
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


学习
Minimax Link伙伴日学习笔记
1. minimax 每天全线消耗 3 万亿 tokens。2. 用 linear attention+moe 结构增加上下文长度,降低推理成本。minimax 推测 OpenAI 也是这么做的。3. linear attention 的训练,推理的工程挑战都不一样。4. linear attention 序列并行方法需要重新设计,采用类似 ring 方式,但通信量和序列长度无关。5. linear attention 计算速度快于标准注意力,通信极易成瓶颈,训练算法的的 optimizer 需要修改成异步的,来重叠通信与计算。6. linear attention 推理没有 kvcache。不需要投机采样,也没有现在流行的 kvcache 为中心的各种优化,比如 pd 分离,prefix cache 之类的。7. linear 推理可以实现近乎无限上下文,而且历史信息就是 K× V 大小O(d^2),存储特别少。8. 有 TNL(minimax 的 linear attention 结构名称)的 scaling law 实验。交流完挺震撼的,如果 llm 未来都变成 linear attention 的话,搞 llm kvcache 优化的,搞大带宽芯片的,可能都白忙活了。#多模态 部分
1. 现场有一个视频生成剪辑炸场,大家在视频号能看到。2. 生成5s 720p 的视频demo展示需要三四分钟。DiT实时推理还任重道远,xDiT 大有可为!3. 音乐生成也需要DiT。
 https://www.zhihu.com/pin/1813367383781433344?native=1&scene=share&utm_psn=1813519125974228993
https://www.zhihu.com/pin/1813367383781433344?native=1&scene=share&utm_psn=1813519125974228993Image Tokenizer与Autoregressive Image Generation
 https://zhuanlan.zhihu.com/p/707759472?utm_psn=1813307767139729408
https://zhuanlan.zhihu.com/p/707759472?utm_psn=1813307767139729408阿里开源视觉多模态模型 Qwen2-VL,技术能力如何?
-
动态分辨率支持:能够处理任意分辨率的图片,解决了传统图像处理需要固定大小的问题。这使得模型在视觉任务中更为灵活,尤其是在理解长达20分钟以上的视频时表现突出。 -
多模态旋转位置嵌入(M-ROPE):通过将旋转嵌入分解为时间、高度和宽度三部分,模型可以更好地捕捉和整合一维文本、二维图像以及三维视频的位置信息,大大提升了复杂场景的处理能力。 -
广泛的多语言支持:除了中文和英文外,Qwen2-VL 还支持大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。这使得模型在全球范围内的适用性更广泛。 -
模型结构:采用了 ViT 加 Qwen2 的串联结构,在不同规模的模型上都使用了 600M 的 ViT,支持图像和视频的统一输入,并实现了原生动态分辨率的全面支持,图像被转换为动态数量的 tokens,最小只占 4 个 tokens。
 https://www.zhihu.com/question/665704731?utm_psn=1813306893352968193
https://www.zhihu.com/question/665704731?utm_psn=1813306893352968193MAGPIE: 通过无提示对齐的LLM从零开始合成对齐数据
 https://zhuanlan.zhihu.com/p/717562402?utm_psn=1813306215532457984
https://zhuanlan.zhihu.com/p/717562402?utm_psn=1813306215532457984LLM 推理/训练 I/O Pattern初探
-
LLM 推理应用
-
Syscall Trace分析:记录了72713行系统调用,其中与模型文件和文件系统相关的仅3079行,主要涉及
openat、statx、mmap、fstat等系统调用。发现LLM推理中大量使用mmap系统调用进行匿名内存映射,futex调用频率极高,但其主要用于线程同步,较少涉及底层文件系统交互。 -
mmap细节:
mmap与munmap调用时间差非常短,约为1.97毫秒,无法解释大模型(如20G)如何在如此短的时间内加载至显存。 -
Blktrace分析:总I/O请求主要集中在4KB、128KB和256KB,写操作的I/O大小集中在4KB和512KB,读写操作表现出高度随机性。
-
LLM 训练应用
-
Syscall Trace分析:训练阶段包括模型定位、加载至显存以及保存checkpoint等操作,主要使用
stat、lseek、read等系统调用。不同于预期的顺序读取,实际发现大量随机读取操作,系统频繁调用lseek调整文件读取位置。 -
Blktrace分析:训练过程中I/O请求主要集中在4KB、128KB和512KB,顺序读写操作占大多数。训练数据写入时占用了显著的I/O带宽,每次训练完成后将显存中的数据写入文件系统。
-
I/O 特征总结
-
推理应用:随机读写操作占主导,特别是在访问大模型时,推测是由于系统通过索引机制进行数据读取,非顺序读取。
-
训练应用:顺序读写占主导,读写字节比接近1:2,符合模型读入与训练数据写入的预期。随机写的比例较低,但其对性能的影响值得进一步研究。
-
后续建议
作者提出需要进一步研究索引文件以及PyTorch的源码,尤其是如何通过索引文件将大模型有效加载至显存。此外,由于syscall trace中没有发现传统的阻塞I/O或异步I/O调用,建议深入分析PyTorch是如何处理大模型加载的底层机制。
 https://zhuanlan.zhihu.com/p/717560804?utm_psn=1813305085435981824
https://zhuanlan.zhihu.com/p/717560804?utm_psn=1813305085435981824
存储 IO 性能优化策略、方案与瓶颈分析
-
IO模型特性:不同应用的IO特性各异,需针对性优化。
-
性能指标:主要指标为吞吐量、IOPS和延时,需根据应用场景选取并优化。
-
优化策略:
-
存储设备:选择适合的磁盘类型和优化缓存机制。
-
网络:提高带宽,减少延时。
-
传输协议:选择高效协议。
-
主机与应用层:调整系统配置,优化数据库查询和索引。
-
数据库瓶颈:关系型数据库的IO瓶颈常在日志写入,需优化硬件与操作系统配置。
-
Queue-Depth管理:队列深度影响并发IO性能,但需避免过高导致的QFULL问题。
整体优化需综合各层面的性能需求和瓶颈分析,实现高效存储IO性能。
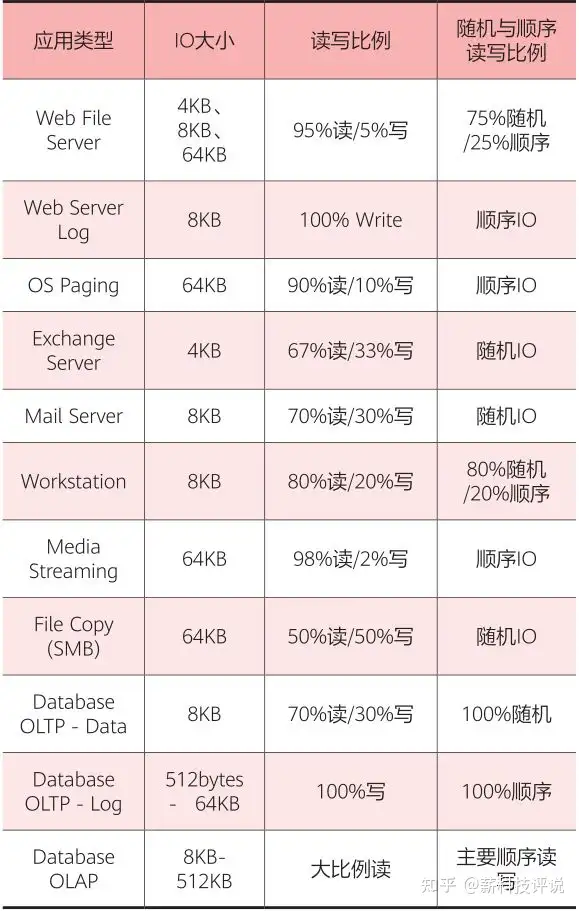 https://zhuanlan.zhihu.com/p/717518412?utm_psn=1813531135659098112
https://zhuanlan.zhihu.com/p/717518412?utm_psn=1813531135659098112
Intel 微架构的演进
-
80486(1989年):首次集成片上缓存和数学协处理器,提升浮点计算性能。 -
P5(1993年):引入超标量处理和分支预测,但存在BTB局限性。 -
P6(1995年):支持乱序执行,改进指令解码和寄存器管理,显著提升处理效率。 -
NetBurst(2000年):采用长流水线,专注于高频率,但复杂结构导致性能瓶颈。 -
Pentium M(2003年):优化功耗与性能,改进µop融合和分支预测,适用于移动设备。 -
Yonah(2006年):引入双核和SSE3指令集,改进分支预测但仍存在误预测损失。 -
Core(2006年):重大升级,支持64位,提升每瓦性能,通过Macro-Ops Fusion优化执行效率。 -
Sandy Bridge(2011年):引入AVX指令集和µOP缓存,优化环形总线,实现性能与功耗平衡。 -
Skylake(2015年):前端和乱序执行全面升级,提升多线程处理性能。 -
SunnyCove(2019年):10nm制程,高乱序执行能力,增强前端与重命名器,提升整体性能。 -
Golden Cove(2021年):进一步优化分支预测和重排序,提升多线程环境下的执行效率。
 https://zhuanlan.zhihu.com/p/571333092?utm_psn=1813175575130550272
https://zhuanlan.zhihu.com/p/571333092?utm_psn=1813175575130550272大模型训练:如何优化MFU
【滴水研究】智能时代纪事:人形机器人产业研究(下篇)
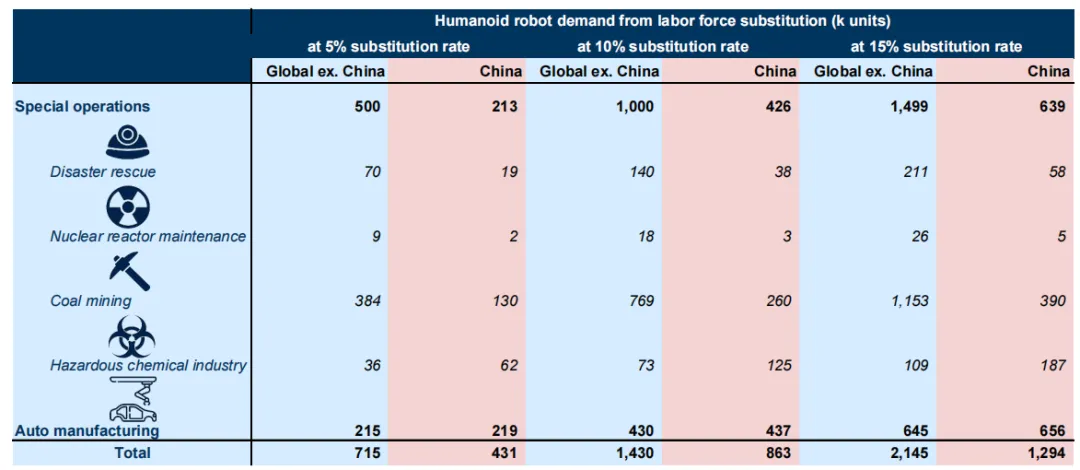 https://mp.weixin.qq.com/s/JT50Q55eOCPx-1gQvc6O-Q
https://mp.weixin.qq.com/s/JT50Q55eOCPx-1gQvc6O-QBaichuanSEED
kotaemon
 https://github.com/Cinnamon/kotaemon
https://github.com/Cinnamon/kotaemon原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/09/13235.html