
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


学习
如何优雅地测量GPU CUDA Kernel耗时?
cudaEventCreate、cudaEventRecord、cudaEventSynchronize、cudaEventElapsedTime 和 cudaEventDestroy),允许开发者更精确地测量指定核函数的执行时间,并提供了统计信息如平均时间、中位数和分布等。最后,作者还提到了其他工具如 NCU,并强调了在实际应用中选择合适的测量方法的重要性。 https://zhuanlan.zhihu.com/p/712660021?utm_psn=1804173156463808514
https://zhuanlan.zhihu.com/p/712660021?utm_psn=1804173156463808514如何把 PyTorch 的 GPU 利用率提升到 100% ?
nvidia-smi dmon、NVIDIA Nsight Systems (NSYS)、NVIDIA Data Center GPU Manager (DCGM) 和 NVIDIA Management Library (NVML) 等多种方式。torch原生——tensor并行&张量并行(附带MLP例子)
torch.distributed.tensor.parallel模块,专门用于张量并行。核心函数parallize_module负责将模型并行化。并行化方法通过设置不同的ParallelStyle来定义,包括ColwiseParallel和RowwiseParallel两种主要的张量并行方式,以及SequenceParallel、PrepareModuleInput和PrepareModuleOutput等。这些并行策略需要指定参数、输入和输出的处理方式,即Placement,包括Shard、Replicate和_Partial三种方法。通过一个 MLP 的例子,文章展示了如何将nn.Linear层的参数沿列或行分割,以及如何在多个 GPU 上复制模型或进行维度对齐。此外,文章还强调了并行训练过程中的关键点,如梯度累积、通信开销和内存使 AGE,以及如何使用torch.cuda.memory_allocated()来监控内存使用情况。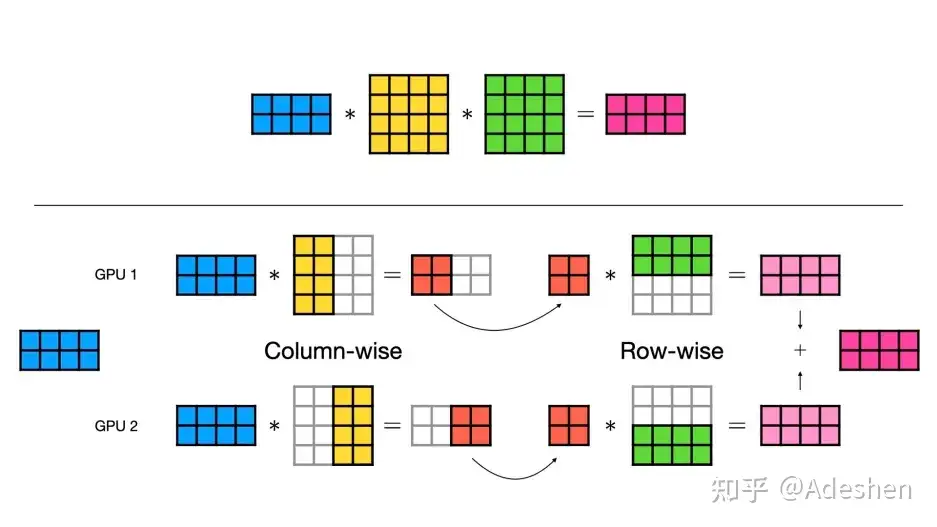 https://zhuanlan.zhihu.com/p/707711038?utm_psn=1804464555071528960
https://zhuanlan.zhihu.com/p/707711038?utm_psn=1804464555071528960使用 vLLM 为多个 LoRA 适配器提供服务
[2024智源大会速览] 视频生成篇
 https://zhuanlan.zhihu.com/p/713143946?utm_psn=1804435630656192512
https://zhuanlan.zhihu.com/p/713143946?utm_psn=1804435630656192512大模型分不清 9.9 与 9.11 谁大,那 Embedding 模型呢?
jina-embeddings-v2-base-en和jina-reranker-v2-multilingual模型进行的实验,文章评估了它们在不同数字比较场景下的性能,包括小数、货币、日期和时间等。实验采用余弦相似度和相关性得分作为评价指标,结果显示 Embedding 模型在简单数字比较中表现较好,但在复杂数值区间或浮点数比较时效果下降。Reranker 模型在这些任务中的表现不稳定,尤其是在处理大数字和随机数字范围时。文章指出,分词策略和训练数据对模型的数值推理能力有重要影响,并强调了这种能力对于提升搜索质量的重要性。特别是在处理结构化数据如 JSON 时,模型的算术能力至关重要。 https://mp.weixin.qq.com/s/wIm3loi5KcznFYTpgIl-Dg
https://mp.weixin.qq.com/s/wIm3loi5KcznFYTpgIl-DgMiniCPM-V-2_6
 https://huggingface.co/openbmb/MiniCPM-V-2_6
https://huggingface.co/openbmb/MiniCPM-V-2_6VidGen-1M
 https://sais-fuxi.github.io/projects/vidgen-1m/
https://sais-fuxi.github.io/projects/vidgen-1m/原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/08/13798.html