
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
AgentGen: 通过环境和任务生成增强基于大语言模型智能体的规划能力
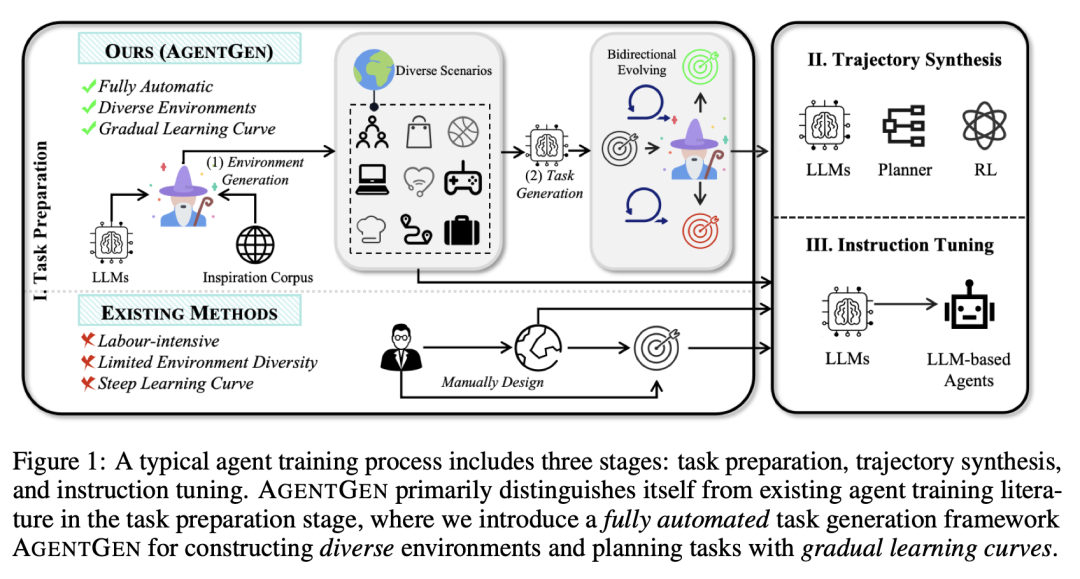
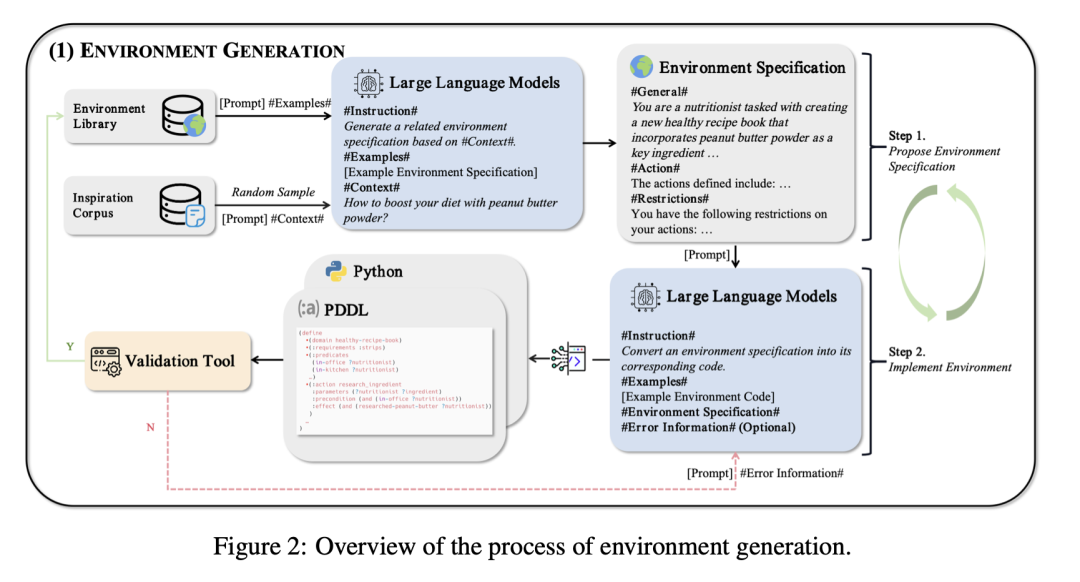 http://arxiv.org/abs/2408.00764v1
http://arxiv.org/abs/2408.00764v1Intermittent Semi-working Mask:LLM的新蒙版范例
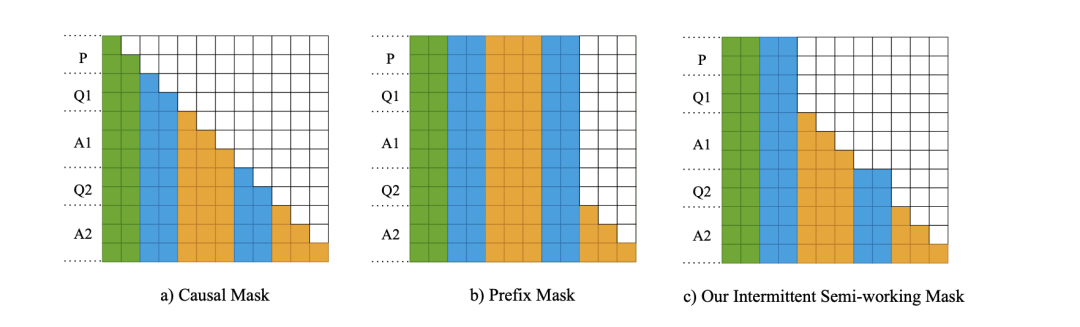
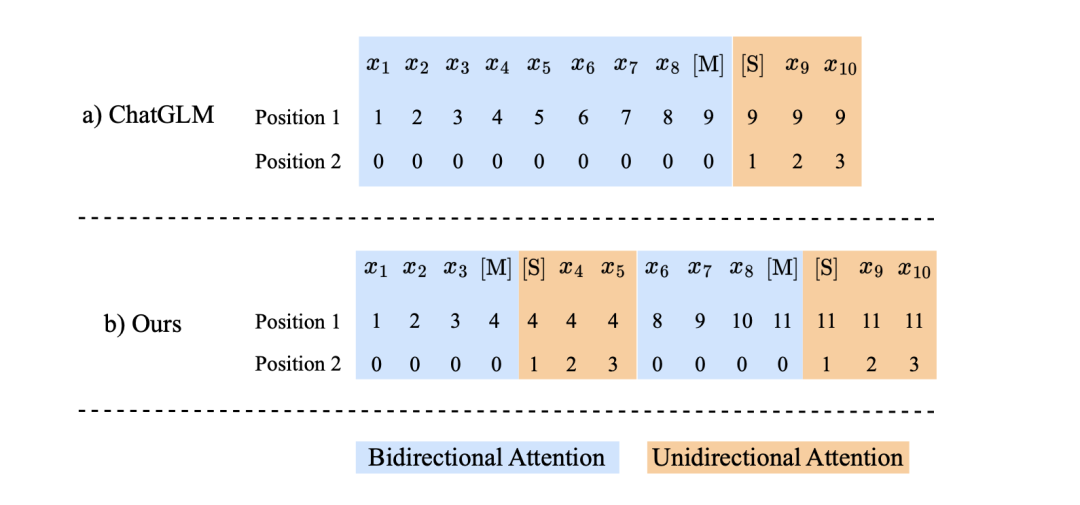 http://arxiv.org/abs/2408.00539v1
http://arxiv.org/abs/2408.00539v1QUITO: 通过查询引导的上下文压缩加速长上下文推理
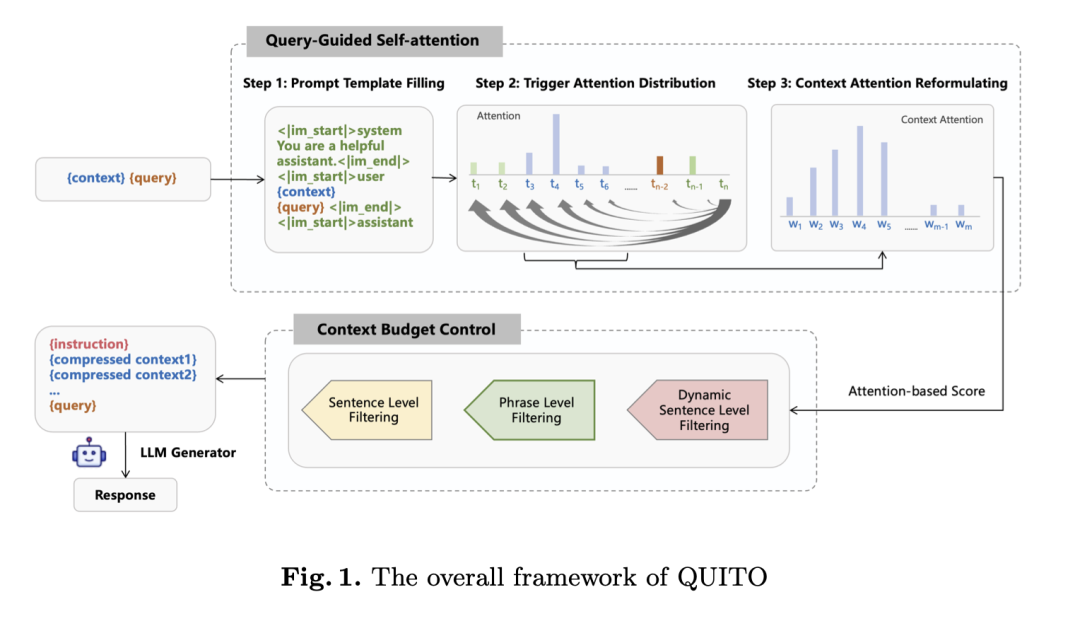 http://arxiv.org/abs/2408.00274v1
http://arxiv.org/abs/2408.00274v1在大语言模型中通过负关注得分对齐来纠正负偏差
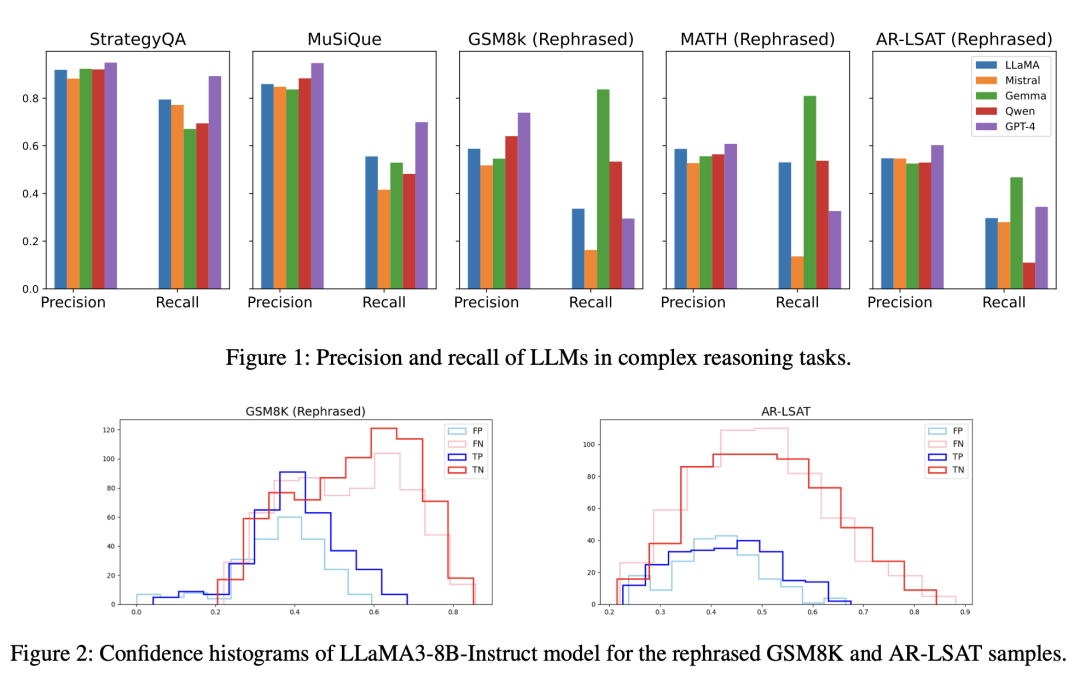 http://arxiv.org/abs/2408.00137v1
http://arxiv.org/abs/2408.00137v1开放权重LLMs的防篡改保障
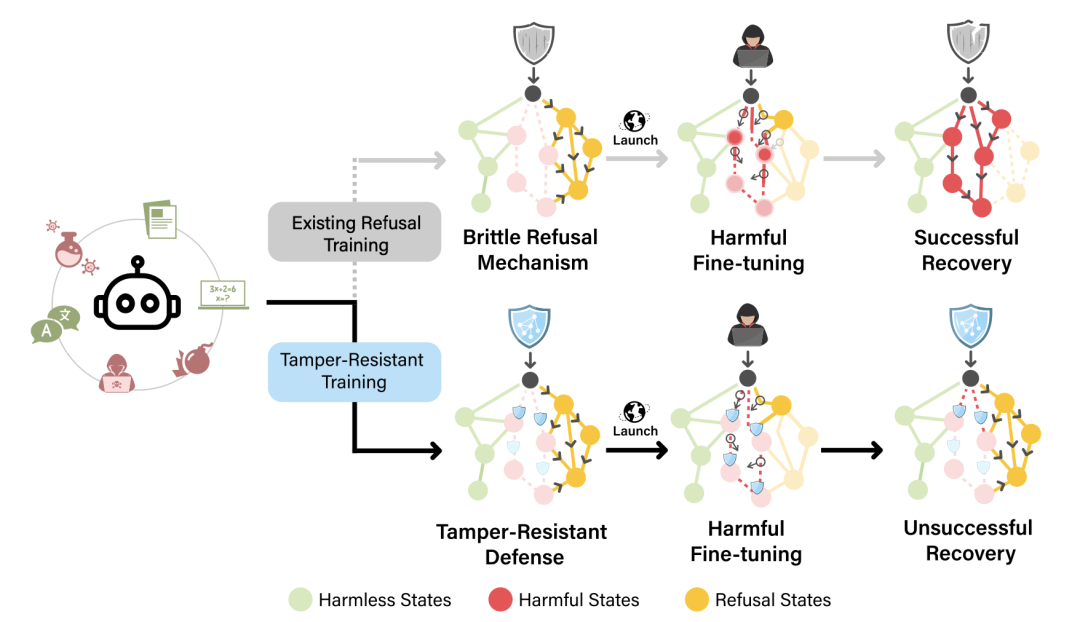 http://arxiv.org/abs/2408.00761v1
http://arxiv.org/abs/2408.00761v1加速全波形反演的迁移学习
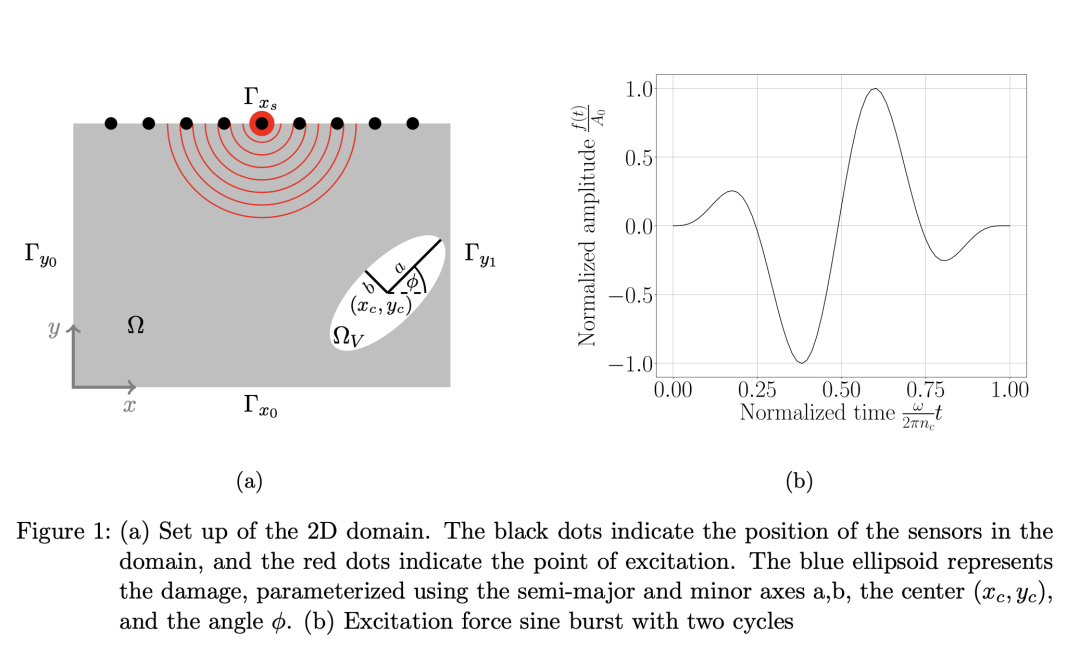 http://arxiv.org/abs/2408.00695v1
http://arxiv.org/abs/2408.00695v1关于机器反学习用于生成人工智能的局限性和前景
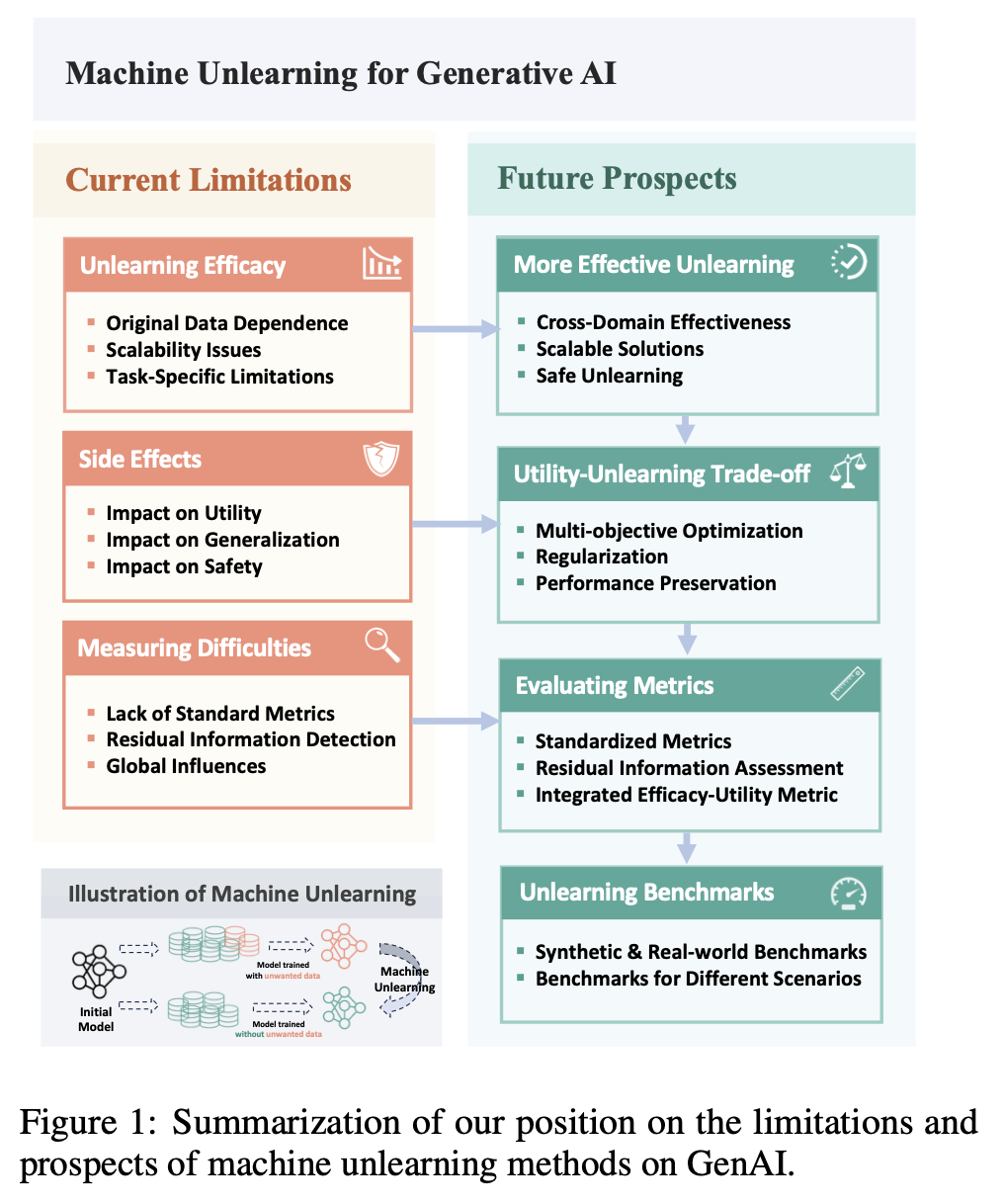 http://arxiv.org/abs/2408.00376v1
http://arxiv.org/abs/2408.00376v1ABC Align:安全与准确性的大语言模型对齐
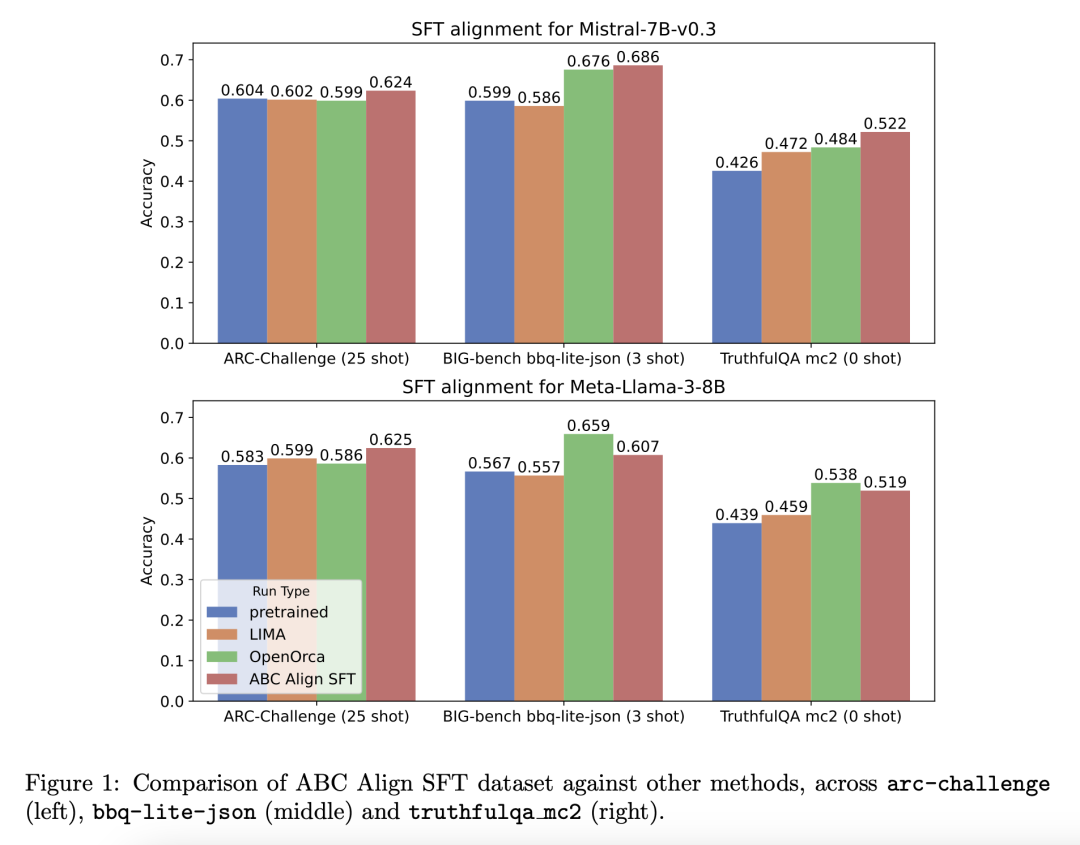 http://arxiv.org/abs/2408.00307v1
http://arxiv.org/abs/2408.00307v1CosyVoice
ASTRA.ai
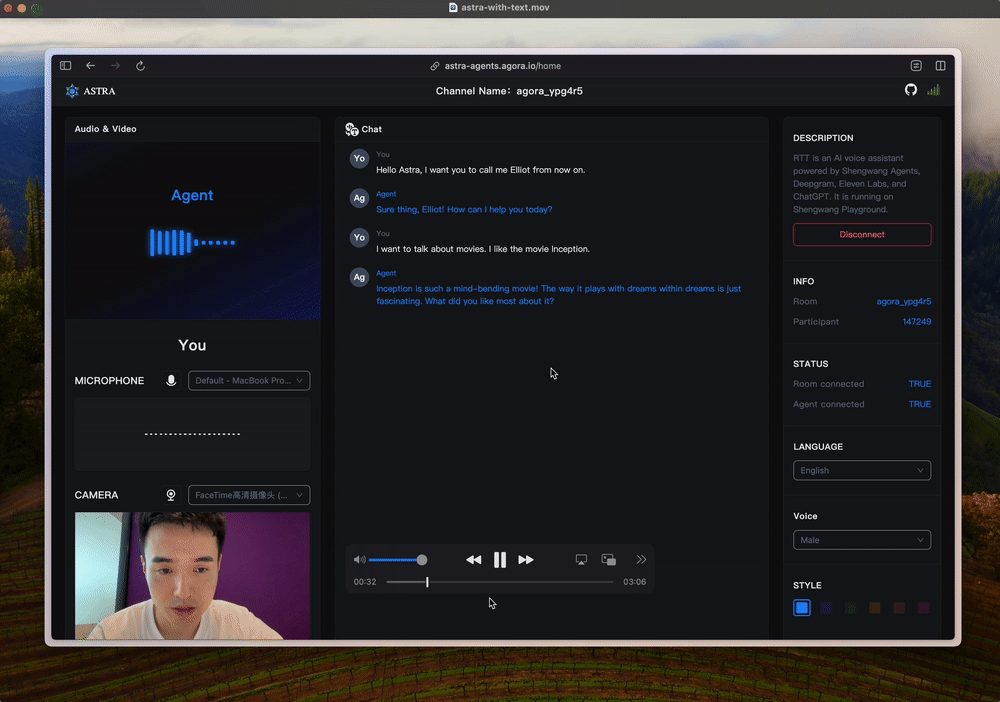
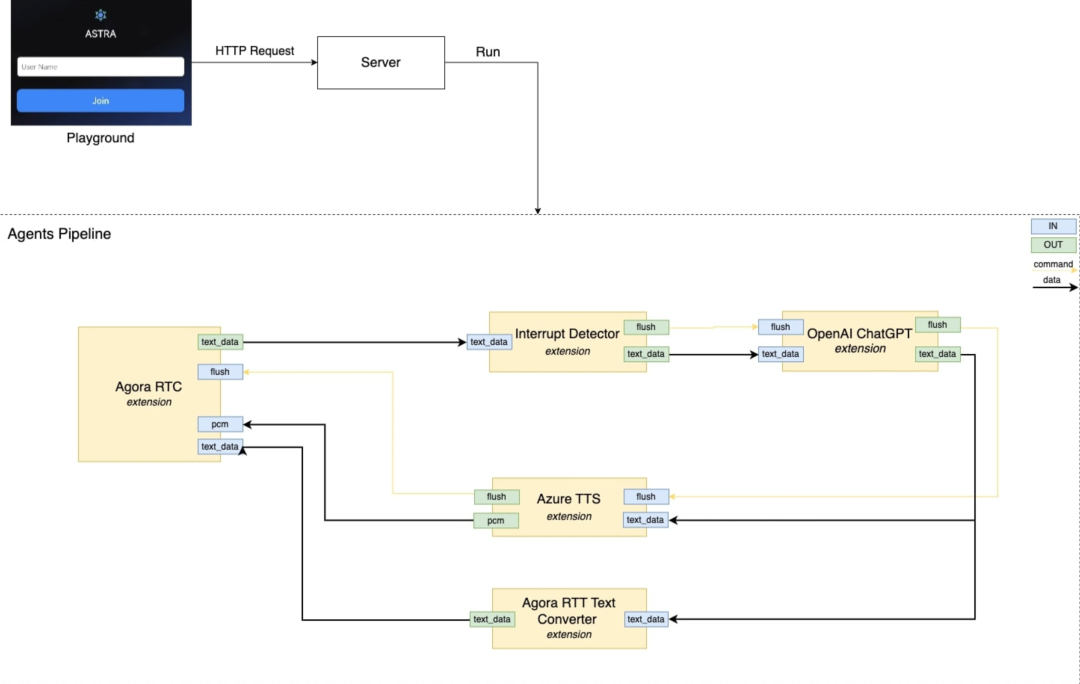 https://github.com/rte-design/ASTRA.ai
https://github.com/rte-design/ASTRA.ai原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/08/13881.html