
特别活动


我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。

论文
Plot2Code:科学图表的代码生成中评估多模大语言模型的全面基准测试
 http://arxiv.org/abs/2405.07990v1
http://arxiv.org/abs/2405.07990v1
Zero-shot tokenizer 转移
 http://arxiv.org/abs/2405.07883v1
http://arxiv.org/abs/2405.07883v1课程数据排序:通过课程学习提升大语言模型性能
 http://arxiv.org/abs/2405.07490v1
http://arxiv.org/abs/2405.07490v1CoRE: LLM作为自然语言编程、伪代码编程和AI智能体编程的解释器
 http://arxiv.org/abs/2405.06907v1
http://arxiv.org/abs/2405.06907v1通过自然语言将静态调度器自动转换为动态调度器
 http://arxiv.org/abs/2405.06697v1
http://arxiv.org/abs/2405.06697v1Word2World: 通过大语言模型生成故事和世界
 http://arxiv.org/abs/2405.06686v1
http://arxiv.org/abs/2405.06686v1开放SQL框架:在开源大语言模型上增强文本到SQL的能力
 http://arxiv.org/abs/2405.06674v1
http://arxiv.org/abs/2405.06674v1训练更快,表现更好:超参数模型中的模块化自适应训练
 http://arxiv.org/abs/2405.07527v1
http://arxiv.org/abs/2405.07527v1GPT Table
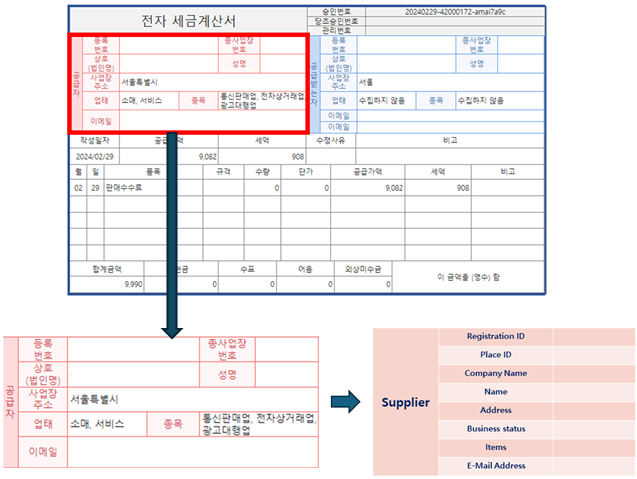 https://github.com/JSJeong-me/GPT-Table
https://github.com/JSJeong-me/GPT-TableAgentScope
 https://github.com/modelscope/agentscope
https://github.com/modelscope/agentscopeLumina-T2X
 https://github.com/Alpha-VLLM/Lumina-T2X
https://github.com/Alpha-VLLM/Lumina-T2X原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/05/15441.html