
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
DeepSeek-Coder-V2: 打破代码智能中封闭模型的壁垒
 http://arxiv.org/abs/2406.11931v1
http://arxiv.org/abs/2406.11931v1ChatGLM: 从GLM-130B到GLM-4 All Tools的大语言模型家族
 http://arxiv.org/abs/2406.12793v1
http://arxiv.org/abs/2406.12793v1奥林匹克竞技场:超智能人工智能测试多学科认知推理
 http://arxiv.org/abs/2406.12753v1
http://arxiv.org/abs/2406.12753v1Chumor 1.0:一份真正有趣且具挑战性的中文幽默理解数据集(来自弱智吧)
 http://arxiv.org/abs/2406.12754v1
http://arxiv.org/abs/2406.12754v1思维抽象化使语言模型成为更好的推理者
 http://arxiv.org/abs/2406.12442v1
http://arxiv.org/abs/2406.12442v1WebCanvas: 在线环境中对Web智能体进行基准测试
 http://arxiv.org/abs/2406.12373v1
http://arxiv.org/abs/2406.12373v1基于Hopfield的视角解释智能体的思维链推理
 http://arxiv.org/abs/2406.12255v1
http://arxiv.org/abs/2406.12255v1从众包数据到高质量基准:Arena-Hard和BenchBuilder流水线
 http://arxiv.org/abs/2406.11939v1
http://arxiv.org/abs/2406.11939v1PlanRAG: 一个计划-检索增强生成器的方法,使大型语言模型成为决策者
 http://arxiv.org/abs/2406.12430v1
http://arxiv.org/abs/2406.12430v1Meta Chameleon
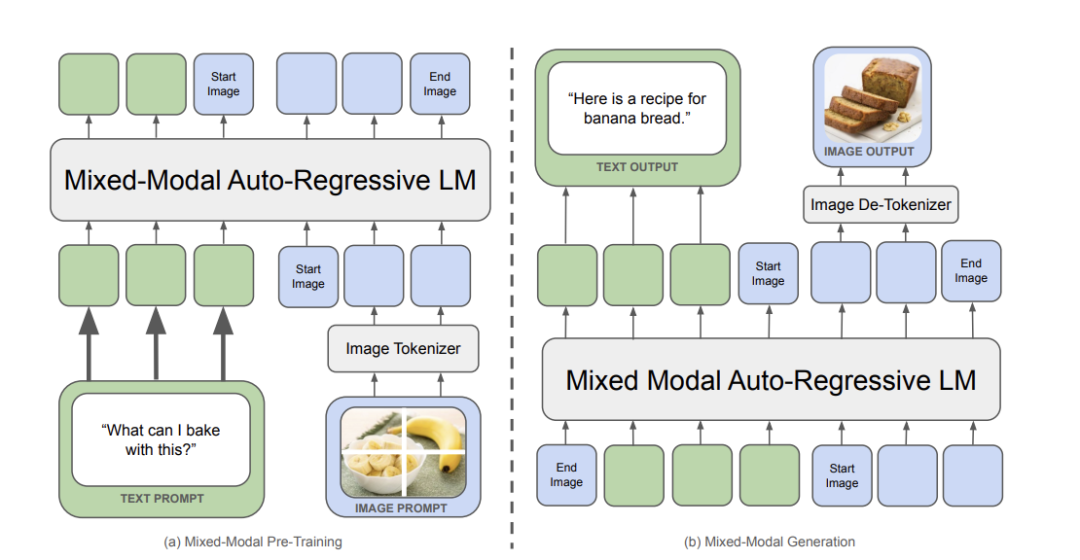 https://github.com/facebookresearch/chameleon
https://github.com/facebookresearch/chameleonIMAGDressing-v1
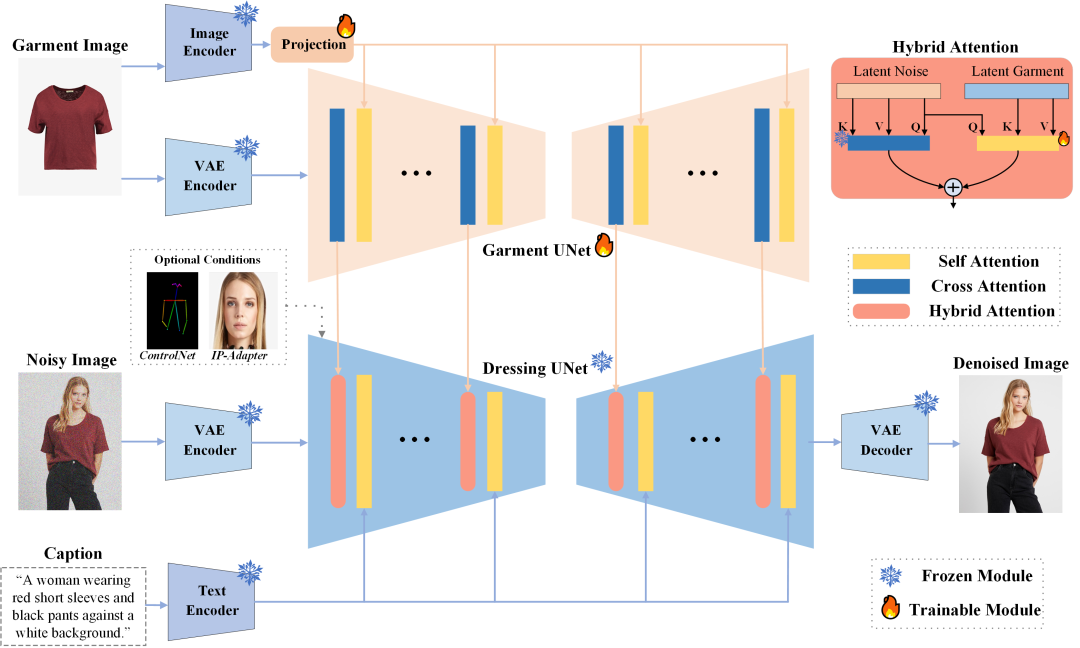 https://imagdressing.github.io/
https://imagdressing.github.io/原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/06/14643.html