
欢迎观看大模型日报,如需进入大模型日报群和空间站请直接扫码。社群内除日报外还会第一时间分享大模型活动。


论文
中文迷你 LLM:预训练一个以中文为中心的大语言模型
 http://arxiv.org/abs/2404.04167v1
http://arxiv.org/abs/2404.04167v1搜索流 (SoS):学习在语言中搜索
 http://arxiv.org/abs/2404.03683v1
http://arxiv.org/abs/2404.03683v1没有指数数据级别,就没有“zero-shot”:预训练概念频率决定了多模态模型的性能
 http://arxiv.org/abs/2404.04125v1
http://arxiv.org/abs/2404.04125v1从设计上可验证化:对齐语言模型使其引用预训练数据
 http://arxiv.org/abs/2404.03862v1
http://arxiv.org/abs/2404.03862v1FFN-SkipLLM:自回归解码中的隐藏宝石与自适应前馈跳跃
 http://arxiv.org/abs/2404.03865v1
http://arxiv.org/abs/2404.03865v1Octopus-v2
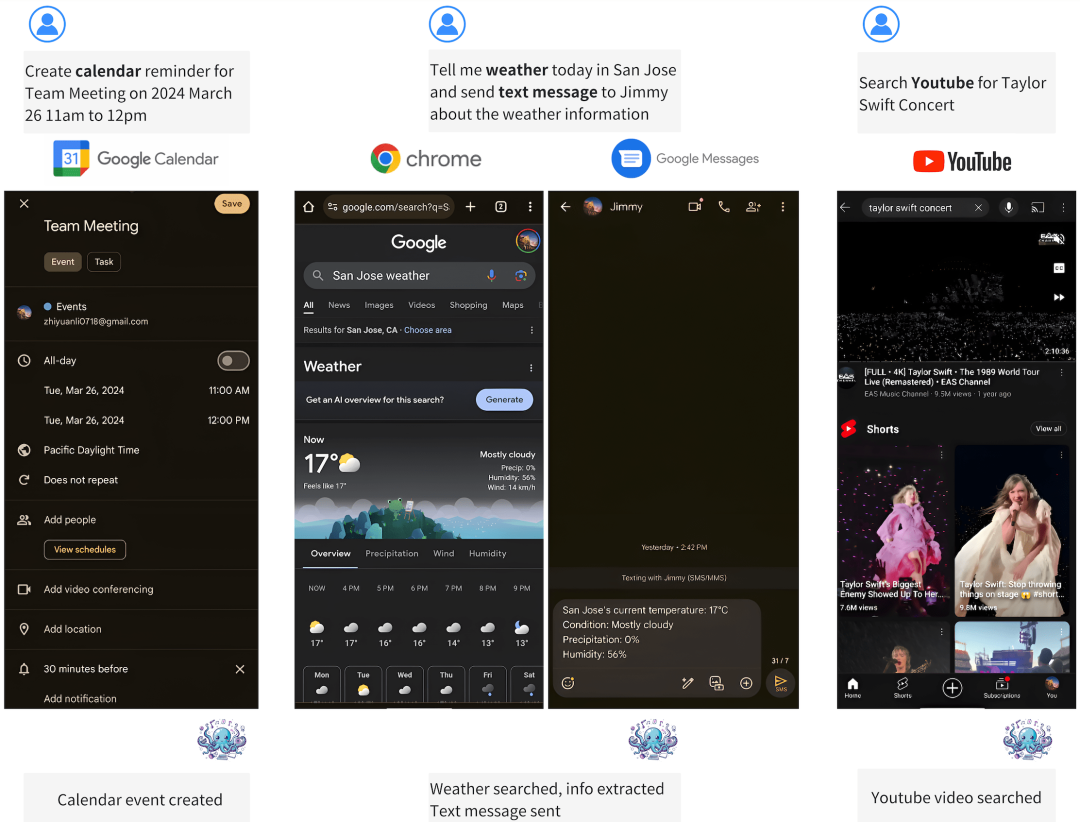 https://huggingface.co/NexaAIDev/Octopus-v2
https://huggingface.co/NexaAIDev/Octopus-v2Instantstyle
 https://instantstyle.github.io
https://instantstyle.github.ioXVERSE-MoE-A4.2B

大模型日报16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/16308.html