
欢迎观看大模型日报,进入大模型日报群和空间站(活动录屏复盘聚集地)请直接扫码。社群内除日报外还会第一时间分享大模型活动。


学习
如何看待 Meta 发布 Llama3,并将推出 400B+ 版本?
Llama3 微调项目实践与教程(XTuner 版)
 https://mp.weixin.qq.com/s/sKet1R4k_Xwmfo6D_x17Rw
https://mp.weixin.qq.com/s/sKet1R4k_Xwmfo6D_x17RwLlama 3开源!魔搭社区 推理,部署,微调和评估 教程
 https://mp.weixin.qq.com/s/hiRtM4jrGyFF_utCE1-LCA
https://mp.weixin.qq.com/s/hiRtM4jrGyFF_utCE1-LCA搞懂 CUDA Shared Memory 上的 bank conflicts 和向量化指令(LDS.128 / float4)的访存特点
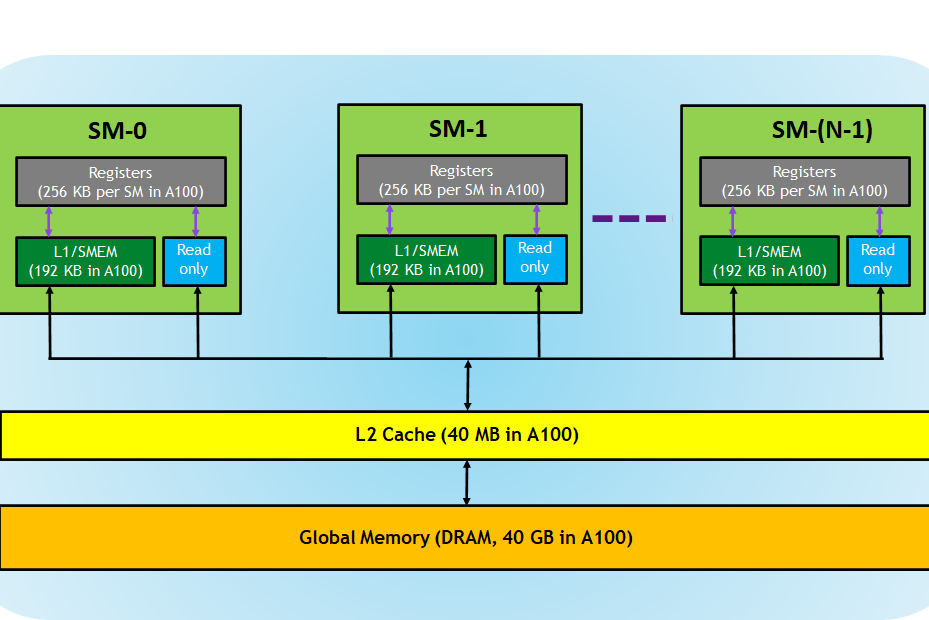 https://zhuanlan.zhihu.com/p/690052715
https://zhuanlan.zhihu.com/p/690052715Diffusion模型推理过程中的Cache
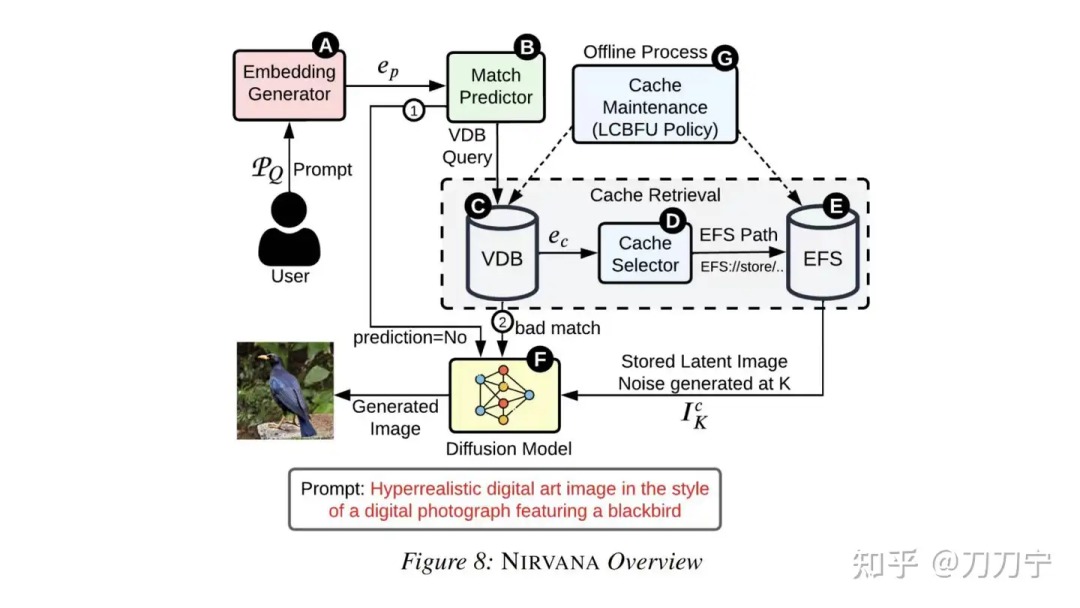 https://zhuanlan.zhihu.com/p/689685429?utm_psn=1764794438206042112
https://zhuanlan.zhihu.com/p/689685429?utm_psn=1764794438206042112视觉变换器的视觉指南
Firecrawl
 https://github.com/mendableai/firecrawl
https://github.com/mendableai/firecrawlFlyte
 https://github.com/flyteorg/flyte
https://github.com/flyteorg/flyte
rtp-llm

大模型日报16
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/04/15925.html