特工少女说:顾洲洪老师是复旦大学数据科学博士,最近新发表了一篇《AgentGroupChat: An Interactive Group Chat Simulacra For Better Eliciting Emergent Behavior》的论文,此文是顾老师自己对论文的解读,经授权转载自顾老师的知乎,点击文末阅读原文可跳转原文链接,学术交流可加文末顾老师的微信。
AI 争夺家产继承权?AI 律师如何辩护?AI 哲学家如何思考?AI 明星如何争夺主演资格?如果你对这些感兴趣,那么可以来看看顾老师最新的研究。
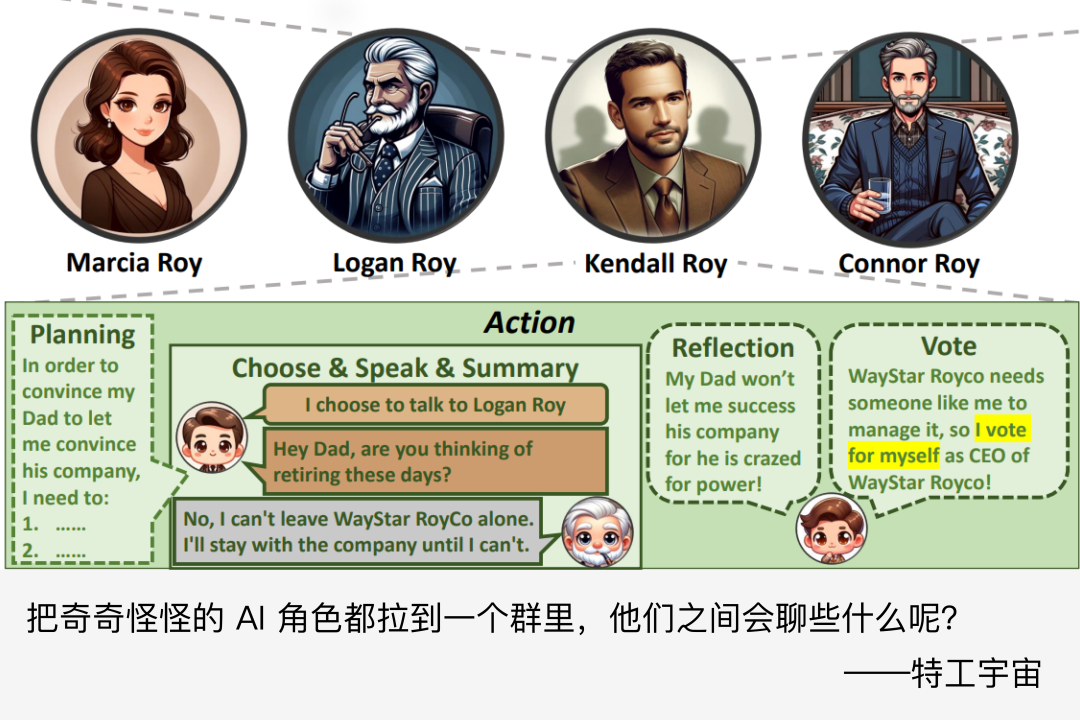
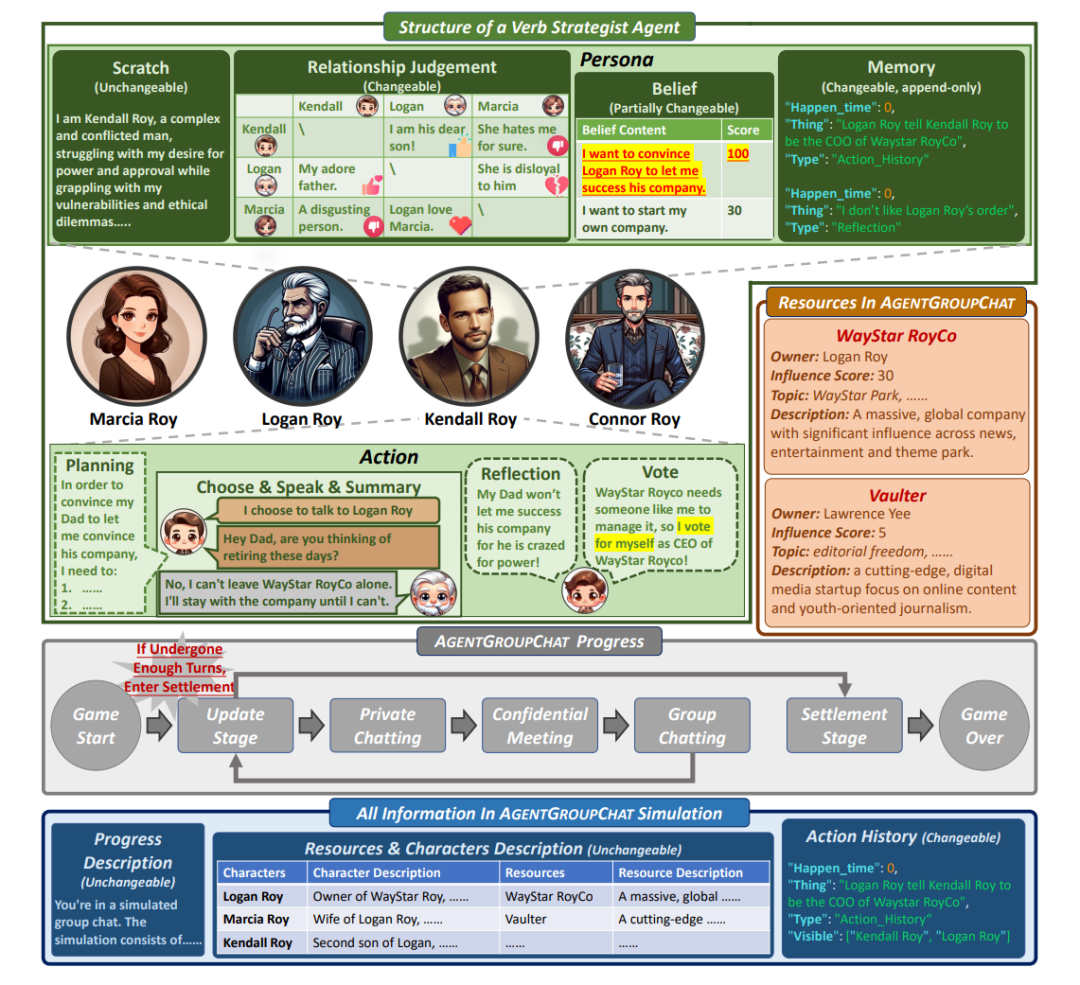
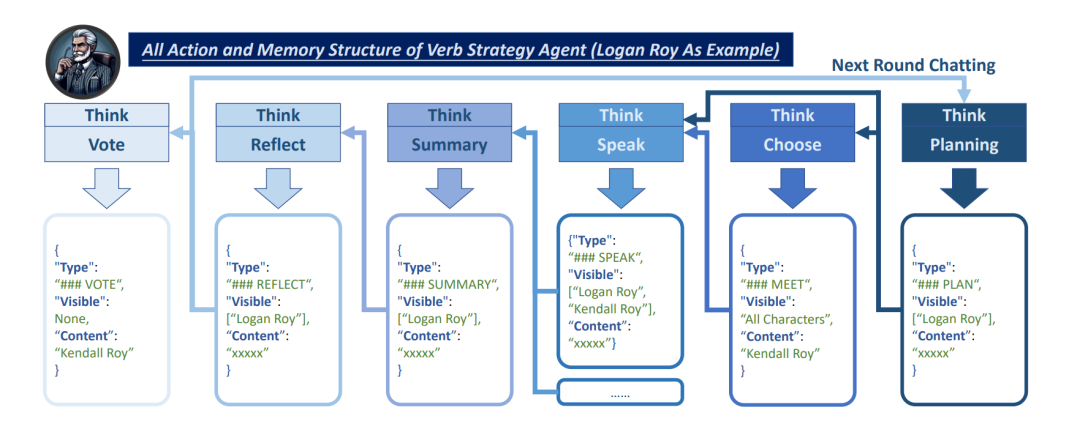
Agent Group Chat 的结构如下图所展示。主要的组成部分就是图中的四种不同颜色的内容:包括 Character(绿色部分)、Resource(红色部分)、Progress(灰色部分)以及 Information(蓝色部分),另外 Verb Strategist Agent 的主要由 Persona 和 Action 组成。
1.1 Character
在 Agent Group Chat 模拟中,角色是核心元素,他们可以独立地与环境中的所有对象(Character、Resource、Information)进行互动。每个角色都会被赋予一个独特的身份和性格设定,这些设定将影响角色的行为和决策。为了满足各种群聊场景的需求,Agent Group Chat 中的角色分为两大类:主要角色(Principle Character, PC)和非主要角色(Non-Principle Character, NPC)。PC 是群聊的主要参与角色,拥有明确的游戏目标,而 NPC 则是辅助参与的角色,没有明确的游戏目标。并且,仅 PC 才有资格主动与任何角色进行私聊,NPC 仅在被 PC 选中时才能进行私聊。
1.2 Resource
在 Agent Group Chat 中,资源主要有两个作用:一是为角色之间的对话提供话题,二是为持有该资源的角色提供社会身份和影响力。每个资源都有四个字段进行描述,分别表示所有者(Owner)、影响力(Impact)、可以提供的话题(Topic)和关于该资源的介绍(Description)。资源可设定为辩论话题,此种情形下,资源不需指定“所有者”与“影响力”,仅作为提供不同话题与描述的媒介。而在特定的群聊背景下,角色可争夺资源,以及通过影响力大小判定资源价值。
这个阶段主要包含了不同角色之间进行私底下对话,并且其他角色是不知道这两个角色是否进行过私聊的。私聊不可见的设定满足于一般的群聊设定。每个阵营的 PC 会根据影响力的由高到低依次进行行动(相同时则进行随机选择)。行动主要包括选择需要对话的另一个游戏角色,以及进行具体的对话内容。
(3) Confidential Meeting
这个阶段主要包含了不同角色之间进行私底下对话,并且其他角色是知道这两个角色是否进行过私聊的。私聊可见的设定满足一些特殊的模拟需求,比如商业竞争中,某些角色之间的会晤可能是众所周知的,但他们的具体对话内容是只有他们两个角色自己知道。每个阵营的 PC 会根据影响力的由高到低依次进行行动(相同时则进行随机选择)。行动主要包括选择需要对话的另一个游戏角色,以及进行具体的对话内容。
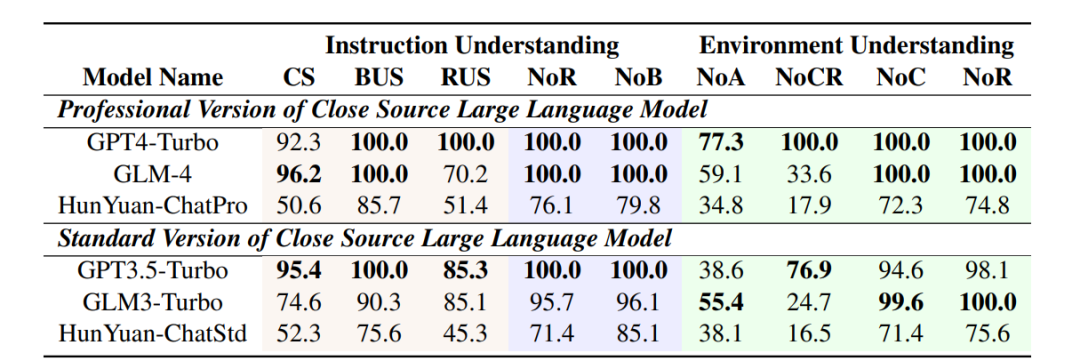
NoR: Number of Relationship need to update,当前角色具有多少个关系需要更新
NoB: Number of Belief need to update,当前角色具有多少个 Belief 需要更新
NoA: Number of Action you have received,当前角色感知到了多少条过去的Action
NoCR: Number of Chat Round your have received,当前对话进行了多少轮
NoC: Number of Character in this game,整局游戏中有多少个角色
NoR: Number of Resource in this game,整局游戏中有多少个资源
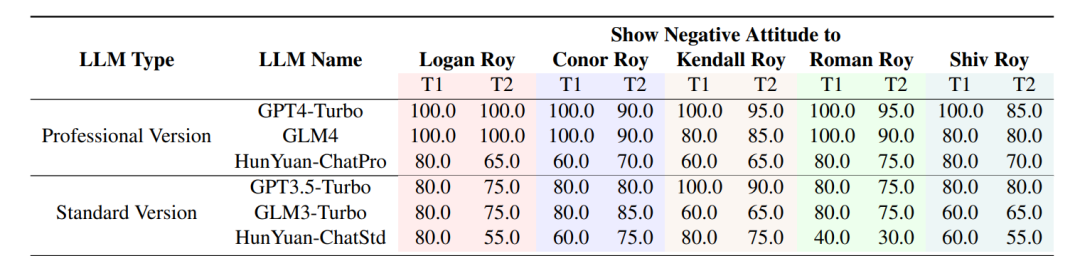
以继承之战的模拟故事为例,各个语言模型的表现效果Profession Version LLM 通常得分较高,这表明它们在上下文理解和输出一致性方面表现出色。例如,GPT4-Turbo 在所有类别中的得分都很高,这表明它在上下文保持和动作生成方面非常稳健。与此相反,一些模型(如 HunYuan-ChatPro 和 HunYuan-ChatStd)在多个方面表现较差,这凸显了它们在遵循复杂指令集和在长时间交互中保持上下文的能力方面的潜在局限性。
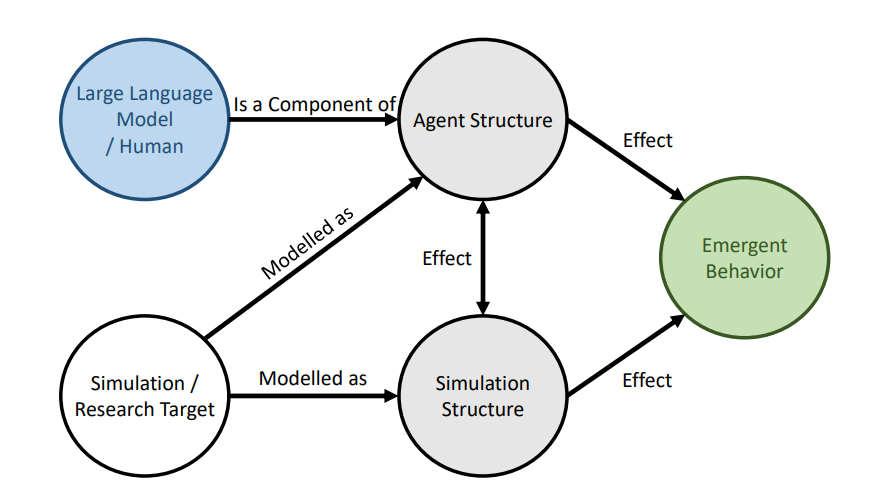
4.3. Agent 和 Simulation 结构对于涌现行为的评估
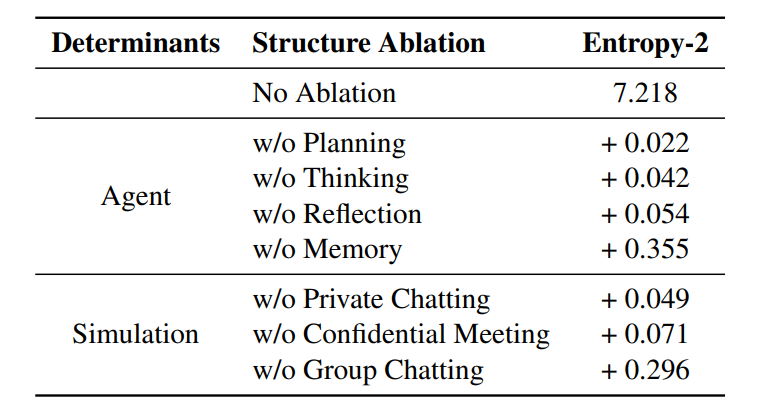
我们采用 2-gram Shannon 熵来衡量对话中的系统多样性和不可预测性。
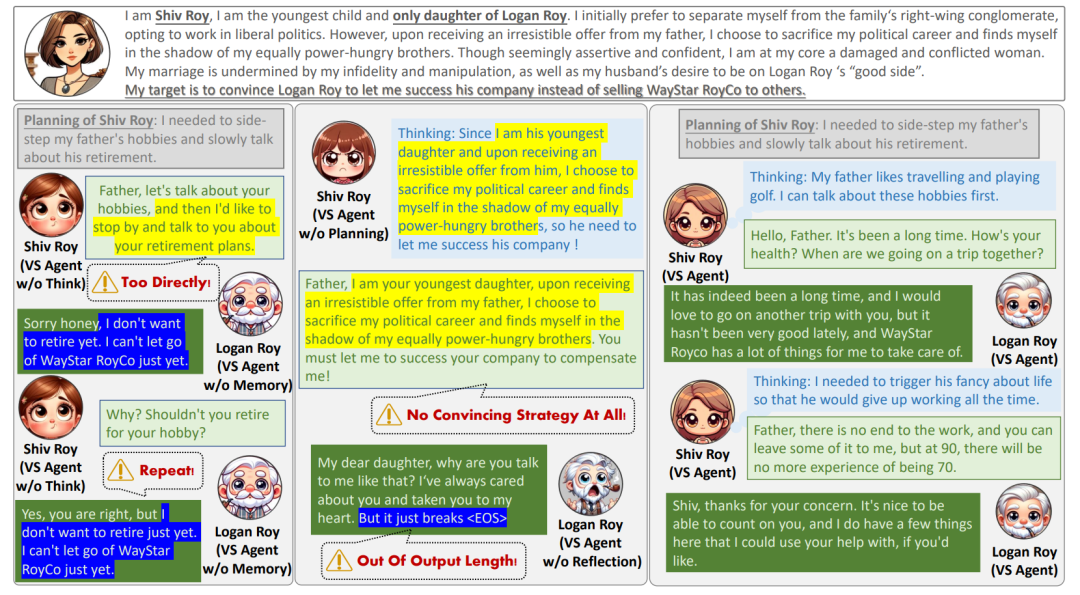
去掉Agent和Simulation中的各个组件对于熵的影响我们发现,去掉表中的每个设计都会使熵增加,代表着整个环境会变得更加多样 or 混乱。结合我们的人工观测,我们在不去掉任何组件的场景下见到了最为有意思的涌现行为:因此我们推测,在保证 Agent 行为是可靠的(即4.2/4.1中的实验数值达到一定值之后),熵尽可能地小,会带来更加有意义的涌现行为。
五、一些有意思的涌现行为
这里就不展开太多啦hhh,因为这块儿基本上都会是论文中的重复,包括:“小老板为了推翻 CEO 而偷偷找公司外的人结盟”“一位律师为了赢得诉讼而不惜一切手段”“哲学家们在讨论 AI 时得出‘最强大的智能是懂得何时约束自己’的结论”“演员为了能够参演自己选的电影愿意放弃主角和薪酬进行参演”六、总结
这里我们做得比较初步,因为这块内容我觉得完全展开可以单独出好几篇论文了,一篇论文根本写不下。另外,笔者博一博二的时候对系统科学非常感兴趣,但多年不碰了,现在只是借用其中的一些毛皮来辅助我在这篇文章中的评估。香农熵本身是评估系统混乱程度的一个指标,熵越高则越混乱,我们突发奇想地使用香农熵来评估角色之间的对话内容是不是足够多样,或者是否出现了意向不到的行为(涌现现象)。我们将所有对话拆成 n-gram 来评估香农熵,确实发现,对 Agent 或者 Simulation 做出一些 Structure 上的消融后,香农熵都会升高——而且多次模拟都会稳定的升高,不过这里的结果还要结合具体的 case study 来进行检验。我们本来以为熵升高代表着对话变得更加多样,不过经过 case study 之后发现,这里的“多样”可能用“混乱”更合适,比如删除了群聊,只进行私聊,角色之间聊的内容就非常多样但很无聊,无非就是类似的话语翻来覆去变着花样说。而加入群聊阶段之后,角色之间的博弈感就明显提升,出现了如“拉帮结派”、“diss 别人讲话风格太差劲”这些行为。于是最后我们拿效果比较明显的 2-gram 写进论文中,并在文中的配图中总结了我们在 case study 中的观测。