
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
数据,到处都是数据:预训练数据集构建指南
 http://arxiv.org/abs/2407.06380v1
http://arxiv.org/abs/2407.06380v1熵定律:数据压缩和LLM性能背后的故事
 http://arxiv.org/abs/2407.06645v1
http://arxiv.org/abs/2407.06645v1B’MOJO:混合状态空间模型具有 eidetic 和 fading 记忆
 http://arxiv.org/abs/2407.06324v1
http://arxiv.org/abs/2407.06324v1上下文学习中的模式匹配的关键机制:Induction Heads
 http://arxiv.org/abs/2407.07011v1
http://arxiv.org/abs/2407.07011v1aints-Undo
 https://github.com/lllyasviel/Paints-UNDO
https://github.com/lllyasviel/Paints-UNDO
KVQuant
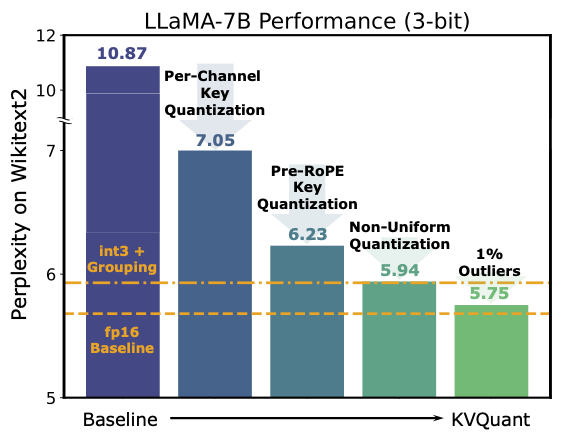 https://github.com/SqueezeAILab/KVQuant
https://github.com/SqueezeAILab/KVQuant原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/07/14198.html