
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!

论文
大语言模型时代的索赔验证:A Survey
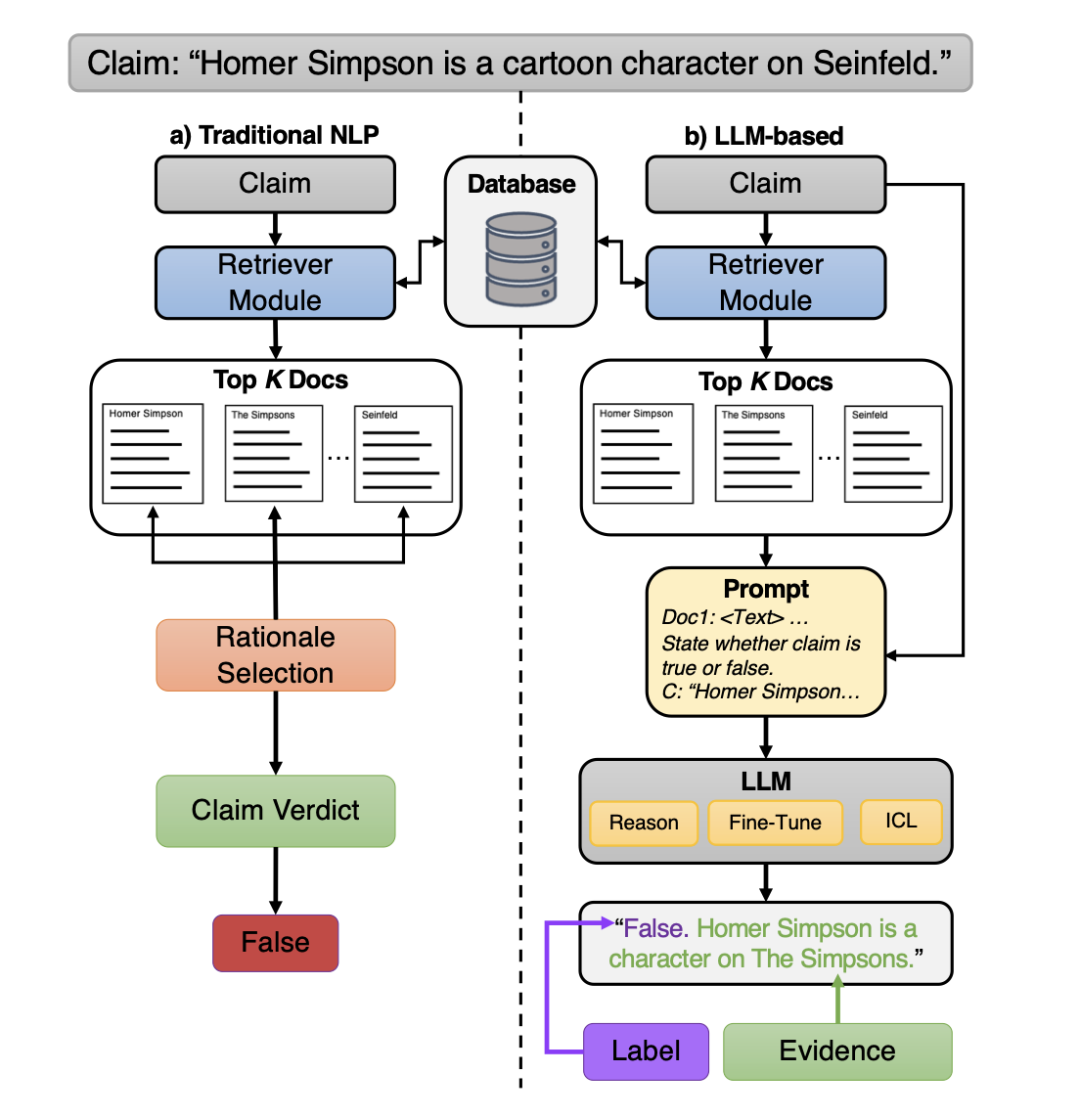 http://arxiv.org/abs/2408.14317v1
http://arxiv.org/abs/2408.14317v1专注的大语言模型是稳定的多次学习者
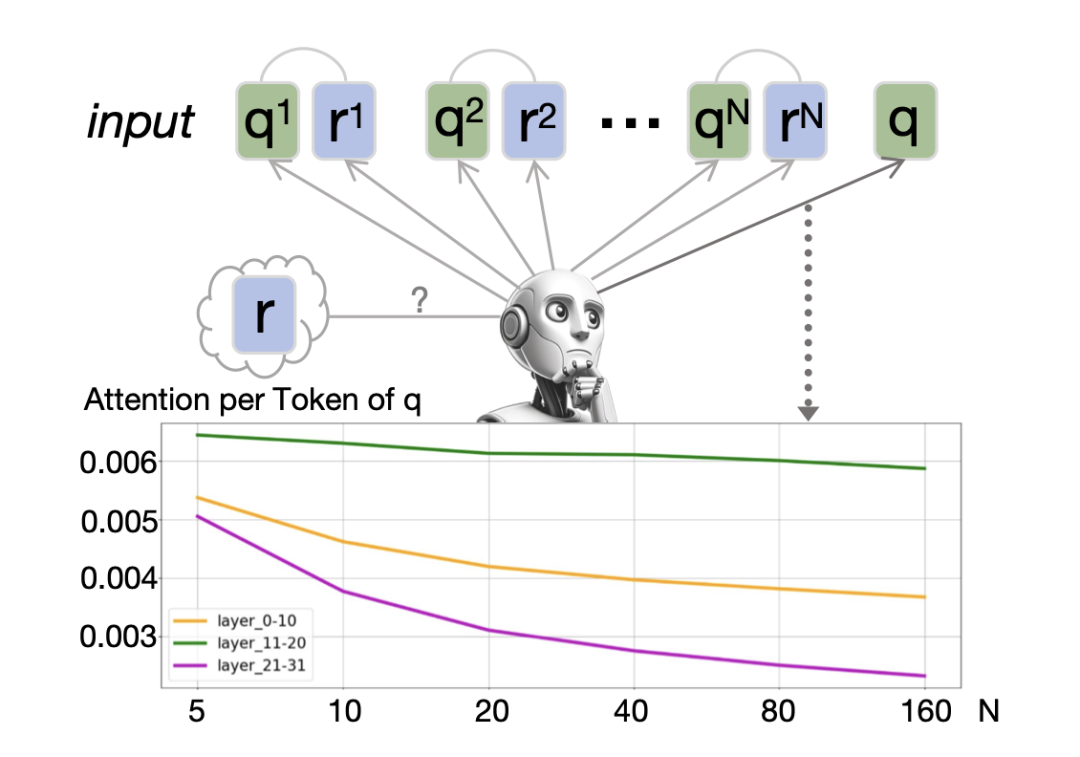 http://arxiv.org/abs/2408.13987v1
http://arxiv.org/abs/2408.13987v1DHP Benchmark: LLMs是否是良好的自然语言生成评估器?
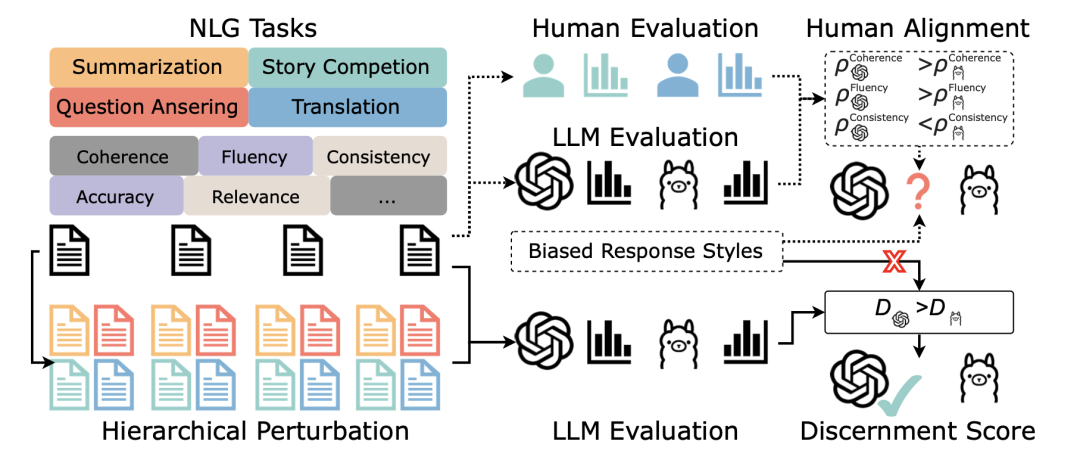 http://arxiv.org/abs/2408.13704v1
http://arxiv.org/abs/2408.13704v1CodeRefine: 用于增强研究论文LLM生成代码实现的流水线
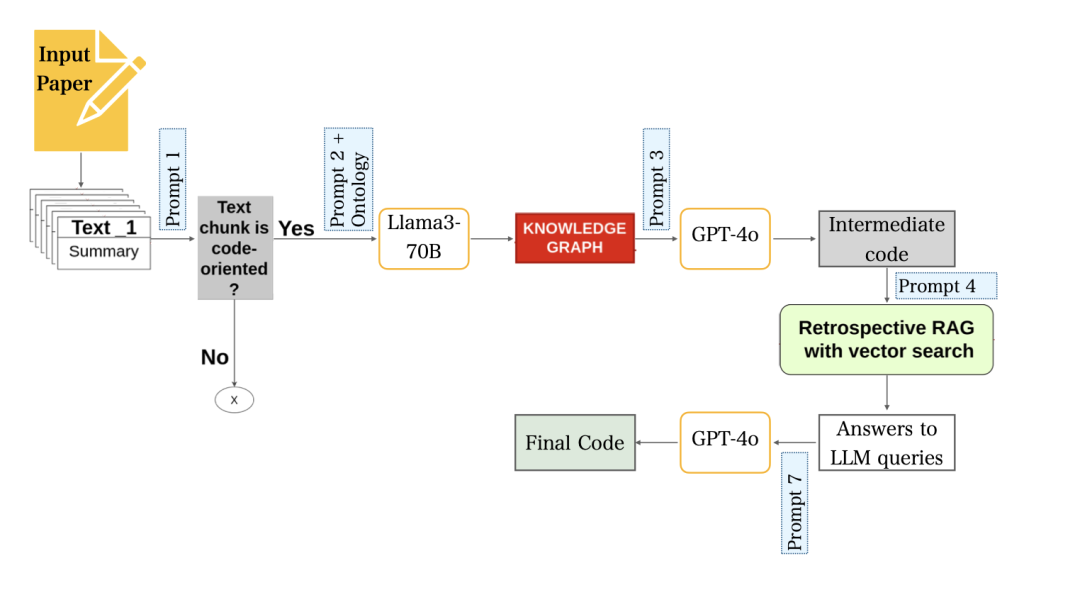 http://arxiv.org/abs/2408.13366v1
http://arxiv.org/abs/2408.13366v1Power Scheduler:一个与批量大小和 Token 数量无关的学习速率调度器
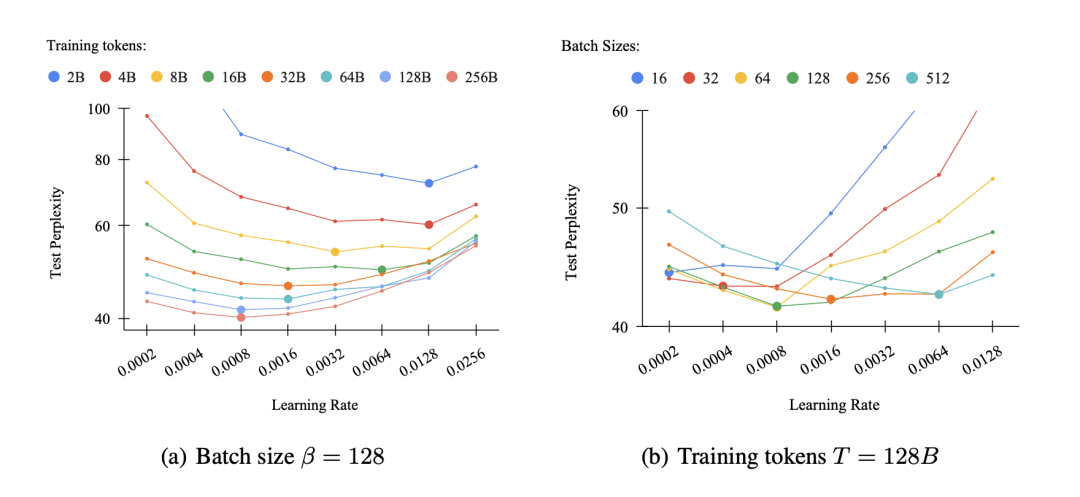
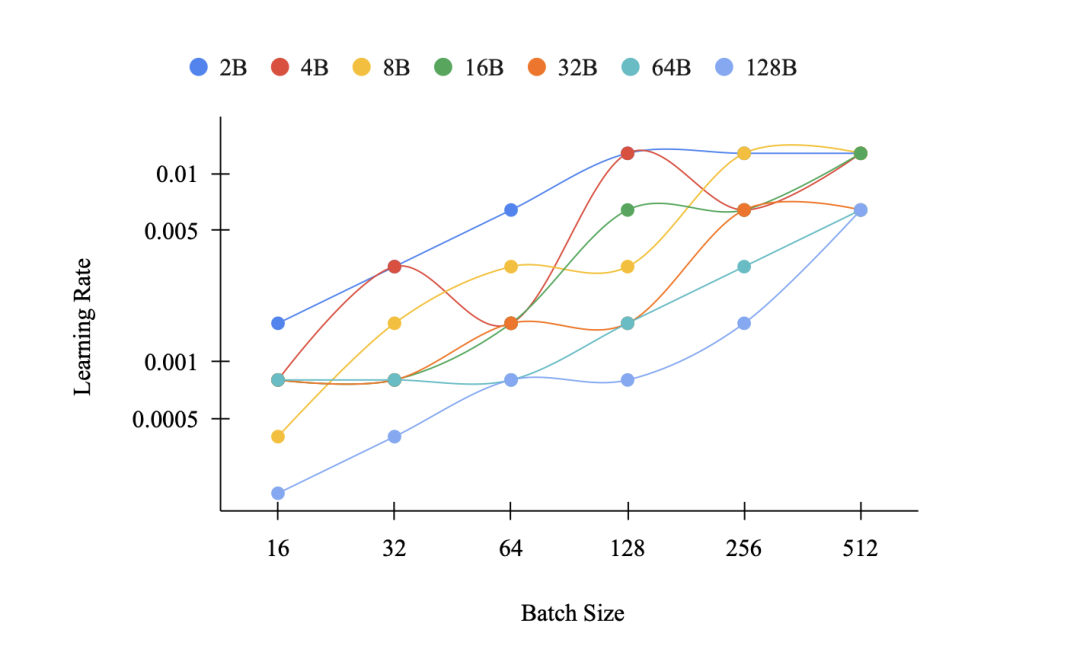 http://arxiv.org/abs/2408.13359v1
http://arxiv.org/abs/2408.13359v1SWE-bench-java:Java的GitHub问题解决基准测试
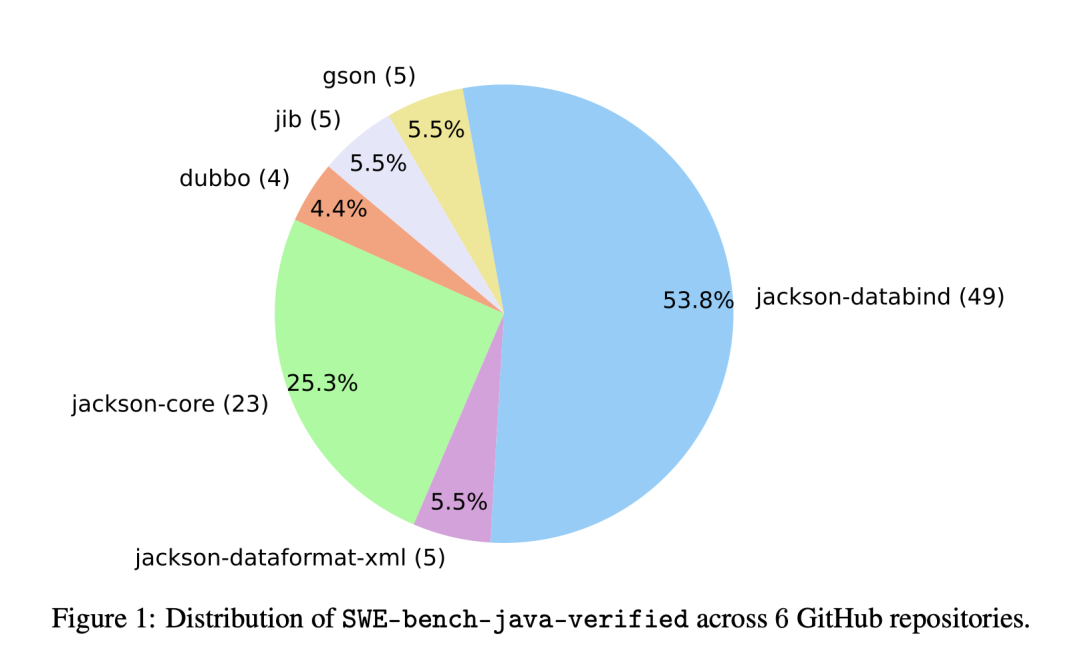 http://arxiv.org/abs/2408.14354v1
http://arxiv.org/abs/2408.14354v1用于音乐的基础模型: A Survey
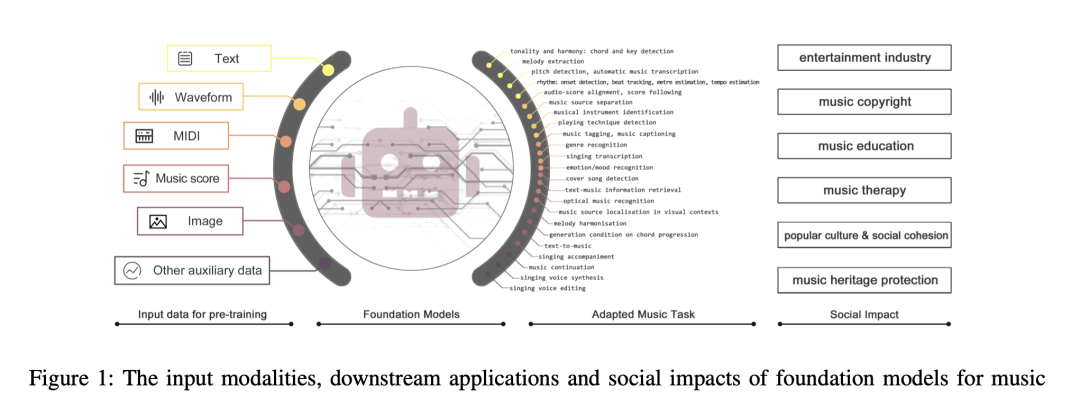
 http://arxiv.org/abs/2408.14340v1
http://arxiv.org/abs/2408.14340v1大语言模型中下一个token预测的法则
 http://arxiv.org/abs/2408.13442v1
http://arxiv.org/abs/2408.13442v1LitServe
 https://github.com/Lightning-AI/LitServe
https://github.com/Lightning-AI/LitServeQuestionImprover
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/08/13342.html
