
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


学习
长上下文嵌入模型中的后期分块
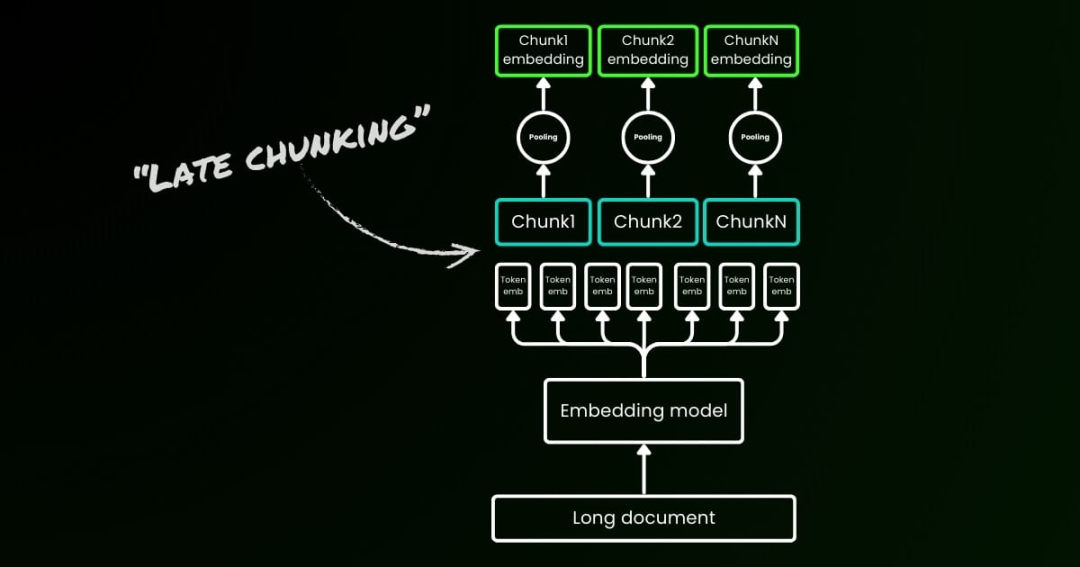 https://jina.ai/news/late-chunking-in-long-context-embedding-models/?nocache=1
https://jina.ai/news/late-chunking-in-long-context-embedding-models/?nocache=1我们如何构建 Townie——一款生成全栈应用的应用程序
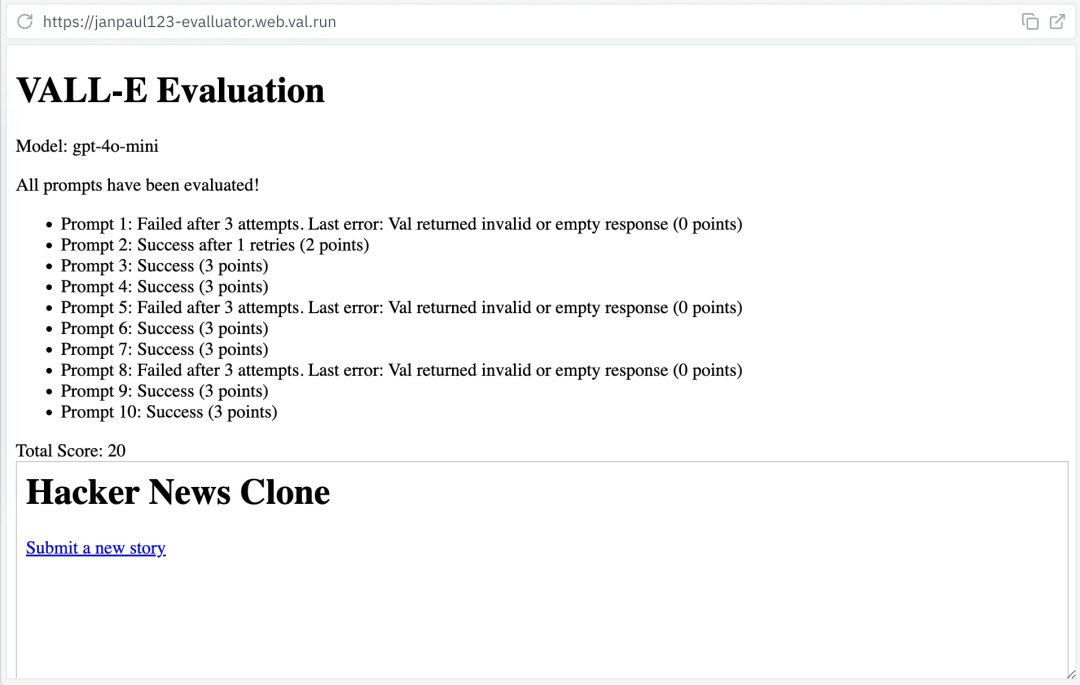 https://blog.val.town/blog/codegen/
https://blog.val.town/blog/codegen/长上下文 RAG 表现的LLM性能
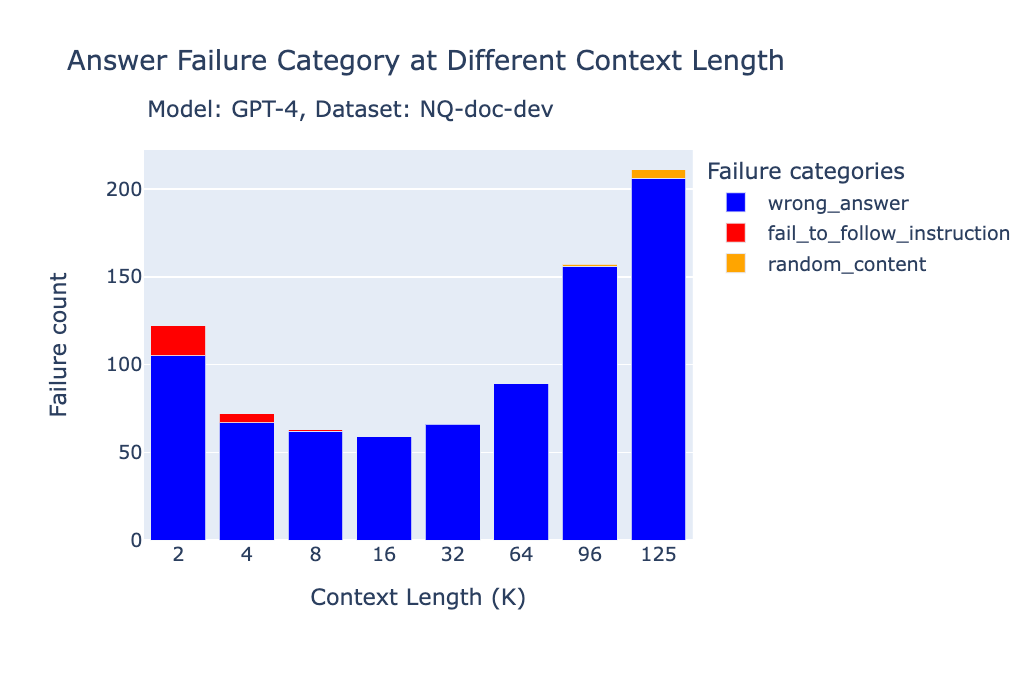 https://www.databricks.com/blog/long-context-rag-performance-llms
https://www.databricks.com/blog/long-context-rag-performance-llmsEP8对话淦创、周衔:RoboGen如何通过生成模型和可微分模拟大规模合成机器人示教数据
 https://mp.weixin.qq.com/s/MaJA3vaf1MH6fyLGFpdcGQ
https://mp.weixin.qq.com/s/MaJA3vaf1MH6fyLGFpdcGQJuiceFS 在多云架构中加速大模型推理
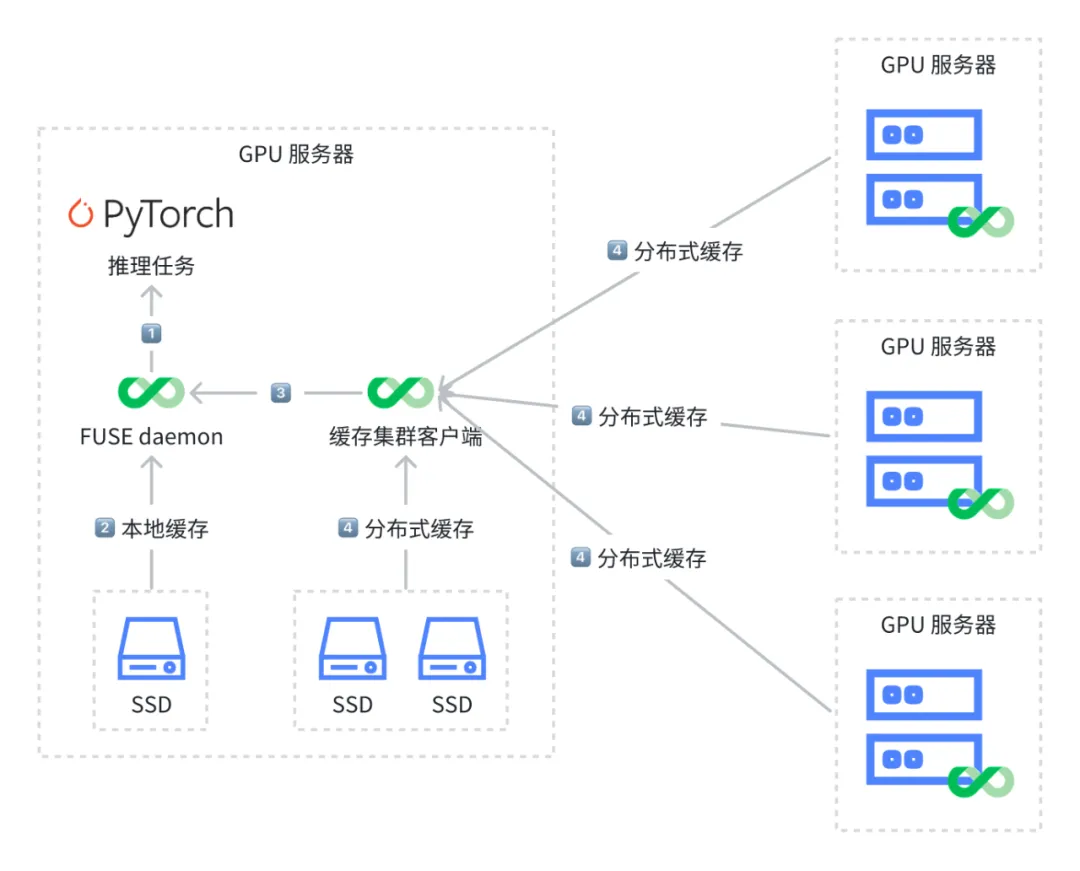 https://mp.weixin.qq.com/s/j6AlSqKxKInAKeBfADJdOA
https://mp.weixin.qq.com/s/j6AlSqKxKInAKeBfADJdOAStream-K 和 Lean-Attention
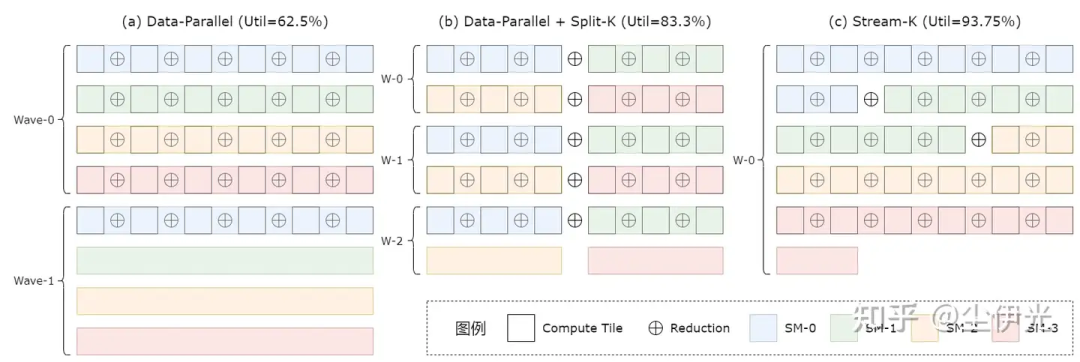 https://zhuanlan.zhihu.com/p/716352563?utm_psn=1811049576632832001
https://zhuanlan.zhihu.com/p/716352563?utm_psn=1811049576632832001大模型的基本功
-
模型转换脚本(trans_XX_to_llama.py):在开源社区中,LLama的网络结构占据主导地位。作者建议编写脚本,以便使用 modeling_llama.py加载其他开源模型,如Qwen、Baichuan等。这不仅能帮助理解不同模型的特性,还能通过对比论文找到模型设计上的独特之处。 -
自定义模型文件(modeling_XX.py):建议创建属于自己的 modeling_XX.py文件,将各家实现的优点整合到一起。这样在遇到新的开源模型时,可以通过简单的转换脚本实现快速微调,而无需修改训练代码。作者还建议添加一些调试函数,如计算隐藏层的余弦距离、预测下一token的最大可能性等,以帮助日常开发。 -
多模型推理(multi_infer.py):传统的 model.generate()方法在多卡并行时效率较低,作者建议编写一个推理类,通过多进程或其他方式实现更快的推理速度。还可以通过定制modeling_XX.py文件中的设备管理函数,提升代码的优雅性和灵活性。 -
通道损失(Channel Loss):在进行领域模型的后预训练(post-pretrain)时,传统的损失曲线提供的信息有限。作者建议对数据源进行分类,并在训练过程中绘制每个通道的损失曲线,以便更好地分析和解决问题。
-
进一步研究Megatron和DeepSpeed等框架下的模型转换和并行推理。 -
在多机环境下实现并行推理,并学习更快的推理框架,如vllm。 -
在封装较深的训练方式中,如何有效地引入和监控Channel Loss。
mlx-llm
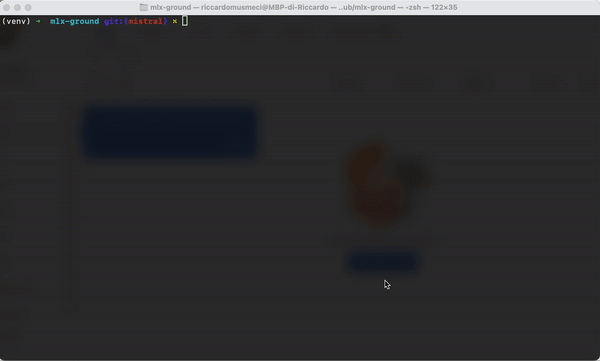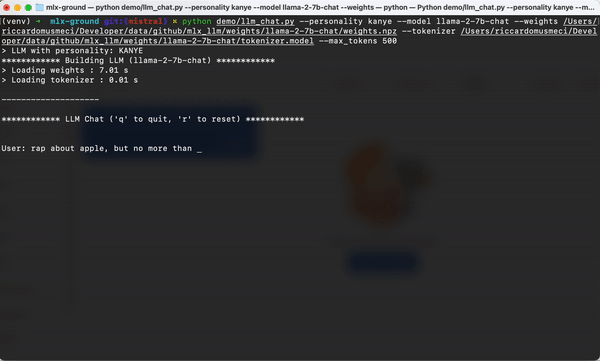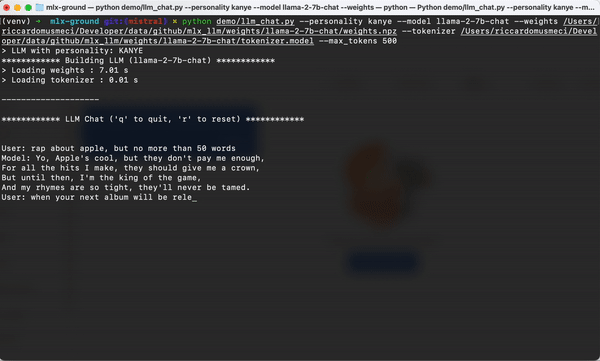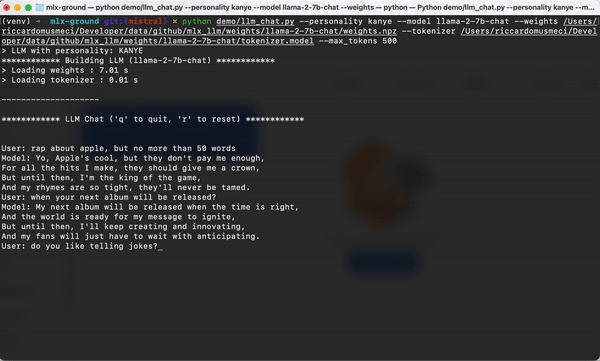 https://github.com/riccardomusmeci/mlx-llm
https://github.com/riccardomusmeci/mlx-llmMultiPL-E
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/08/13398.html