
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
MAP-Neo:高效能透明的双语大语言模型系列
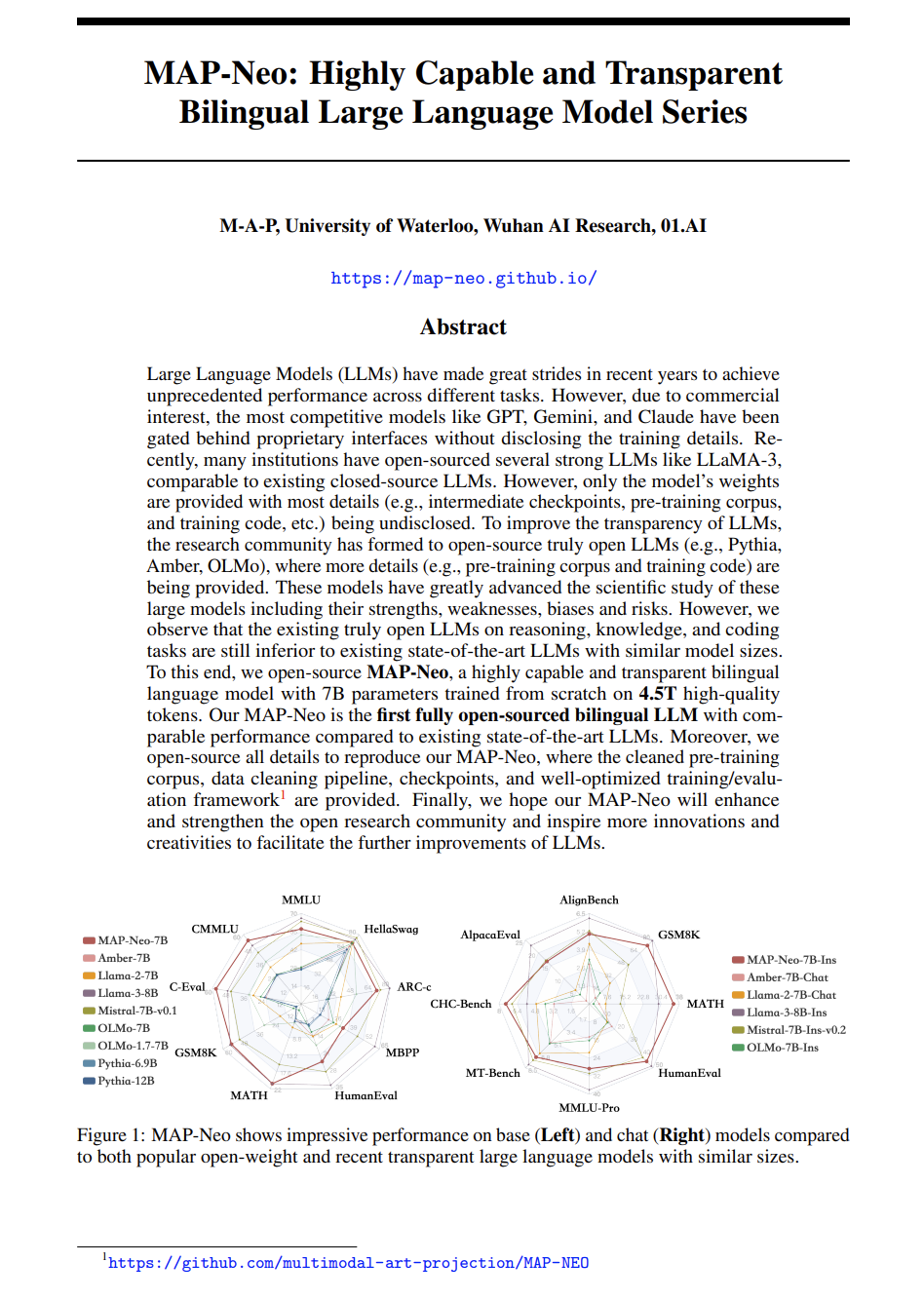 http://arxiv.org/abs/2405.19327v1
http://arxiv.org/abs/2405.19327v1弱到强搜索:通过在小语言模型上搜索来对齐大语言模型
 http://arxiv.org/abs/2405.19262v1
http://arxiv.org/abs/2405.19262v1在算数上预训练的大语言模型能预测人类风险和时间选择
 http://arxiv.org/abs/2405.19313v1
http://arxiv.org/abs/2405.19313v1OMPO:一个统一的框架,用于处理智能体在政策和动态变化下的强化学习
 http://arxiv.org/abs/2405.19080v1
http://arxiv.org/abs/2405.19080v1通过猜测解码实现更快的级联推测
 http://arxiv.org/abs/2405.19261v1
http://arxiv.org/abs/2405.19261v1再谈FP8:减少精度对LLM训练稳定性的影响量化
 http://arxiv.org/abs/2405.18710v1
http://arxiv.org/abs/2405.18710v1无调谐的扩散模型与直接噪声优化的对齐
 http://arxiv.org/abs/2405.18881v1
http://arxiv.org/abs/2405.18881v1FlashRAG
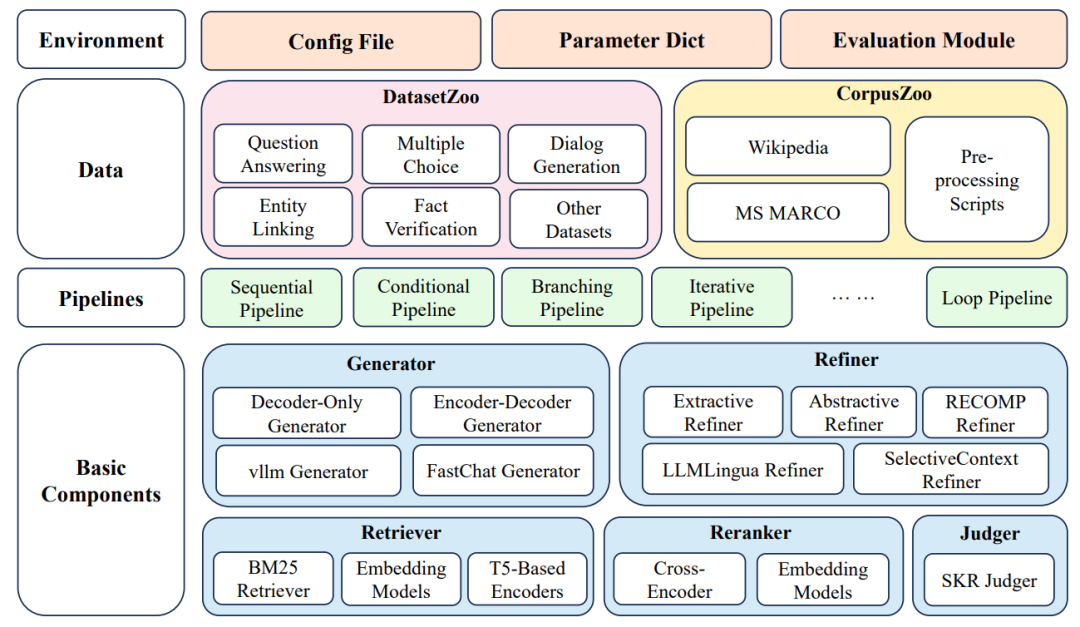 https://github.com/RUC-NLPIR/FlashRAG
https://github.com/RUC-NLPIR/FlashRAGOcular AI
 https://github.com/OcularEngineering/ocular
https://github.com/OcularEngineering/ocular
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15004.html