
特别活动


我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。

论文
超越缩放定律:用关联记忆理解Transformer的性能
 http://arxiv.org/abs/2405.08707v1
http://arxiv.org/abs/2405.08707v1使用动态可组合的多头注意力优化Transformer
 http://arxiv.org/abs/2405.08553v1
http://arxiv.org/abs/2405.08553v1CinePile:一个长视频问答资料集和基准
 http://arxiv.org/abs/2405.08813v1
http://arxiv.org/abs/2405.08813v1EfficientTrain++: 高效视觉主干训练的通用课程学习
 http://arxiv.org/abs/2405.08768v1
http://arxiv.org/abs/2405.08768v1完整代码补全:将人工智能带到桌面
 http://arxiv.org/abs/2405.08704v1
http://arxiv.org/abs/2405.08704v1Funclip
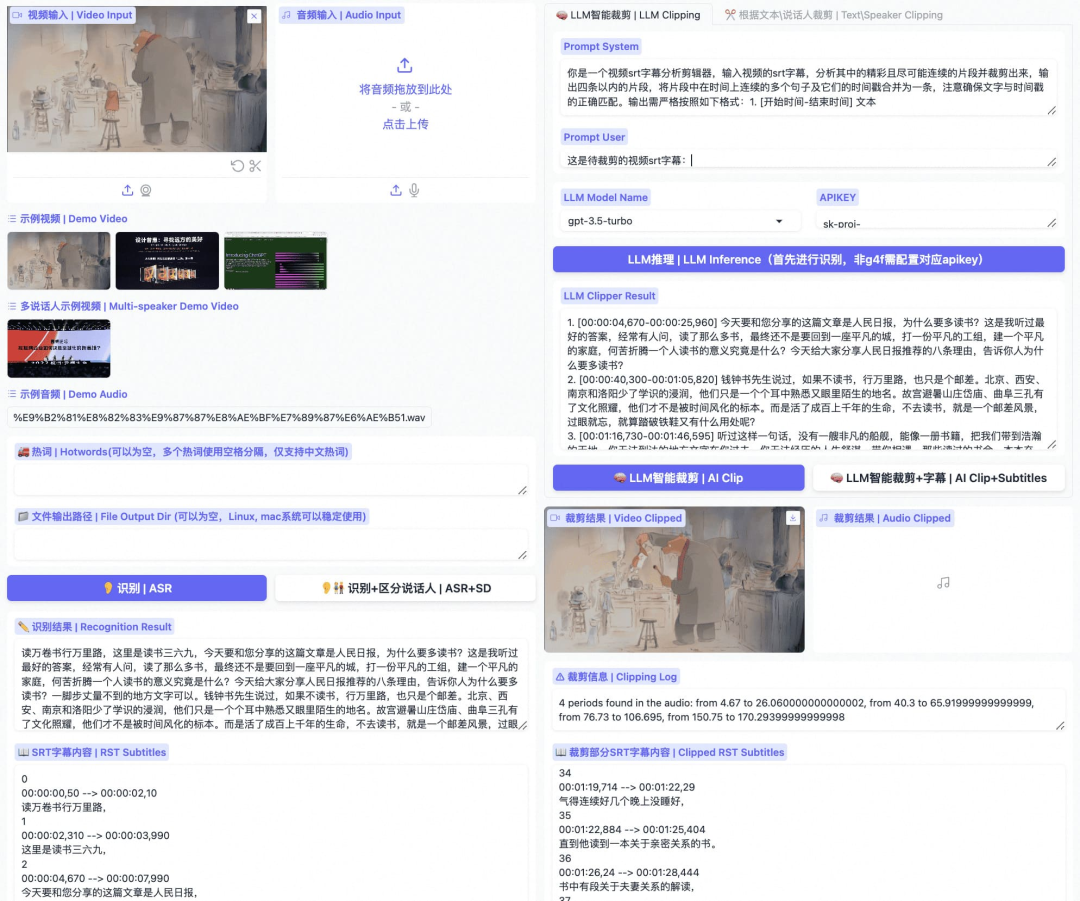 https://github.com/alibaba-damo-academy/FunClip
https://github.com/alibaba-damo-academy/FunClip腾讯混元——DiT
 https://huggingface.co/Tencent-Hunyuan/HunyuanDiT
https://huggingface.co/Tencent-Hunyuan/HunyuanDiT原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15410.html