


实验目的:实践为例,以尽可能简单的方式,来说明基于训练数据集的模型创建、学习和验证。
-
问题定义
基于训练数据集,使用单变量线性模型来预测房价。
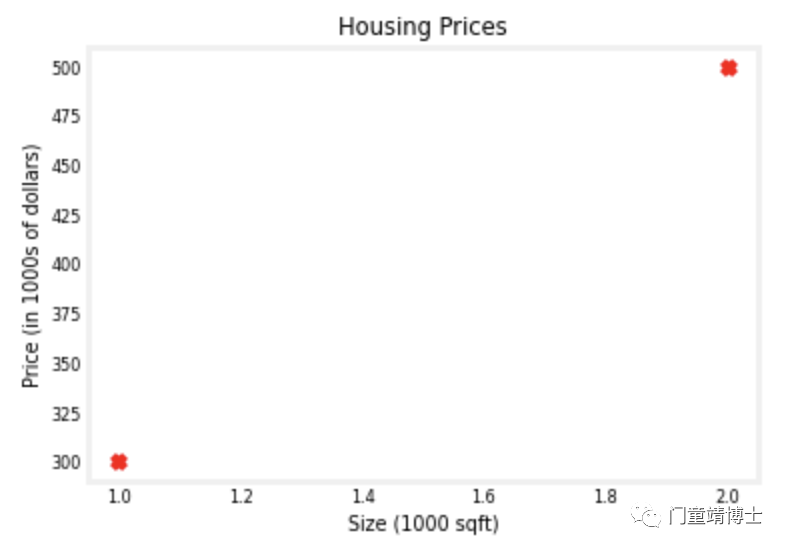
该实验室将使用一个只有两个数据点的简单数据集——一栋 1000 平方英尺 (sqft) 的房子售价 300,000 美元,一栋 2000 平方英尺的房子售价 500,000 美元。这两点将构成我们的数据或训练集。 在这个实验室中,尺寸单位是 1000 平方英尺,价格单位是 1000 美元。

-
主要工具
-
Numpy,用于各种科学计算操作的库;
-
Matplotlib,展示数据和模型曲线的库;
-
逻辑路径
-
数据集探索(Data Exploration);
-
加载数据;该例通过np.array创建数据集,如上图数据集表格;
-
查看数据样本数m,和特征数n;该例通过X.shape或len(X)来获取,m = 2,n = 1;
-
查看数据集中的任何数据X(i), y(i);该例通过 array读取X[i] y[i];
-
可视化数据集;该例通过plt.scatter可获得数据集视觉效果;
-
手动建立模型(Model Creation manually);
-
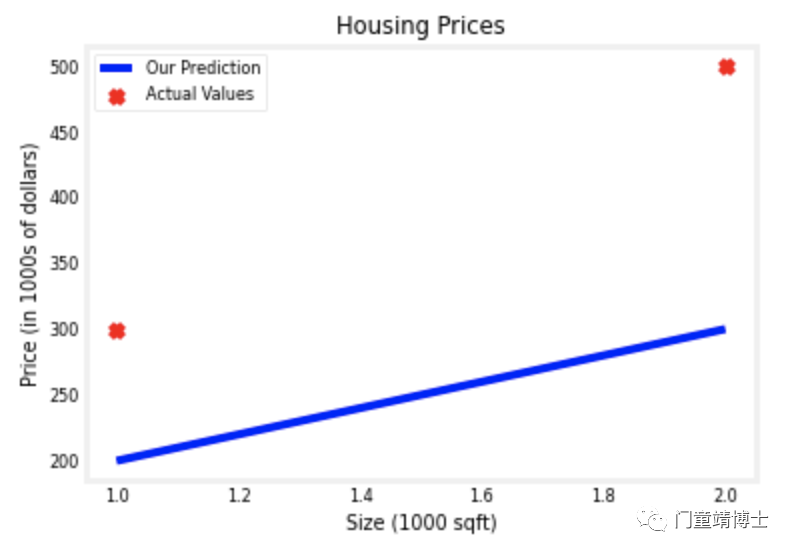
假设参数w = 100, b =100;
-
建立模型,f_wb = w*x + b; 即f_wb = 100*x + 100;
-
观察匹配度(Observation on Model fit to data);
-
可视化数据集和预测模型;该例通过plt.scatter可获得数据集视觉效果,通过plt.plot可获得预测模型视觉效果;可见预测模型(直线)与数据集基本不匹配,因此需要继续调整模型,即w和b的值。
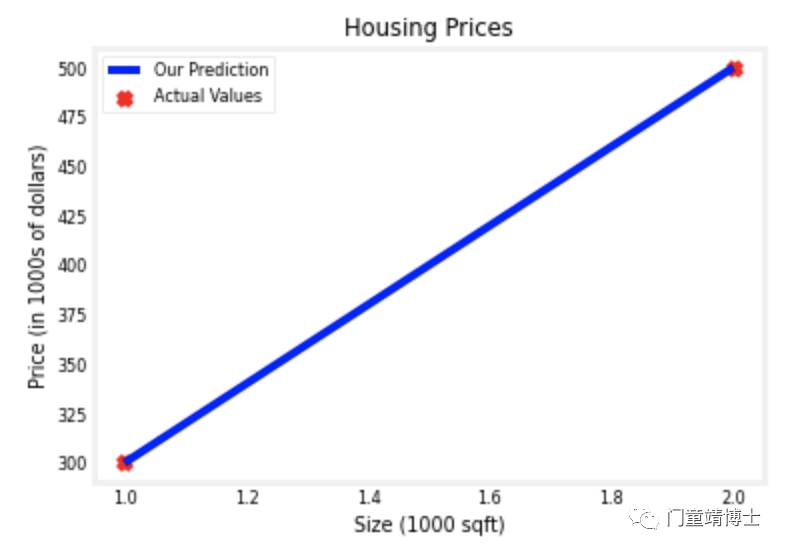
4. 手动调整参数 (Parameter tunning manually);
a. 将 w 和 b 的值分别调整为200 和 100;
b. 建立模型,f_wb = w*x + b; 即f_wb = 200*x + 100;
5. 再次手动建立模型并观察匹配度,直至调整后的模型比较完美地匹配数据,就算大功告成了!
-
脑图总结

-
实现代码
https://github.com/goldboy225/study_notes_on_machine_learning_specialization_by_Andrew-Ng/blob/main/Code%20Practice/C1_W1_Lab03_Model_Representation_Soln.ipynb
总结思考:
-
基于数学理论,即相对简单的线性函数;
-
以手动方式选择并“建模”(Modeling,即单变量X的f(x)=wx+b线性模型),“学习”(Learning,即尝试不同w和b的值),“验证”(Validating, 即通过函数图像视觉上确认模型和数据集的匹配度),完成一个最基本的机器学习过程(Machine Learning Pipeline),从而可以基于此模型对新的数据x,预测y;
-
具体实操上要进一步熟悉python开发环境, numpy和matplot库,以及python code的实现方式,比如通过np.array实现数据创建和加载,X.shape或len(X)获取数据集维度,plt.scatter可视化数据,plt.plot可视化模型,以及通过for loop创建模型函数等。
原创文章,作者:门童靖博士,如若转载,请注明出处:https://www.agent-universe.cn/2022/07/12776.html