
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!


论文
WildBench: 通过由真实用户提出的挑战性任务对LLMs进行基准测试
 http://arxiv.org/abs/2406.04770v1
http://arxiv.org/abs/2406.04770v1CRAG:全面 RAG 基准
 http://arxiv.org/abs/2406.04744v1
http://arxiv.org/abs/2406.04744v1使用Delta规则在序列长度上并行化线性Transformer
 http://arxiv.org/abs/2406.06484v1
http://arxiv.org/abs/2406.06484v1Transformer能推理到多远?局限性和归纳记事板
 http://arxiv.org/abs/2406.06467v1
http://arxiv.org/abs/2406.06467v1Tx-LLM:用于治疗的大语言模型
 http://arxiv.org/abs/2406.06316v1
http://arxiv.org/abs/2406.06316v1Turbo Sparse: 以最少激活参数实现LLM最优性能
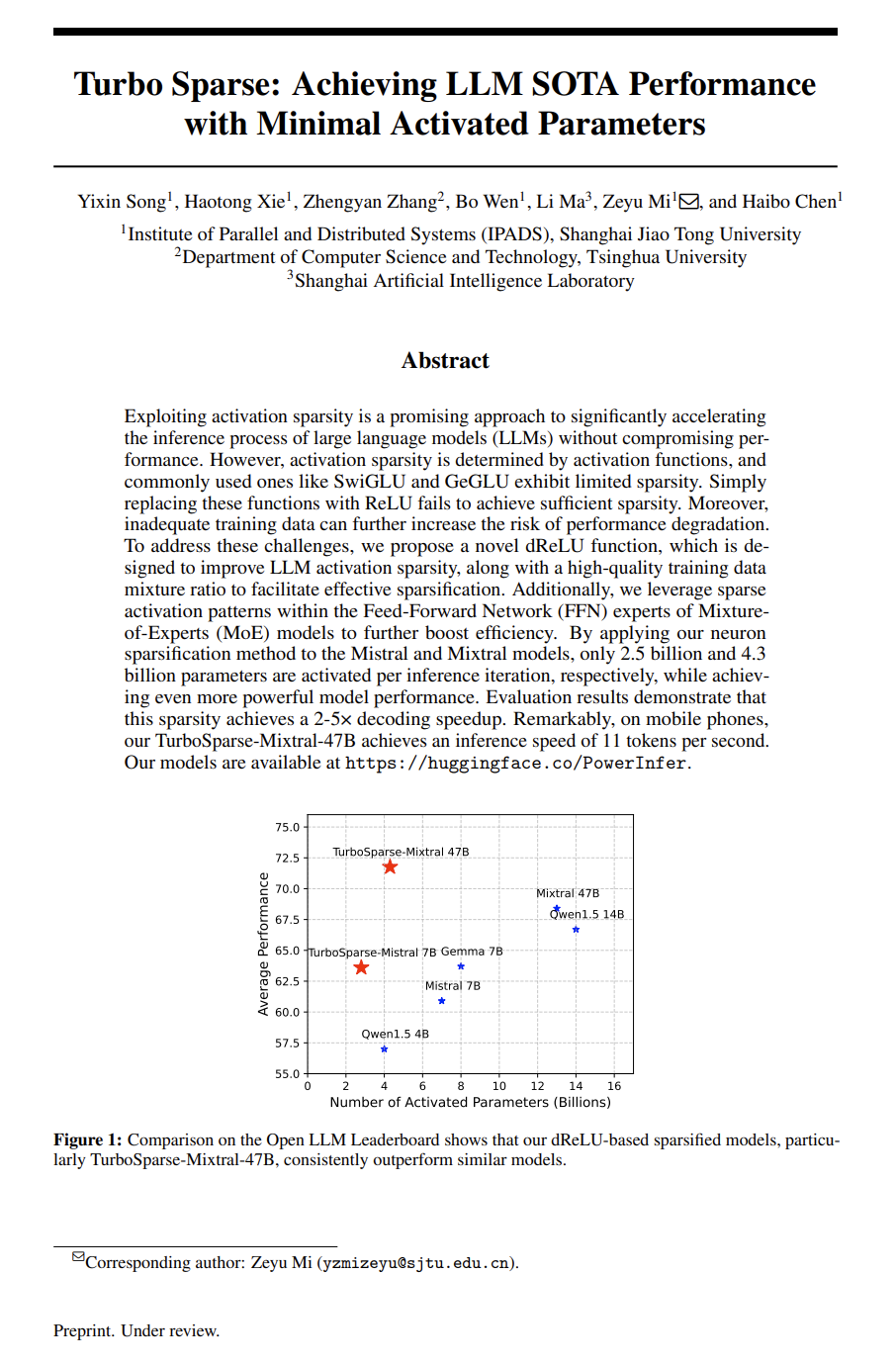 http://arxiv.org/abs/2406.05955v1
http://arxiv.org/abs/2406.05955v1VALL-E 2: 神经编解码语言模型是人类水平的零-shot文本到语音合成器
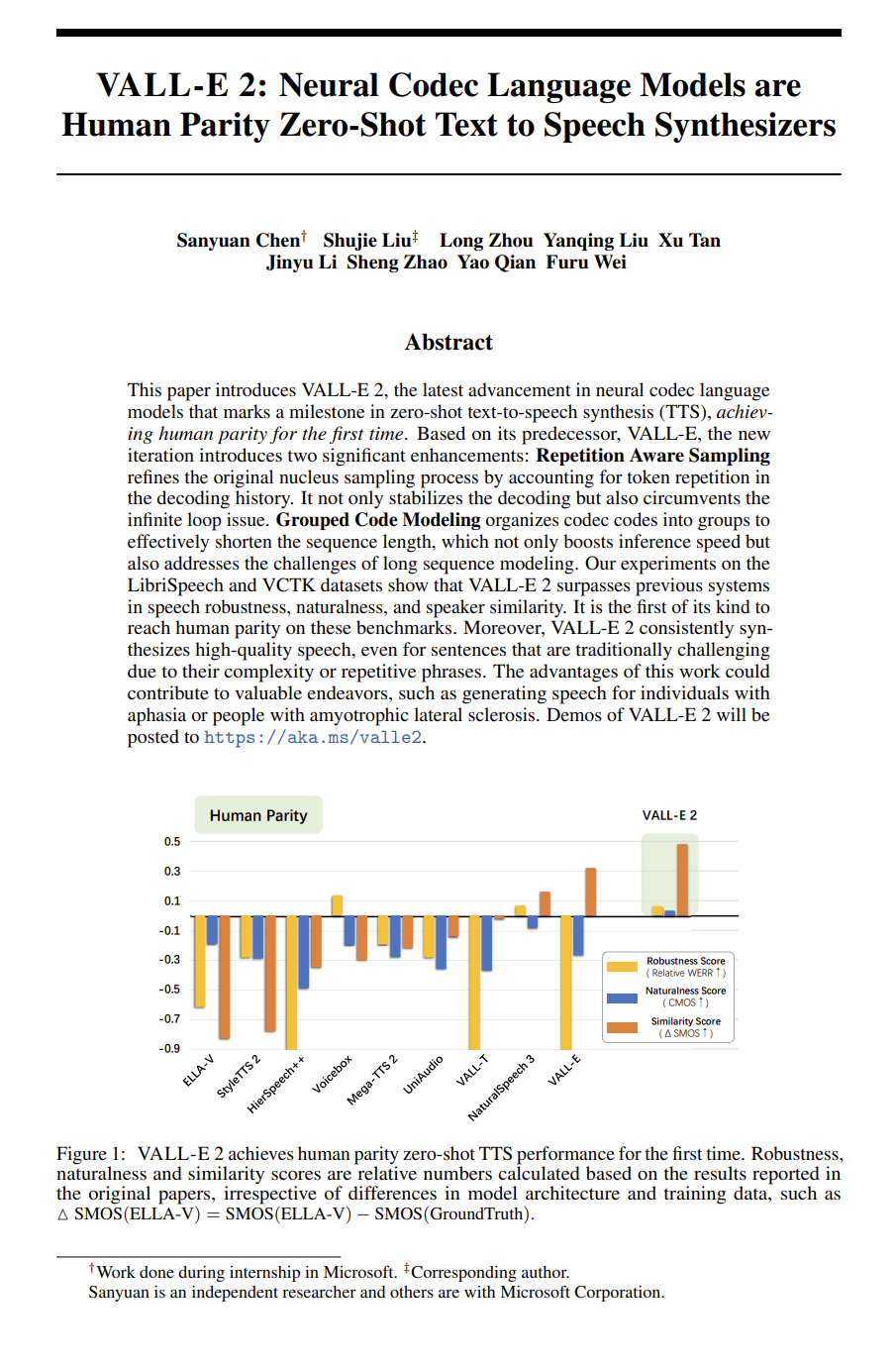 http://arxiv.org/abs/2406.05370v1
http://arxiv.org/abs/2406.05370v1自回归模型战胜扩散:可扩展图像生成的大语言模型
 http://arxiv.org/abs/2406.06525v1
http://arxiv.org/abs/2406.06525v1LeRobot
 https://github.com/huggingface/lerobot
https://github.com/huggingface/lerobotGollama
原创文章,作者:LLM Space,如若转载,请注明出处:https://www.agent-universe.cn/2024/06/14781.html