
欢迎观看大模型日报,如需进入大模型日报群和空间站请直接扫码。社群内除日报外还会第一时间分享大模型活动。

论文
AutoWebGLM:基于大型语言模型的Web导航智能体的自举和强化
在Mamba中定位和编辑事实关联
在神经压缩文本上训练大语言模型
在大语言模型中的演绎、归纳和产生式学习:一个不完整的循环
代码编辑基准:评估大型语言模型的代码编辑能力
Anthropic-cookbook
VAR

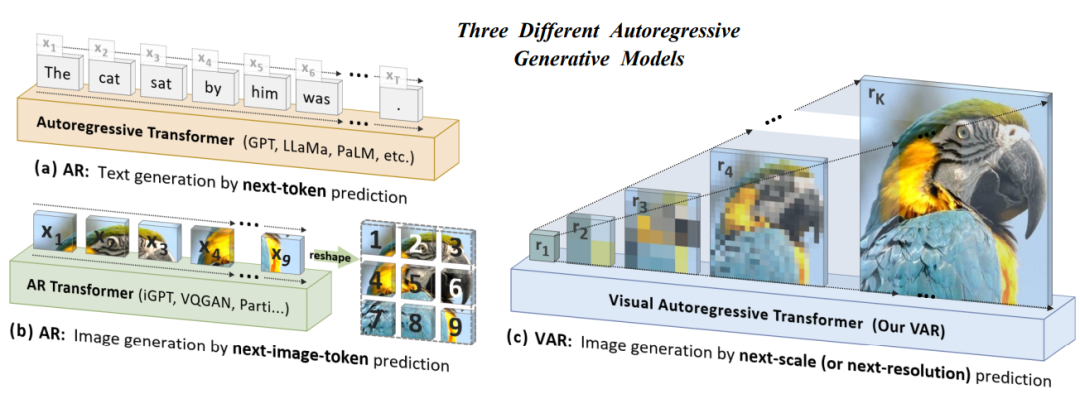 https://github.com/FoundationVision/VAR
https://github.com/FoundationVision/VAR学习
图解大模型计算加速系列:Flash Attention V2,从原理到并行计算
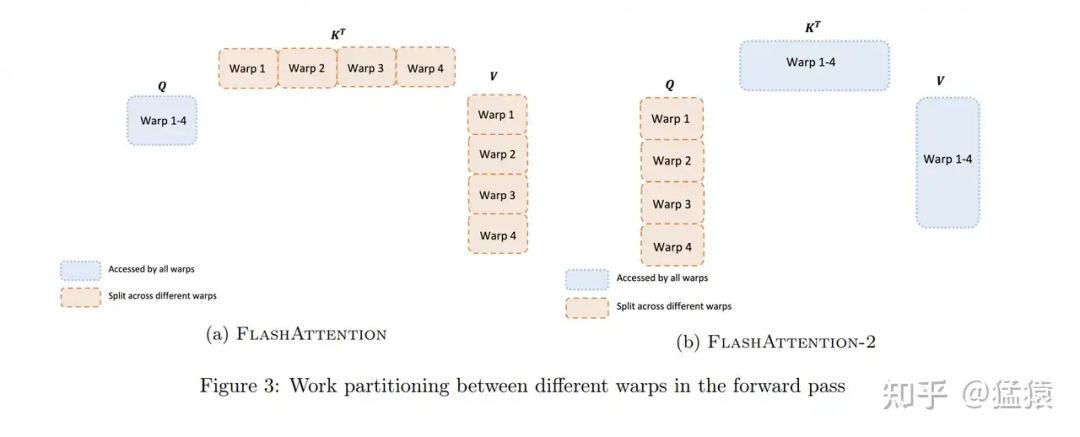 https://zhuanlan.zhihu.com/p/691067658
https://zhuanlan.zhihu.com/p/691067658深入理解 Megatron-LM(6)流水线刷新机制
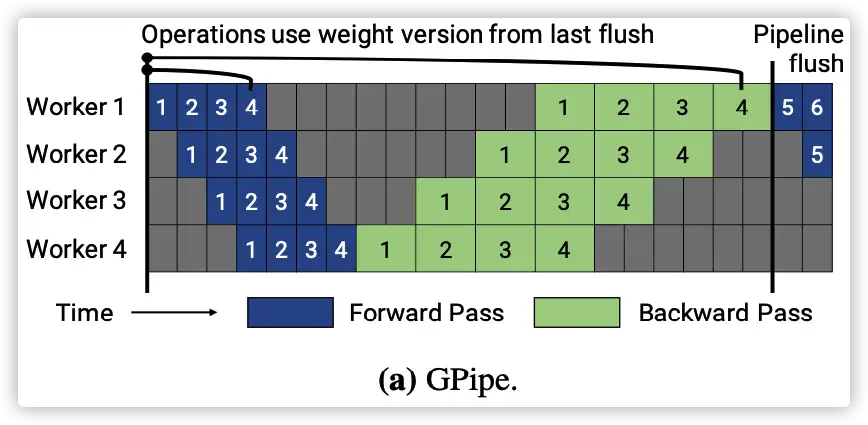 https://zhuanlan.zhihu.com/p/651341660
https://zhuanlan.zhihu.com/p/651341660如何降低 AI 工程成本?蚂蚁从训练到推理的全栈实践
 https://zhuanlan.zhihu.com/p/689775888
https://zhuanlan.zhihu.com/p/689775888Megatron-LM 中 Context Parallel 的工作原理是什么?
如何判断候选人有没有千卡GPU集群的训练经验?

大模型日报16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/16337.html
