
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
D-CPT法则:面向领域的大语言模型持续预训练缩放定律

数据集增长
 http://arxiv.org/abs/2406.01375v1
http://arxiv.org/abs/2406.01375v1MMLU-Pro:更强大且具挑战性的多任务语言理解基准
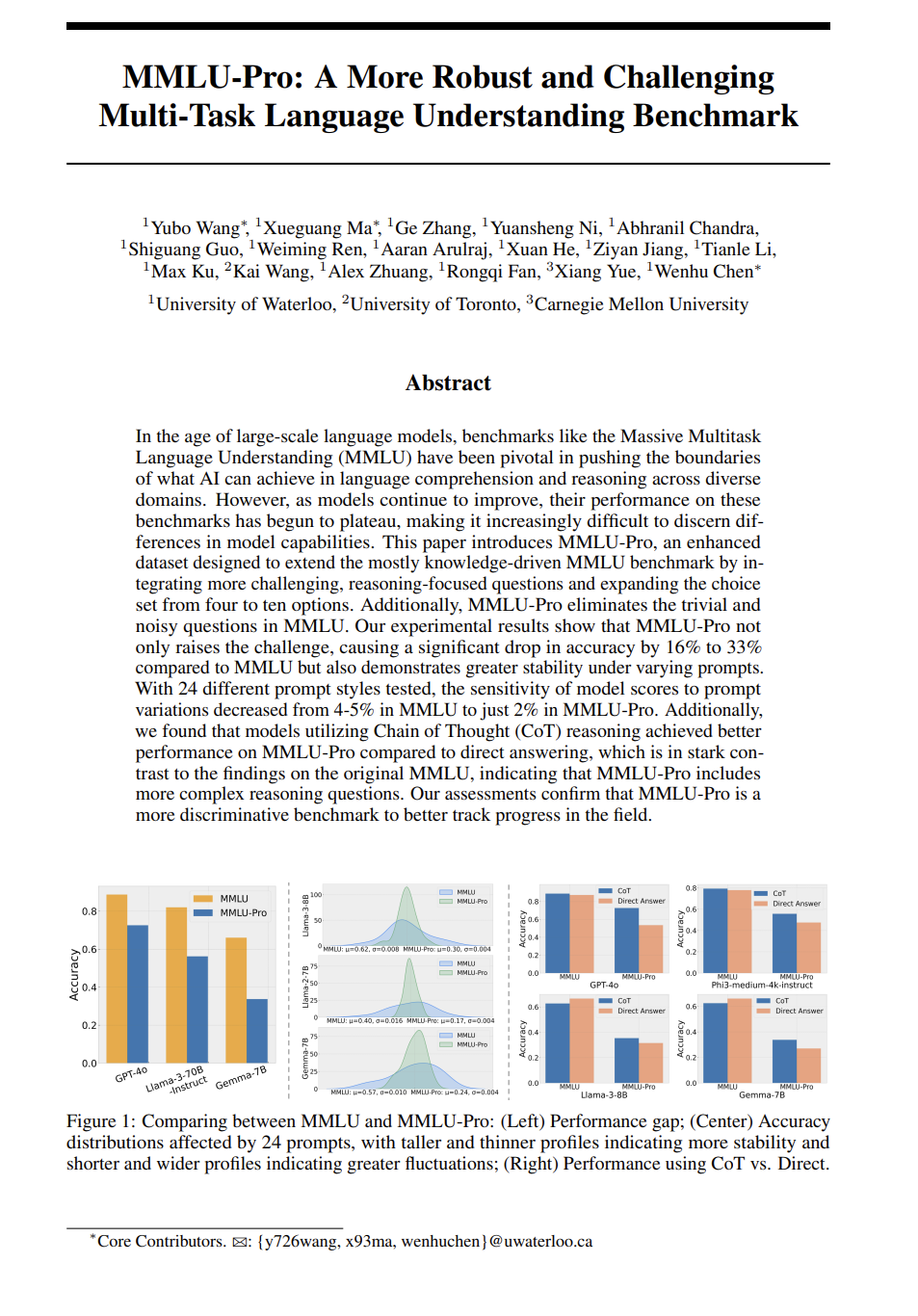 http://arxiv.org/abs/2406.01574v1
http://arxiv.org/abs/2406.01574v1R2C2-Coder:增强和对比代码大语言模型在真实世界代码库级别的代码补全能力
 http://arxiv.org/abs/2406.01359v1
http://arxiv.org/abs/2406.01359v1LongSkywork: 一个高效拓展大语言模型上下文长度的训练方法
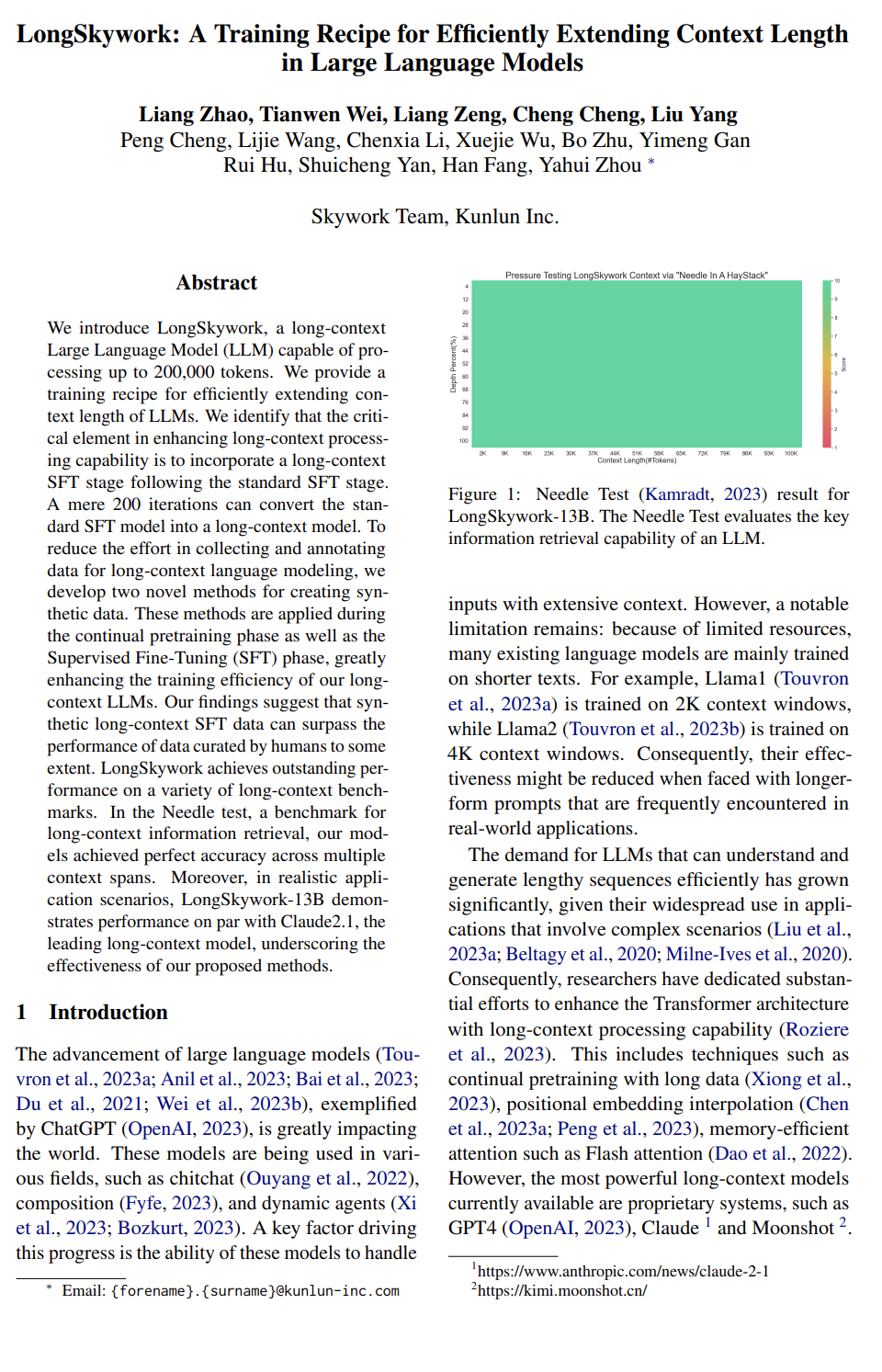 http://arxiv.org/abs/2406.00605v1
http://arxiv.org/abs/2406.00605v1通用上下文提示全循环模型的逼近
 http://arxiv.org/abs/2406.01424v1
http://arxiv.org/abs/2406.01424v1如何理解整个软件库?
 http://arxiv.org/abs/2406.01422v1
http://arxiv.org/abs/2406.01422v1用扩散模型解读甲骨文语言
 http://arxiv.org/abs/2406.00684v1
http://arxiv.org/abs/2406.00684v1rejax
 https://github.com/keraJLi/rejax
https://github.com/keraJLi/rejaxAnimate Anyone
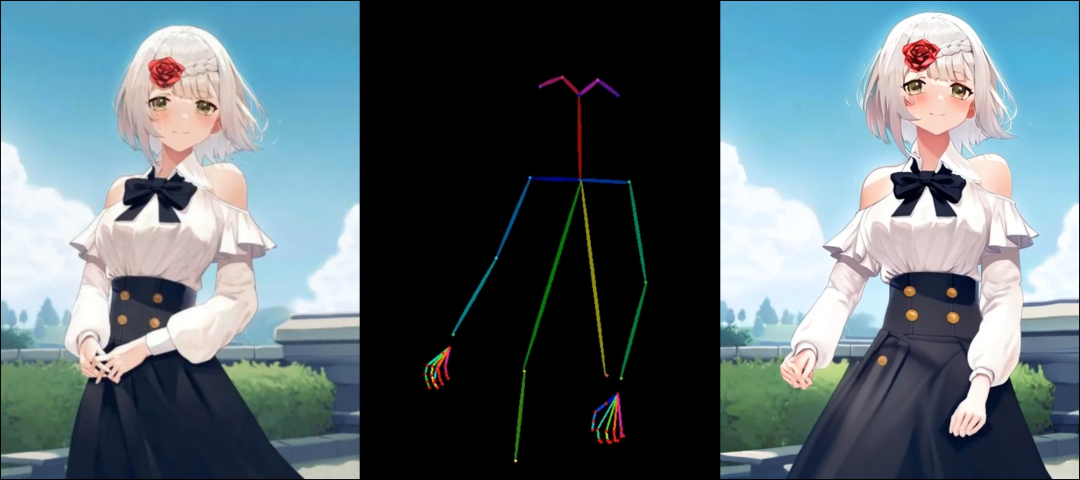 https://github.com/novitalabs/AnimateAnyone
https://github.com/novitalabs/AnimateAnyoneCLIPPyX
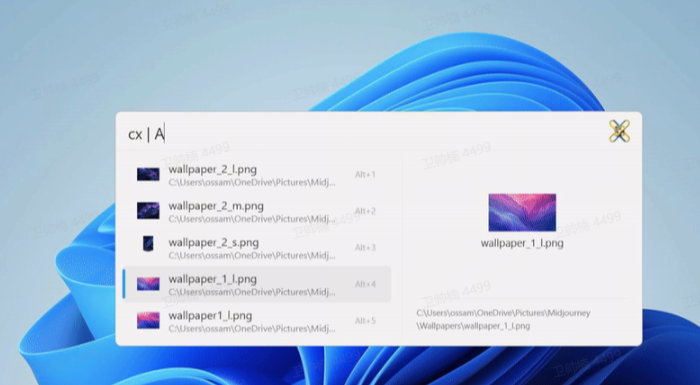 https://github.com/0ssamaak0/CLIPPyX
https://github.com/0ssamaak0/CLIPPyX
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/06/14890.html