
第一篇文章没有漂亮的开场白,想到哪就写哪,只因发现一个特别有趣的东西而已。
众所周知,无论是学术界还是产业界,人工智能乃当下大热,而机器学习作为其中的重要分支,亦是热中之热,重中之重。
而在完整的机器学习过程(Pipeline)中(后续有空再分享pipeline中的各个关键环节),模型训练(model training)为关键步骤之一。在特定应用场景下,有了合适的模型,预测准确度(accuracy)才能有保证。
然而,合适的模型总会被两个问题所干扰,一个是过拟合(overfitting),一个是欠拟合(underfitting),尤其是过拟合。
接下来直接上图文干货,请跟着我的节奏来,可以看到如下效果
-
受监督的机器学习 (Supervised Learning) 中的回归 (Regression)和分类(Classification)模型。
-
因模型复杂度变化,如简单线性或复杂非线性,而导致模型 (Model)的变化。
-
因数据的变化,如增加正常数据或极端数据,而导致模型 (Model)的变化。
展示效果图包含如下场景:
| 模型复杂度 |
回归模型 | 分类模型 |
增加正常数据 | 增加极端数据 |
| 简单线性 |
1.1 |
2.1 |
/ |
/ |
|
一元二次/ 二元二次 |
1.2 |
2.2 | / | Try on 1.2 2.2 |
|
一元三次/ 二元三次 |
1.3 | 2.3 | / | / |
|
一元四次/ 二元四次 |
1.4 | 2.4 | / | / |
|
一元五次/ 二元五次 |
1.5 | 2.5 | Try on 1.5, 2.5 | / |
|
一元六次/ 二元六次 |
1.6 | 2.6 | / | / |
-
先看回归 (Regression)模型因数据和模型复杂度的变化会如何变化。
初始化图如下,即回归问题(联想到实际应用比如房价的预测,可以将x假设为房屋的面积,y为房屋的价格,当然实际问题并没那么简单,这里简化问题,便于理解),所有实际数据点和理想的模型 (一元二次函数)的Plot如下。
其中蓝色为面积X,所对应房屋价格y。
红色虚线(模型曲线)即回归模型(Regression Model),回归问题的关键就是找该回归模型,并尽最大可能使得该曲线fit data,进而可以对新的数据X进行价格y的预测。
-
初始化Regression模型


1.1 简单线性模型fit to data,很生硬的一条直线,与理想曲线随着x的变大,差别越来越大。Underfitting!

1.2 一元二次模型fit to data,蓝色曲线似乎完美匹配红色虚线理想模型。Good Fit!

1.3 一元三次模型fit to data,变化不大,但蓝色曲线后半段有抬头迹象。Good Fit!
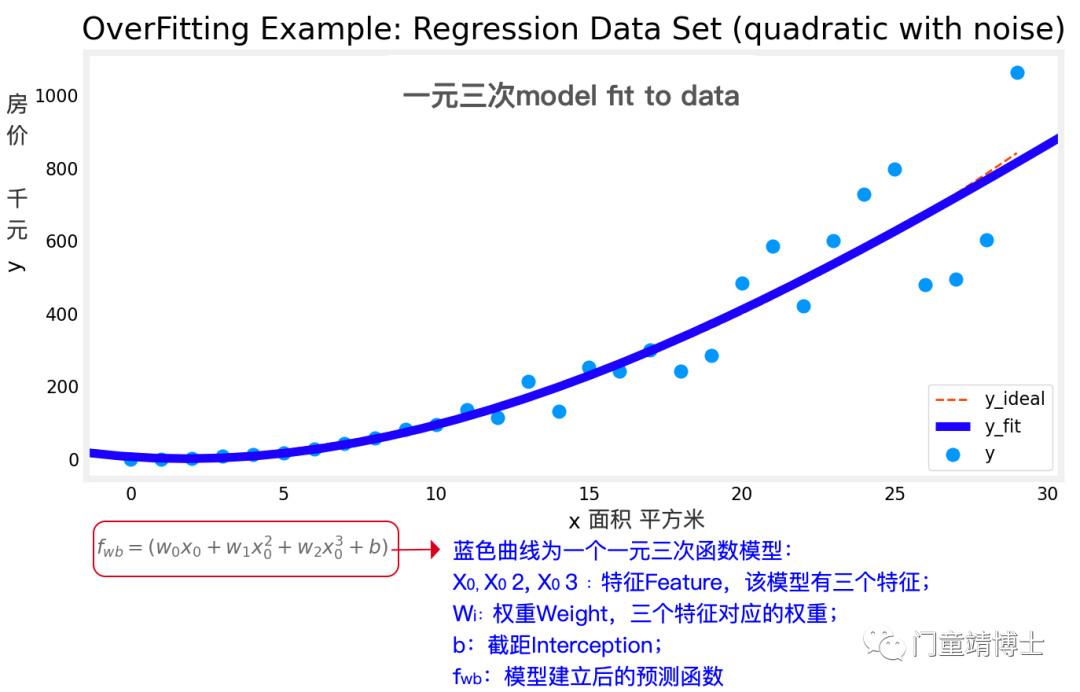
1.4 一元四次模型fit to data,依旧变化不大。Good Fit!
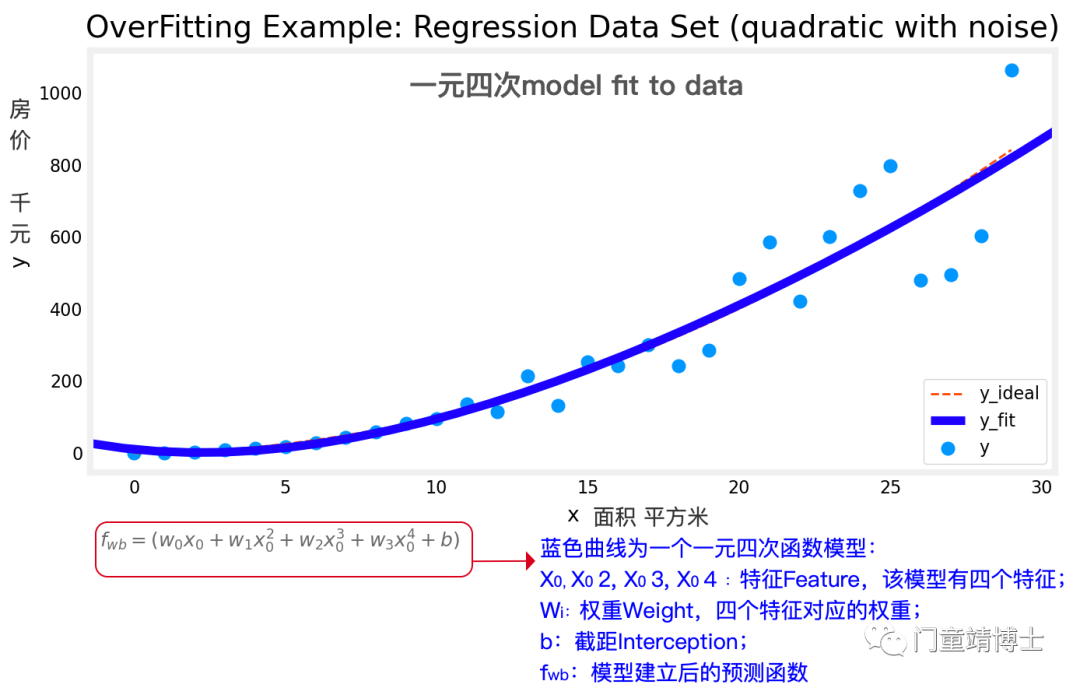
1.5 一元五次模型fit to data,模型曲线无法继续矜持,开始扭秧歌了。Overfitting!
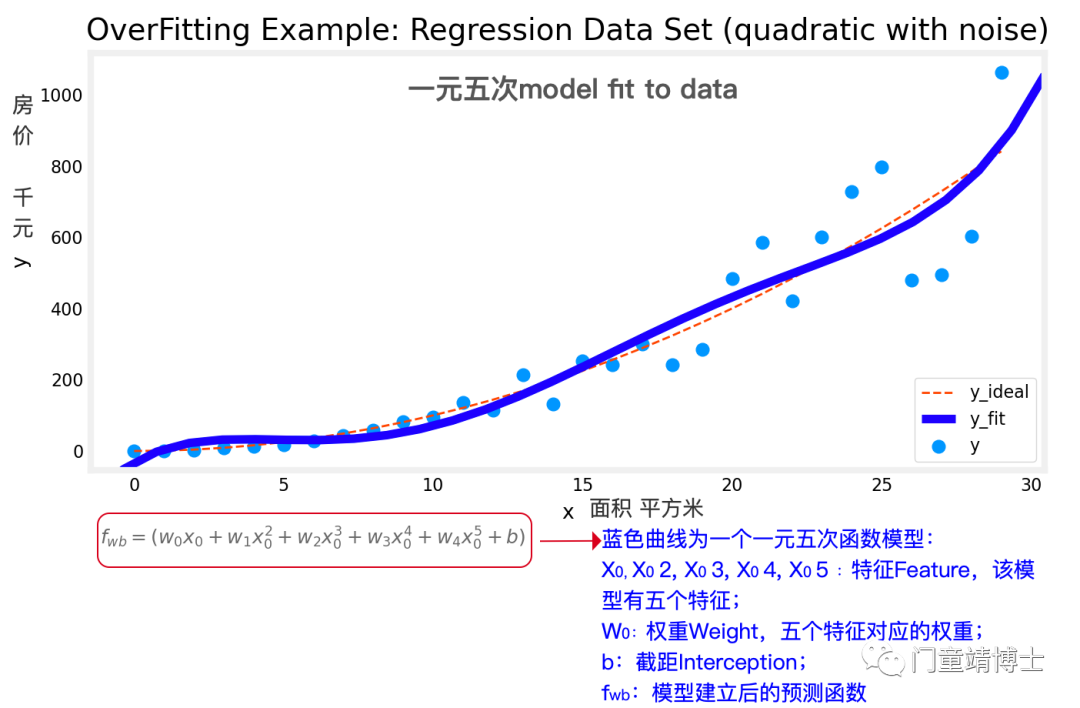
1.6 一元六次模型fit to data,随着多项、次方的增加,模型曲线扭秧歌的幅度将会越来越大,模型对真实数据的拟合度降低。Overfitting!

-
我们再来看看分类 (Classification)问题。
2. 初始化Classification模型
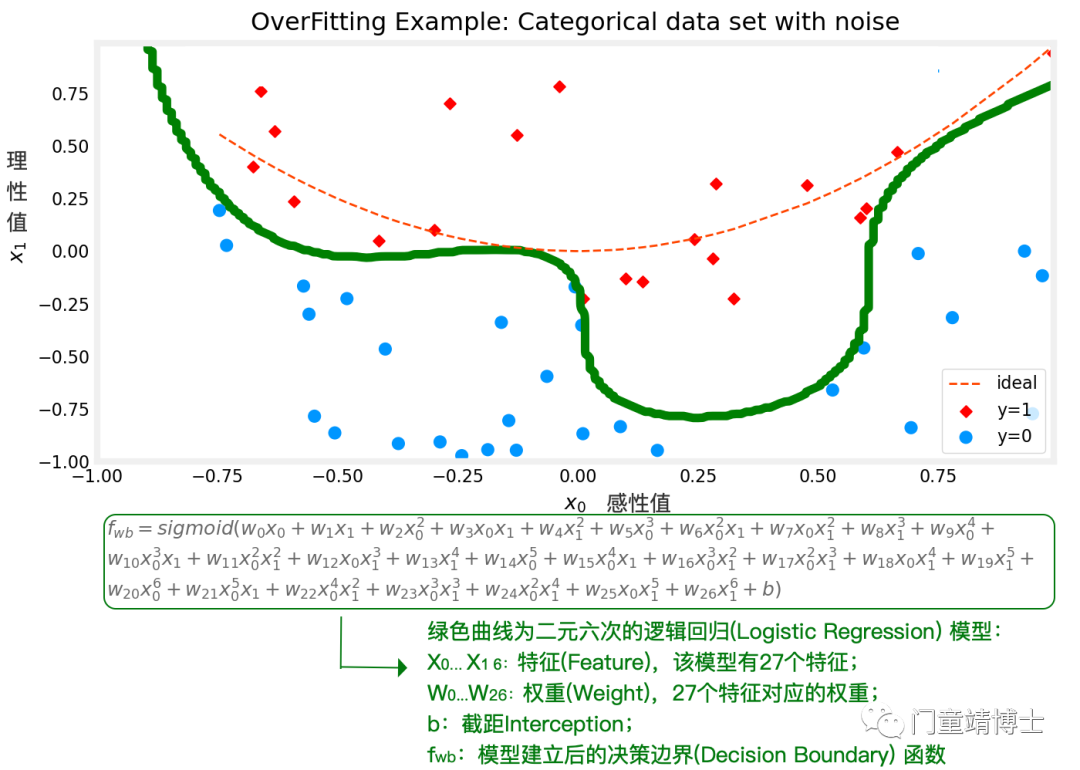
该模型为典型的基于逻辑回归函数,用于分类的模型,实际应用比如基于西瓜的颜色(X0)和纹理(X1)判断该西瓜熟不熟,基于香蕉的颜色程度(X0 绿<->黄)和柔软度(X1软<->硬)判断香蕉熟不熟等等。
为了使该分类模型便于理解,以基于感性值和理性值,从而判断大脑是否能做正确决策,X0代表感性值,X1代表理性值。(这个例子纯粹是为了便于理解,而非存在于科学或实际应用当中,特此说明一下。)
其中红色代表正确决策点,而蓝色代表错误决策点。
红色虚线(模型曲线)即决策边界(Decision Boundary),分类问题的关键就是找该决策边界,并尽最大可能使得该曲线划分出红色与蓝色的数据区域,进而可以对新的数据(X0, X1)进行决策预测(Red or Blue)。
回到初始化Classification模型如下:

2.1 简单逻辑回归模型fit to data,似乎更像一条直线,与理想曲线差别很大。Underfitting!

2.2 二元二次多项式函数逻辑回归模型fit to data,与数据点匹配的看似不错。Good Fit!

2.3 二元三次多项式函数逻辑回归模型fit to data,这个决策曲线已经比较复杂了,为了匹配所有训练数据,边界划分过于复杂,训练后的模型一旦泛化(Model Generalization)至其他测试数据,将导致判断准确度下降。Overfitting!

2.4 二元四次多项式函数逻辑回归模型fit to data,这个决策曲线已经相当复杂了,Overfitting!

2.5 二元五次多项式函数逻辑回归模型fit to data,这个决策曲线已经非常复杂了,Overfitting!
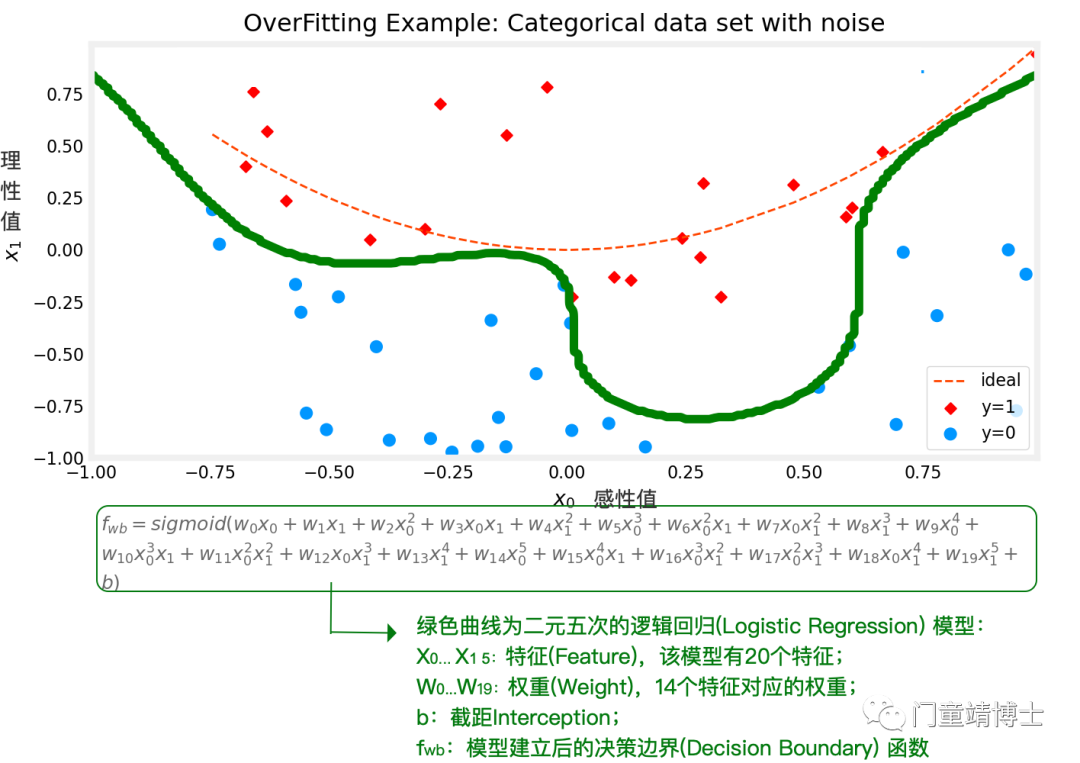
2.5 二元六次多项式函数逻辑回归模型fit to data,这个决策曲线同上,已经非常复杂,Overfitting!
以上,通过图形我们认识了Underfitting, Good fit and Overfitting。
大致总结一下:
Underfitting:通常因模型过于简单,无法拟合训练数据,模型无法很准确地基于训练数据进行预测(Cost Function过高),亦不能准确预测实际的测试数据。
Good fit:选择了适合的模型,很好地拟合了训练数据,模型高准确率地基于训练数据进行预测(或Cost Function全局最小),因此,可以将模型泛化预测实际的测试数据。
Overfitting:通常因模型过于复杂,很好甚至完美地拟合训练数据,模型极高准确率地基于训练数据进行预测(或Cost Function全局最小),然而,训练后的“完美”模型一旦基于实际测试数据进行预测,准确率大大降低!
-
那么训练数据的增加又会对模型产生何种影响呢,积极还是消极?
结论先行吧:
倘若模型Underfitting,那么建议是在模型端着手,而非从数据端来改进。
如果模型Goodfit:
若在Goodfit的模型下增加更多正常数据,对于提升模型的训练准确率和测试准确率都会更进一步,这也是为何常听到 “数据量越大,预测越准确。”
若在Goodfit的模型下增加更多异常数据,比如越界(outlie)极端数据,那么对于模型的预测准确率会产生消极影响,这需要Data Exploration and Data pre-processing来处理。
那么如果模型Overfitting:
增加更多正常数据,同样遵循 “数据量越大,预测越准确。”,这可能需要大量的数据来对复杂模型进行训练,从而适当降低训练数据的预测准确率,提升测试数据的预测准确率。
通常来说,增加正常数据量只是方式之一,另外一种比较常见的手段就是采取Regularization,或者通俗地说就是降低所有特征的权重值(W0…Wn),在图形体现上就是把各种突出的地方拉平滑,就相当于更为简单的模型。
至于增加极端数据,无疑只会雪上加霜。
这篇文章就写到这,否则基本没有耐心看完了。
为了尊重原创,这里要Acknowledge一下Machine learning的大师 Andrew Ng,不同于2015年的Machine learning,该课程姿态更低,图文并茂,通俗易懂,令人印象深刻。
相关图形和数据来源于Coursera,Machine Learning Specialization中Course1 Week3 的Overfitting章节中Optional Lab,/notebooks/C1_W3_Lab08_Overfitting_Soln.ipynb。
有兴趣的同学可以学习:
https://www.coursera.org/specializations/machine-learning-introduction
原创文章,作者:门童靖博士,如若转载,请注明出处:https://www.agent-universe.cn/2022/07/12783.html