick.fi/airdrops/explore Intellectia Intellectia.AI 通过人工智能技术为全球投资者提供智能化的金融平台。他们的愿景是利用 AI 自主代理解读海量数据,为用户提供宝贵见解,并通过 AI 技术实现金融信息的民主化,让所有投资者都能轻松获取并利用金融智能。其产品特点包括 AI 动力金融聊天助手、每日热门股票推荐、技术分析、价格驱动因素解析、事件标记、摘要和互动问答等功能,以及 AI 发布和 AI 会议等特色服务。 https://intellectia.ai/use-case Metaforms Metaforms 是 Typeform 的 AI 继任。旨在构建世界上最强大的反馈、调查和用户研究平台,根据公司的背景和关心的数据点,借助 AI 决定如何收集用户需要的数据。结合其他用户响应提出后续问题,更深入地挖掘用户关心的问题,以做出更好的决策并更快地验证假设。 https://metaforms.ai/ H uggingFace&Github plandex Plandex 是一个开源的、基于终端的 AI 编码引擎,用于复杂任务。它将大型任务分解为较小的子任务,然后实现每个子任务,继续直到完成。它可以帮助用户处理积压工作,使用不熟悉的技术,摆脱困境,并减少在无聊的事情上花费的时间。 h ttps://github.com/plandex-ai/plandex SWE-agent SWE-agent 将 LLM(例如 GPT-4)转换为软件工程代理,可以修复实际 GitHub 存储库中的错误和问题。在 类似产品的测评中,SWE 代理成功解决了 12.29% 的问题,在整个测试集上实现了最先进的性能。 https://github.com/princeton-nlp/SWE-agent LLocalSearch LLocalSearch 是一个使用 LLM 代理的本地运行搜索聚合器。用户可以提出一个问题,系统将使用一连串来LLMs找到答案。用户可以看到代理的进度和最终答案。不需要提供 OpenAI 或 Google API 密钥。 https://github.com/nilsherzig/LLocalSearch 投融资 Archetype AI推出基础模型引领物理AI新时代 Archetype AI,一家物理AI公司,宣布结束隐秘开发阶段并推出Newton™,这是一款首创的基础模型,旨在理解物理世界。该公司通过Newton™致力于利用人工智能的力量解决现实世界问题,为人们和组织提供前所未有的对物理环境的理解。为支持这一使命,Archetype AI完成了由Venrock领投的1300万美元种子轮融资,Amazon Industrial Innovation Fund、Hitachi Ventures、Buckley Ventures、Plug and Play Ventures及多位天使投资者参与。这标志着AI在理解隐藏在物理世界中的复杂或快速变化模式方面的一大进步,Newton™能够整合多模态时间数据与自然语言,实时解锁关于物理世界的洞见。 公司官网:https://www.archetypeai.io/ https://www.businesswire.com/news/home/20240405306572/en/Archetype-AI-Introduces-Foundation-Model-to-Pioneer-Physical-AI 比利时计算机视觉初创公司Robovision计划美国扩张以解决劳动力短缺问题 比利时的计算机视觉初创公司Robovision旨在使深度学习工具更易于非核心技术公司的业务访问。该公司在一轮由Astanor Ventures和Target Global共同领投的系列A融资中筹集了4200万美元,目标是扩展到美国市场,针对面临劳动力短缺的工业和农业商业领域。Robovision的“无代码”AI平台允许用户上传数据、标记数据、测试他们的模型,并部署,而无需在每一步都涉及软件开发人员或数据科学家。服务于45个国家的客户,Robovision的技术应用于识别超市水果、识别新制电子组件的故障以及切割玫瑰茎。有了这笔资金,Robovision计划扩大其在制造业和农业中的影响力,特别是利用其在农技领域的记录,在那里它协助种植每年十亿朵郁金香。 公司官网:https://robovision.ai/ https://techcrunch.com/2024/04/05/robovision-computer-vision-belgium/ SiMa.ai获7000万美元融资 推出多模态GenAI芯片 SiMa.ai,一家位于硅谷的初创公司,专注于生产嵌入式机器学习系统芯片平台,宣布已经完成了7000万美元的扩展融资轮。这次融资将帮助公司推出其针对多模态生成式人工智能处理的第二代芯片。SiMa.ai的产品目标是将深度学习工具工业化,并使其更易于不以技术为核心的企业获取。该公司已在全球45个国家的超过50家公司中使用其芯片和无代码软件。SiMa.ai的新一代GenAI SoC芯片计划于2025年第一季度推出,强调为客户提供多模态GenAI能力,预计将对现有芯片进行“一些架构调整”,但基本概念保持不变。 https://techcrunch.com/2024/04/04/sima-ai-70m-funding-multimodal-genai-chip/ Higgsfield AI获得800万美元种子融资,开启个性化AI视频创作 Higgsfield AI,一家致力于使社交媒体视频创作民主化的初创公司,宣布获得由Menlo Ventures领投的800万美元种子融资。这一资金将支持其使几乎每个人都能轻松制作引人入胜、个性化且可分享的视频的使命,通过其专有视频模型和直观的Prompt Builder,用户可以使用文本提示、参考图像或视频轻松创建原创内容。 公司官网:https://higgsfield.ai/ https://www.businesswire.com/news/home/20240403369573/en/Higgsfield-AI-Secures-8M-in-Seed-Funding-to-Unlock-Personalized-AI-Video-Creation
TrojAI获得575万美元种子轮融资,加强企业AI安全 TrojAI,一家在企业人工智能(AI)安全解决方案领域处于领先地位的公司,宣布完成575万美元的种子轮融资,并任命Lee Weiner为公司首席执行官。本轮融资由Flying Fish领投,Build Ventures、Techstars、Alteryx Ventures和Flybridge Capital Partners等现有投资者和新投资者参与。这笔资金将用于支持产品开发、销售和市场营销工作,以及公司向美国扩张,在波士顿新设办事处。 公司官网:https://www.troj.ai/ https://www.prnewswire.com/news-releases/trojai-raises-5-75m-in-seed-funding-to-secure-ai-in-the-enterprise-302106426.html 泰国的HD公司在获得560万美元融资后进入AI领域,开发医疗聊天机器人 泰国健康科技公司HD,被誉为“手术的Airbnb”,近期获得了560万美元A轮融资,由SBI Ven Capital领投。该公司计划开发一款专注于医疗领域的AI驱动对话聊天机器人,旨在处理常规客户问题,释放人员处理更复杂的问题,并确保客户服务全天候可用。HD计划利用其大量匿名的健康产品、交易和聊天商务数据来训练这款聊天机器人,并计划在未来三个月内在其HDmall市场上推出此服务,最终还计划在年底前将聊天机器人提供给第三方,如医院和诊所。 https://www.techinasia.com/thaibased-hd-secures-56m-funding-healthcare-chatbots Y Combinator 2024冬季批次中最受瞩目的AI创业公司 尽管整体的创业投资有所下降,但过去一年AI领域的资金却大幅增长。Y Combinator 2024冬季Demo Day上,AI创业公司成为了主角。本次批次共有86家AI创业公司,几乎是2023冬季批次的两倍,接近2021冬季批次的三倍。从政府合同自动化处理的Hazel,到为家庭护士减负的Andy AI,再到通过AI提供精确天气预报的Precip,以及旨在通过AI指导加强情侣关系的Maia,这些公司因其技术、市场潜力或创始人背景而脱颖而出。 https://techcrunch.com/2024/04/03/y-combinator-winter-2024-demo-day-ai-startups-standouts/ 学习 矩阵乘法性能与形状优化关系解析 文章探讨了矩阵乘法的性能与其形状之间的关系。作者发现,矩阵乘法的执行时间不仅与操作数量有关,还受到矩阵形状的影响。特别地,当矩阵的形状符合特定的规模时(如2的幂),其性能可以显著提高。这种现象主要由三个因素解释:计算密集度/并行化、平铺(Tiling)、波量化(Wave Quantization)。文章通过详细分析这些因素如何影响GPU上矩阵乘法的性能,揭示了优化这一过程的可能途径。此外,文章还探讨了内存布局对性能的影响,以及如何通过调整矩阵大小和形状来避免性能损失。 https://www.thonking.ai/p/what-shapes-do-matrix-multiplications 高效序列建模系列: 1. Mamba(SSM)和Linear Attention的统一视角 文章探讨了序列建模方法之间的联系,提出了一个统一视角来理解Mamba(SSM)和Linear Attention等模型。作者通过定义序列映射和介绍基于记忆的序列映射过程(Expand, Oscillation, Shrink,简称EOS),阐述了不同序列模型的内在联系。这一过程包括从输入状态到扩展状态的映射、在高维空间中的振荡状态处理,以及最终通过缩减状态返回到低维输出。该文章不仅提供了一种新的理解序列模型的框架,还探讨了不同模型如何在此框架下进行有效的序列映射,为后续的序列建模研究和应用提供了新的视角和方法。 https://zhuanlan.zhihu.com/p/690227740 你的扩散模型是个可证明的鲁棒分类器 文章探讨了扩散分类器(diffusion classifier)的鲁棒性。作者首先表明了人们对扩散分类器鲁棒性的质疑,并提出了通过计算其鲁棒性下界来回应这些质疑。文章通过详细的推导过程,展示了如何为扩散分类器计算Lipschitz常数,从而评估其在面对对抗样本时的鲁棒性。利用随机平滑(randomized smoothing)技术和高斯分布的性质,作者成功证明了扩散分类器可以具有一定的鲁棒性范围。此外,通过改进的扩散分类器构造方法和实验验证,作者展示了其在CIFAR-10数据集上达到了显著的鲁棒半径,强化了扩散分类器在安全性方面的可行性。 https://zhuanlan.zhihu.com/p/690230490 世界上收敛最快的计算 π 的公式是什么? 关于这一问题,知乎上的讨论集中在几个著名的公式上。其中最被广泛提及的包括:
拉马努金公式:这是一个著名的公式,以其极快的收敛速度而闻名。特别是拉马努金的一系列公式中,某些变体可以让计算的每一项都大约增加50位的有效数字,显示出极高的效率。
博温兄弟的迭代方法:这是一个通过迭代逼近π的方法,每次迭代都会显著提高精度。这种方法以其简单和高效的迭代步骤被多次提及。
丘德诺夫斯基公式:作为拉马努金公式的改良版,它同样具有非常快的收敛速度,被视为计算π的强大工具。
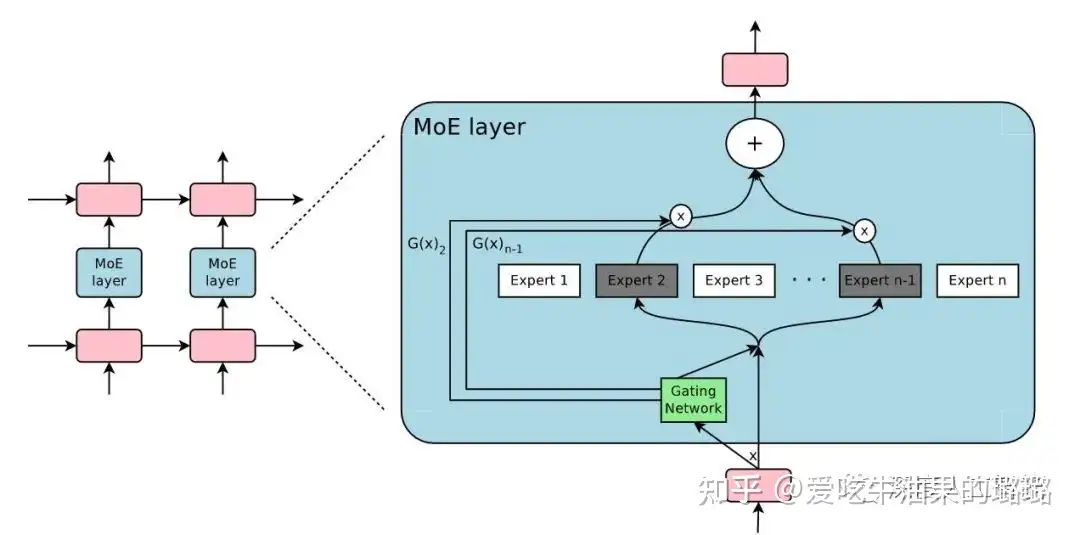
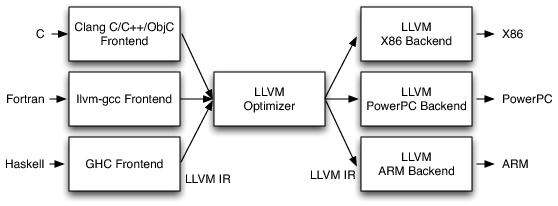
这些讨论不仅展示了计算π的多种高效方法,还体现了数学界在寻找更优算法方面的不懈努力和创新。每种方法都有其独特的优点和适用场景,选择哪一种取决于特定需求,比如计算的精度要求、算法的实现复杂度等。 https://www.zhihu.com/question/318010986 MoE中的各expert网络内结构是什么?训练过程中如何使得不同expert学到不同的feature? MoE是一种先进的深度学习框架,用于处理大规模模型训练和推理的高效性和可扩展性问题。MoE通过将输入数据根据任务类型分割成多个区域,并将每个区域的数据分配给一组专家模型处理,每个专家模型可以专注于其擅长的领域,从而提高整体模型性能。核心机制包括一个门控网络(GateNet),负责决定哪个专家模型处理特定输入数据,以及多个专家模型(Experts),每个专家负责处理特定的输入子空间。MoE模型的特点是稀疏性,通过门控网络的设计和参数调整来有效控制。该模型能够实现因材施教,在推理过程中实现专家模型间的优势互补,适用于大规模和复杂的深度学习任务,特别是在多模态情境下的应用。 https://www.zhihu.com/question/564792024/answer/3455145719 揭示GPU上的批处理策略 文章深入探讨了批处理在现代GPU上的应用原理及其对深度学习模型推理速度的影响,提供了关于模型优化的实用指南。文章指出,通过优化批处理策略,可以更高效地利用计算资源,提升模型推理效率。在GPU上进行批处理时,并发性允许同时运行多个操作,这意味着处理整个批次的时间与处理单个示例的时间几乎相同。文章还讨论了在不同的网络类型(如MLP、卷积网络和Transformer)上进行批处理的具体细节和效率问题,揭示了GPU在数学计算上的快速性能,同时也指出了其他潜在的计算开销。 LLVM在GPU中的局限性 这篇文章详细探讨了LLVM作为编译器中间表示(IR)在处理GPU架构时遇到的挑战。尽管LLVM在CPU编译领域表现出色,通过提供目标无关的IR以支持各种CPU架构,但其设计并不适合GPU。原因在于GPU编译需要依赖于特定架构的内部函数和运行时API,这些都是LLVM所不具备的。文章通过一个简单的向量加法程序示例,展示了即便使用基于LLVM的AdaptiveCPP编译器,也不能直接将LLVM IR应用于所有GPU架构,揭示了未来研究的方向在于开发能同时支持CPU和GPU的通用IR。 https://chsasank.com/intermediate-representations-for-gpu.html
大模型日报 16
大模型日报 · 目录
上一篇 大模型日报(4月2日)
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/16345.html