
特别活动


我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。

论文
INDUS:适用于科学应用的有效和高效语言模型
 http://arxiv.org/abs/2405.10725v1
http://arxiv.org/abs/2405.10725v1观察性缩放规律与语言模型性能预测
 http://arxiv.org/abs/2405.10938v1
http://arxiv.org/abs/2405.10938v1轻量化注意力:面向硬件的可扩展注意力机制,适用于Transformer解码阶段
 http://arxiv.org/abs/2405.10480v1
http://arxiv.org/abs/2405.10480v1特征自适应和数据可扩展的上下文学习
 http://arxiv.org/abs/2405.10738v1
http://arxiv.org/abs/2405.10738v1语言模型可以利用跨任务上下文学习来处理数据稀缺的新任务
 http://arxiv.org/abs/2405.10548v1
http://arxiv.org/abs/2405.10548v1UniCL:一个用于大型时间序列模型的通用对比学习框架
 http://arxiv.org/abs/2405.10597v1
http://arxiv.org/abs/2405.10597v1Farfalle
 https://github.com/rashadphz/farfalle
https://github.com/rashadphz/farfalleVerba
 https://github.com/weaviate/Verba
https://github.com/weaviate/Verba
MarkLLM
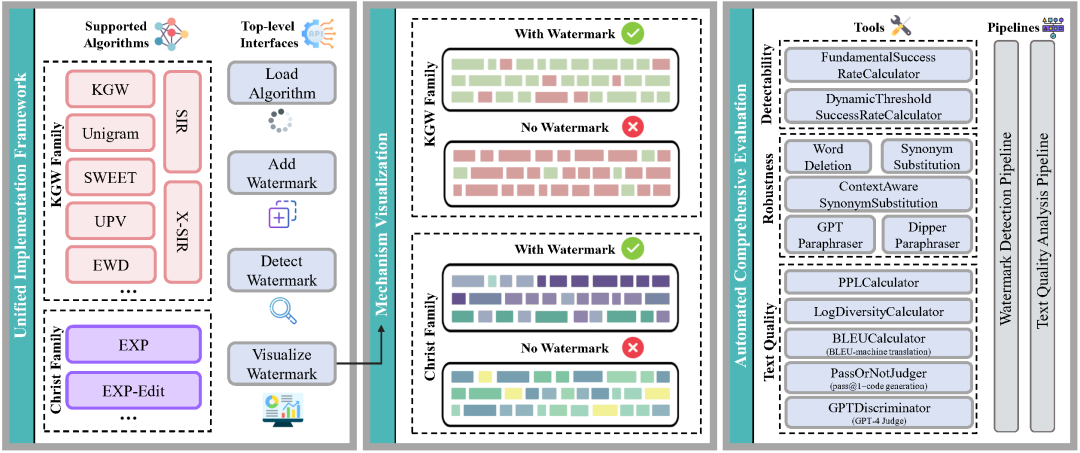 https://github.com/THU-BPM/MarkLLM
https://github.com/THU-BPM/MarkLLM原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15280.html